为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:tidb 4.00
- 【问题描述】:集群下老是莫名同一个tikv会自动重启。
集群信息:tidb * 3 、tikv *4、PD *3
监控上看不出什么异常。tikv和pd报错日志在附件里pd_10_30_4_140_2379.zip (281 字节) tikv_10_30_4_144_20160.zip (819 字节)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1、辛苦提供下 pd-ctl store 信息
2、辛苦提供下异常重启的 tikv 的 run_tikv.sh 脚本内容信息
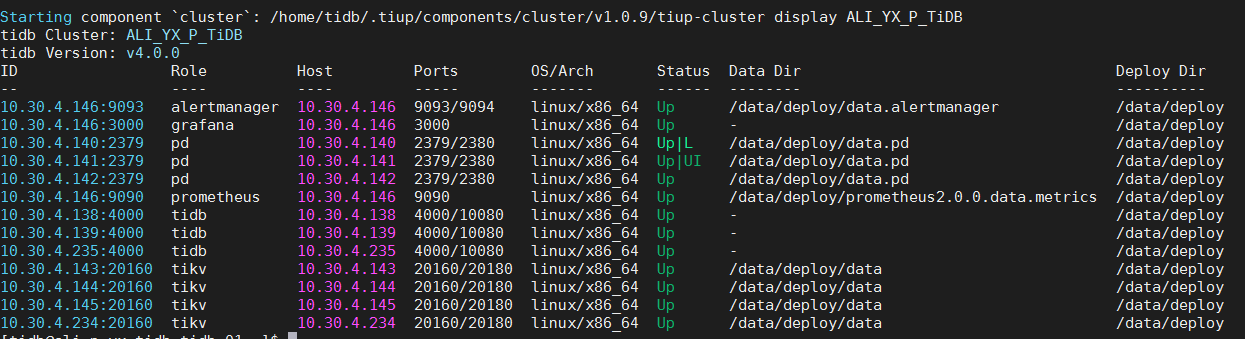
3、如果是 tiup 部署的环境,请 tiup cluster display {cluster_name} 看下集群拓扑
4、异常 tikv 以及 pd leader 的日志 log 信息较少,辛苦提供问题时间点的较为完整的 log 文件,包括 log 以及 sdterr log
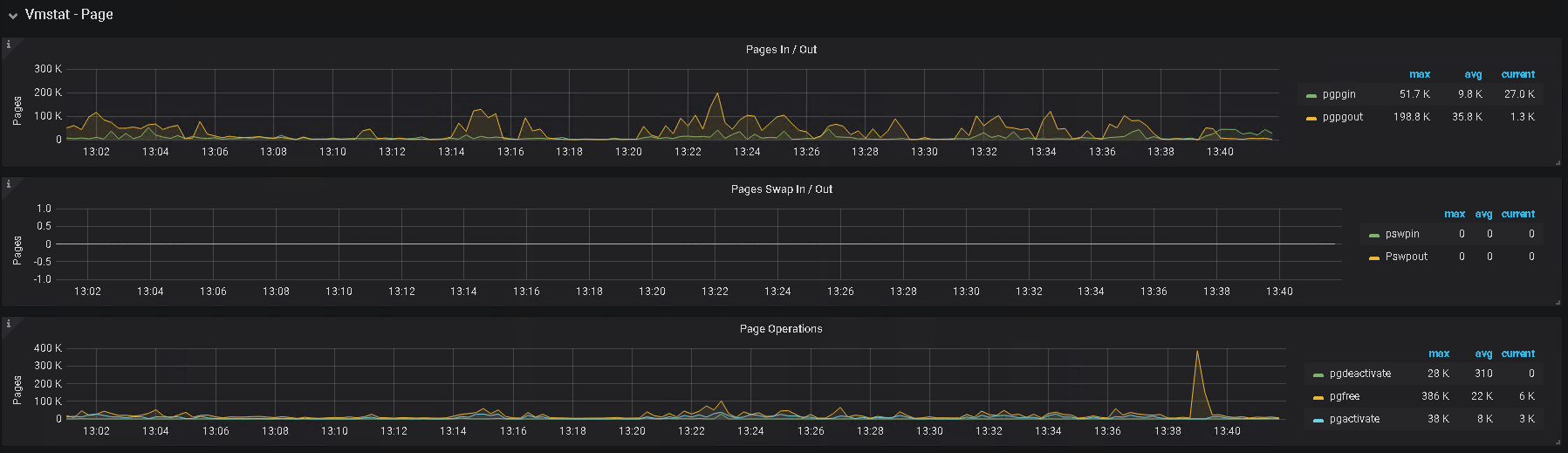
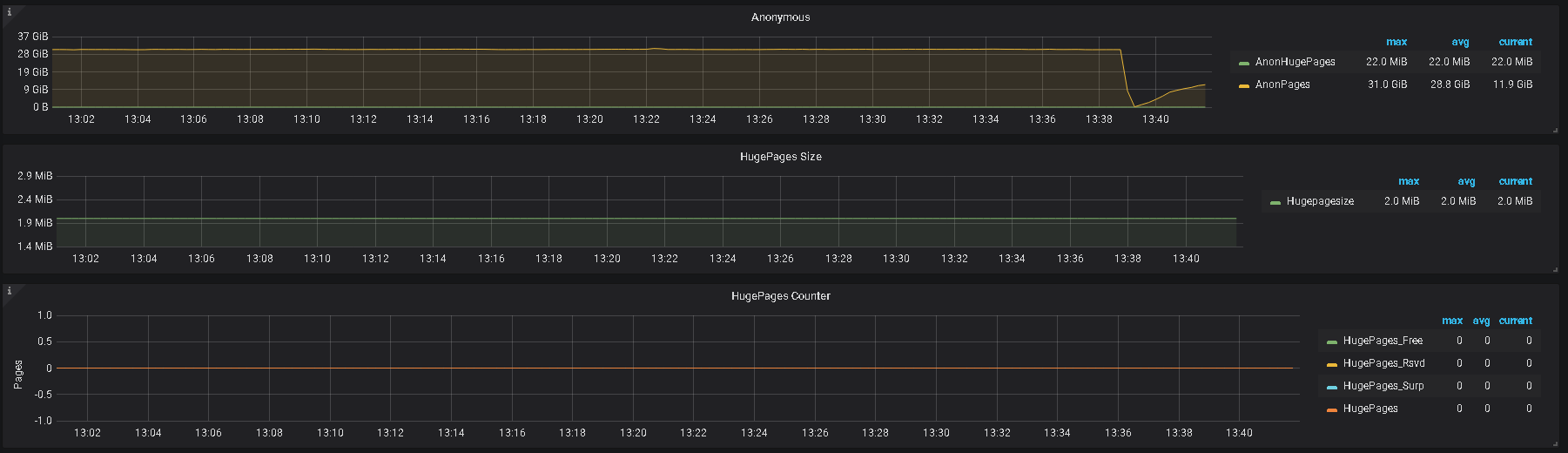
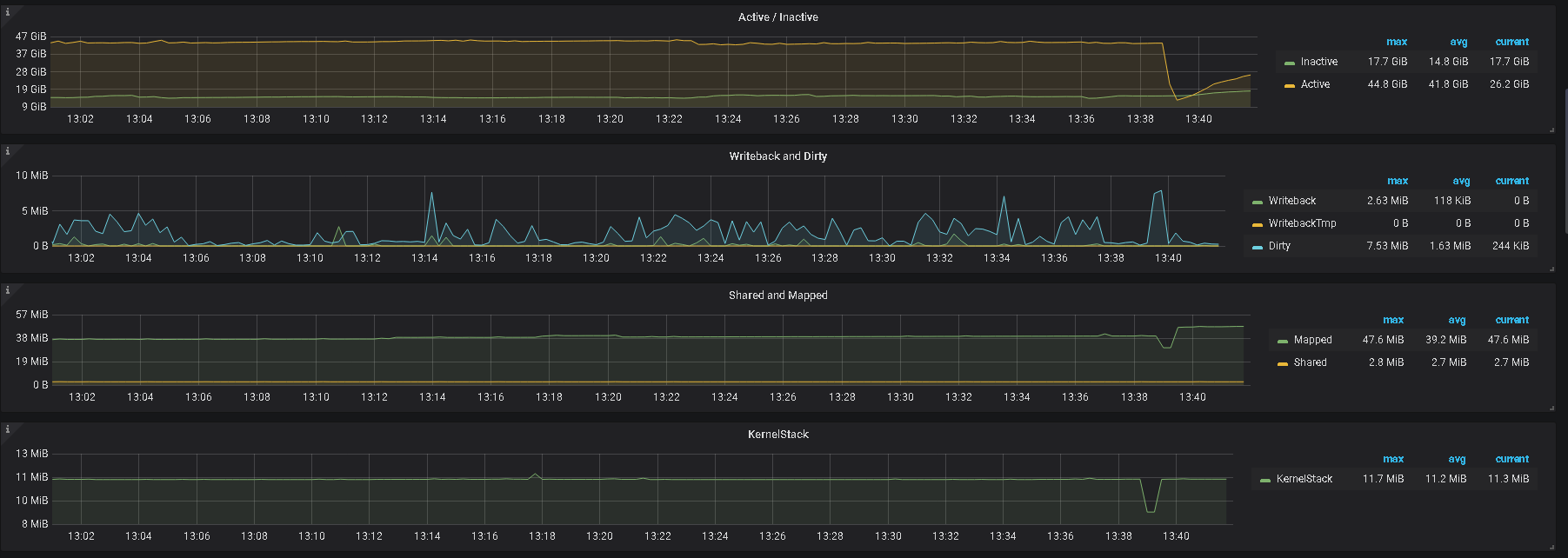
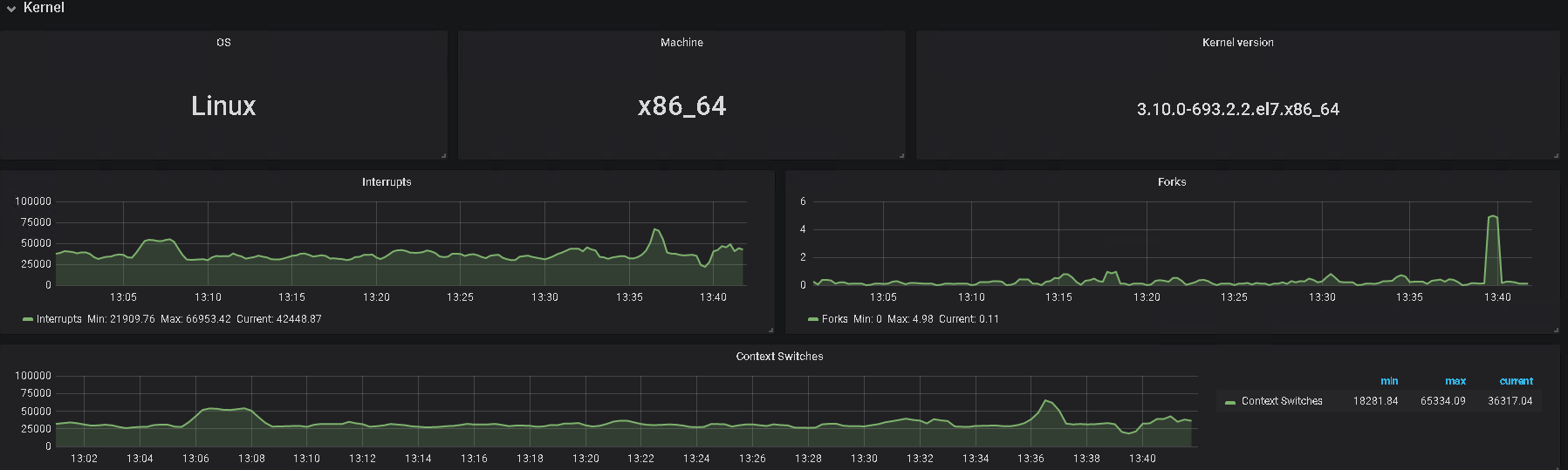
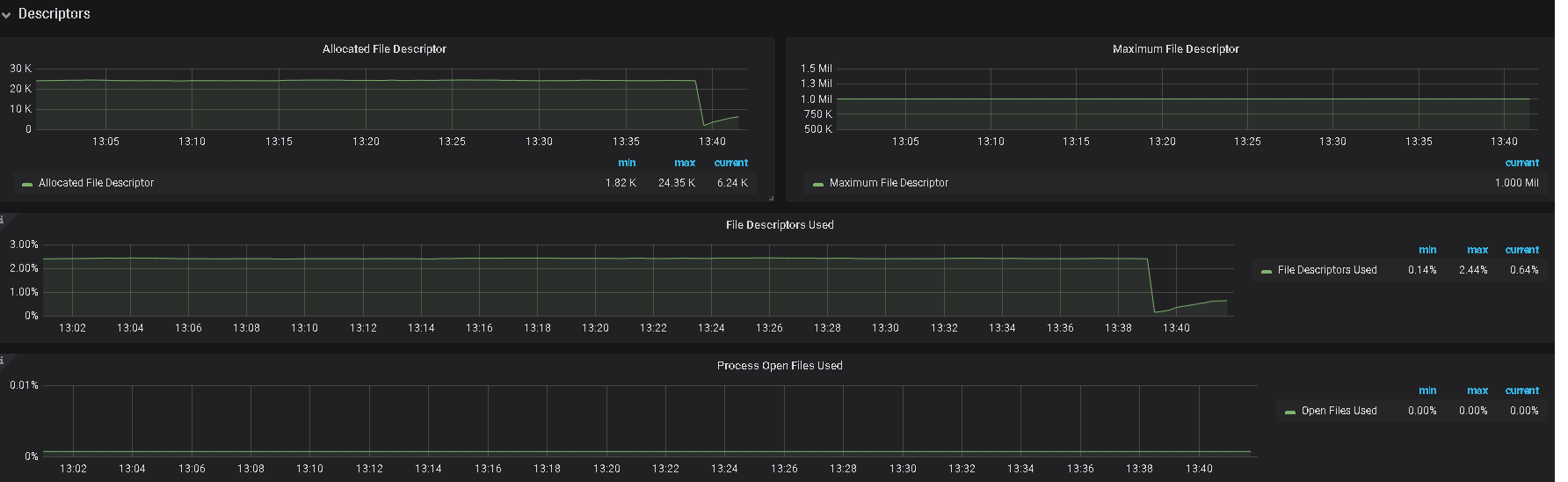
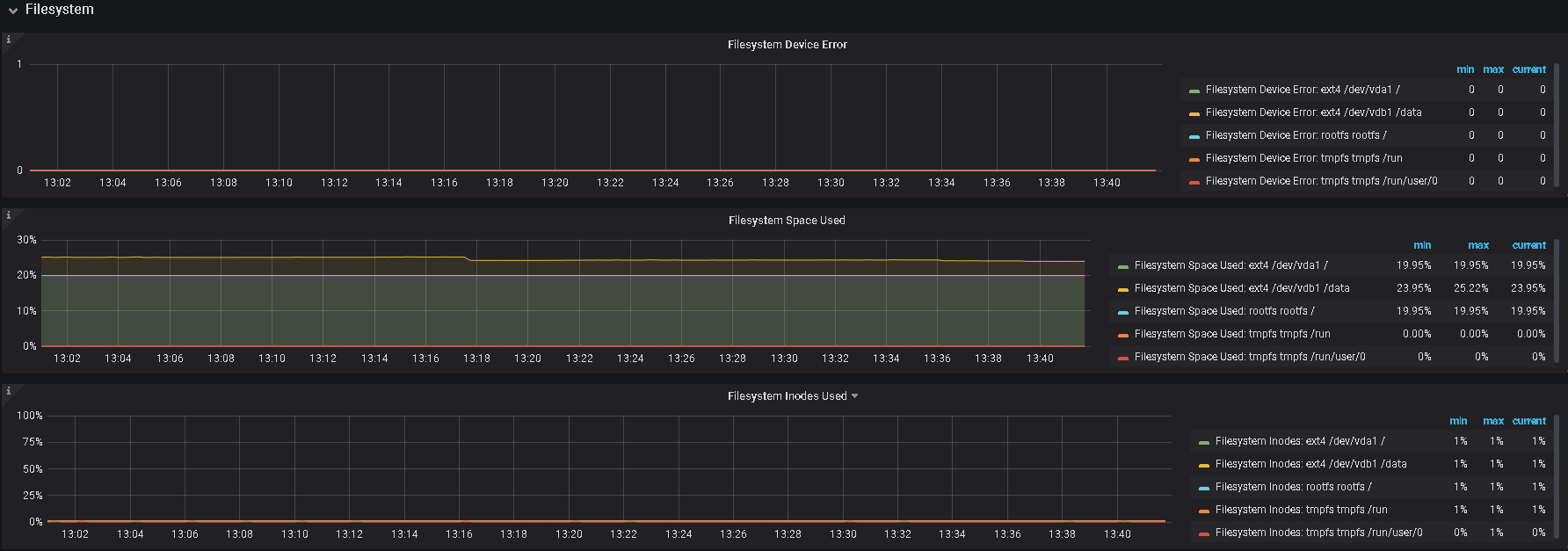
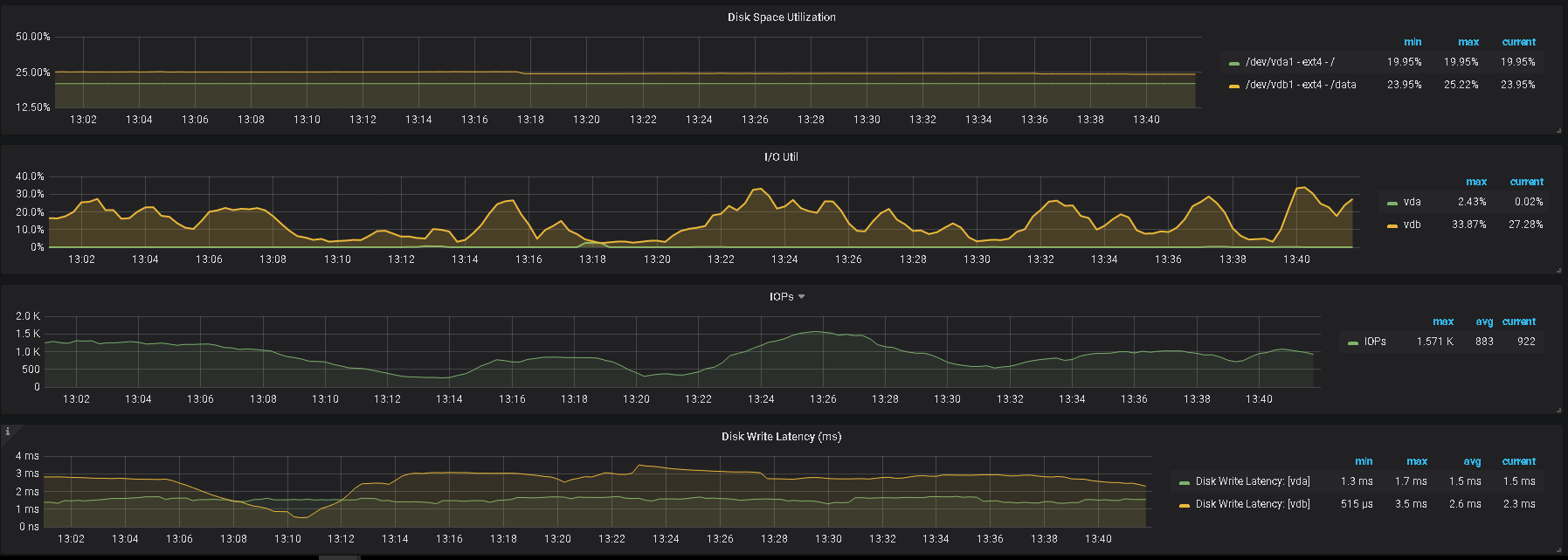
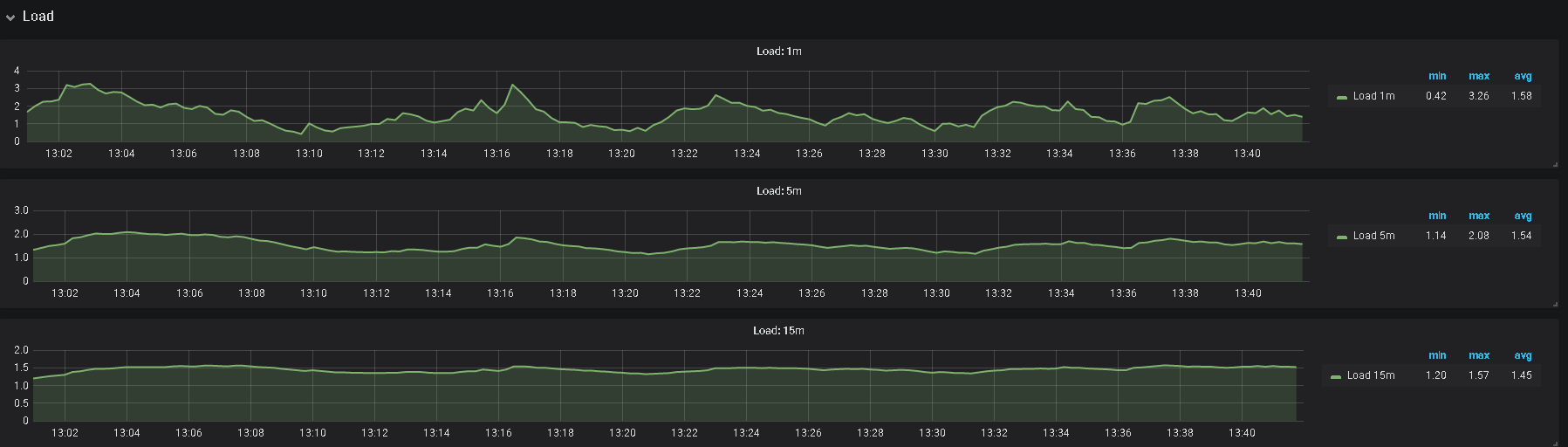
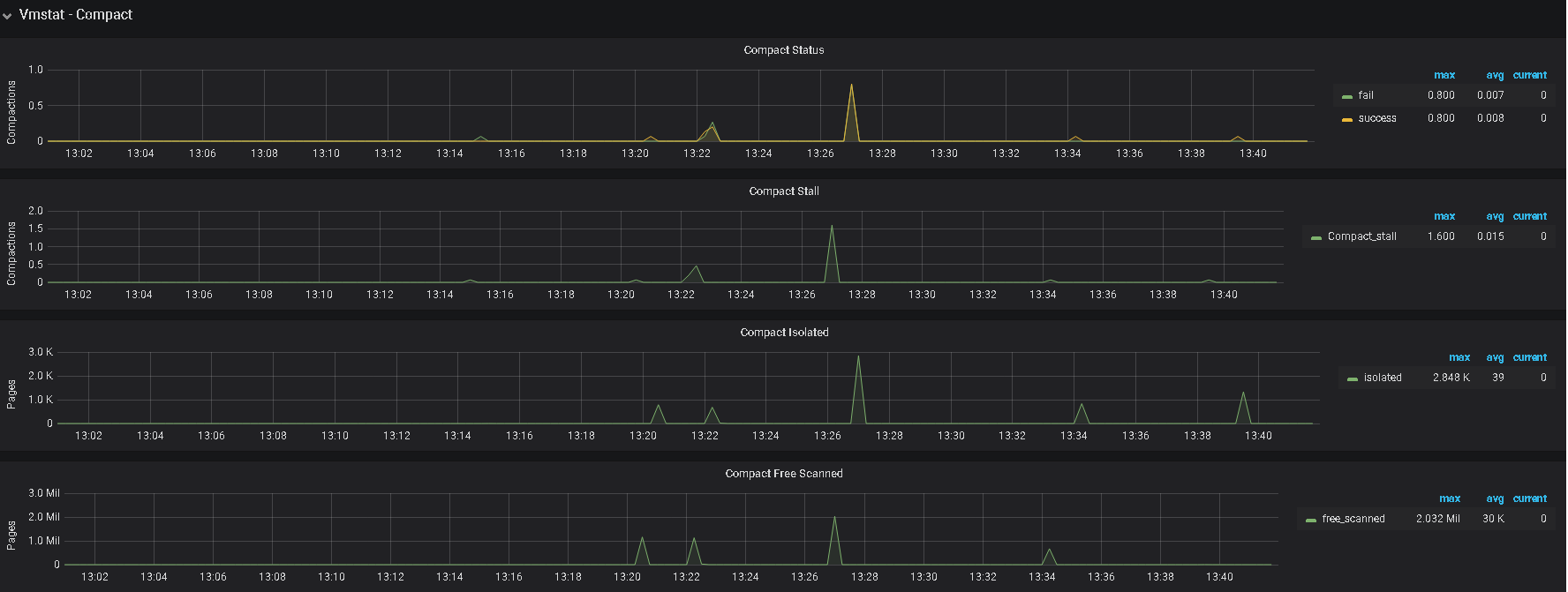
5、辛苦提供下 grafana 监控面板中 tikv-details 的 ERROR 面板的监控 metrics,以及问题 store 的 node-exporter 的 监控信息
您好,pd_stderr和tikv_stderr文件是空的,上传不了到asktug,其他都上传了。还请有空帮忙看一下谢谢!
spc_monkey
(carry@pingcap.com)
6
1、建议看一下这台 tikv 到 pd 的网络情况,监控中有
2、tikv 日志,最好给一下重启之前的日志(目前日志较少),另外,麻烦在该 tikv 服务器上 执行一下如下命令: curl http://xx.xx.xx.140:2379/pd/api/vi/component 这个命令
日志以后补了,打包上传了。请看tikv.7z pd.7z还有你说的 【curl http://xx.xx.xx.140:2379/pd/api/vi/component 】无法运行,报404。对应XXIP我改成 pd 也不行。
1.网络肯定OK的,都是一个内网集群。我看过网络问题,排除网络问题。
2.你给的,【curl http://xx.xx.xx.140:2379/pd/api/vi/component 】应该是v1,不是vi,所以运行失败。我改了一下,运行成功,结果如下:
{
“tikv”: [
“10.30.4.143:20180”,
“10.30.4.144:20180”,
“10.30.4.145:20180”,
“10.30.4.234:20180”
]
}
spc_monkey
(carry@pingcap.com)
9
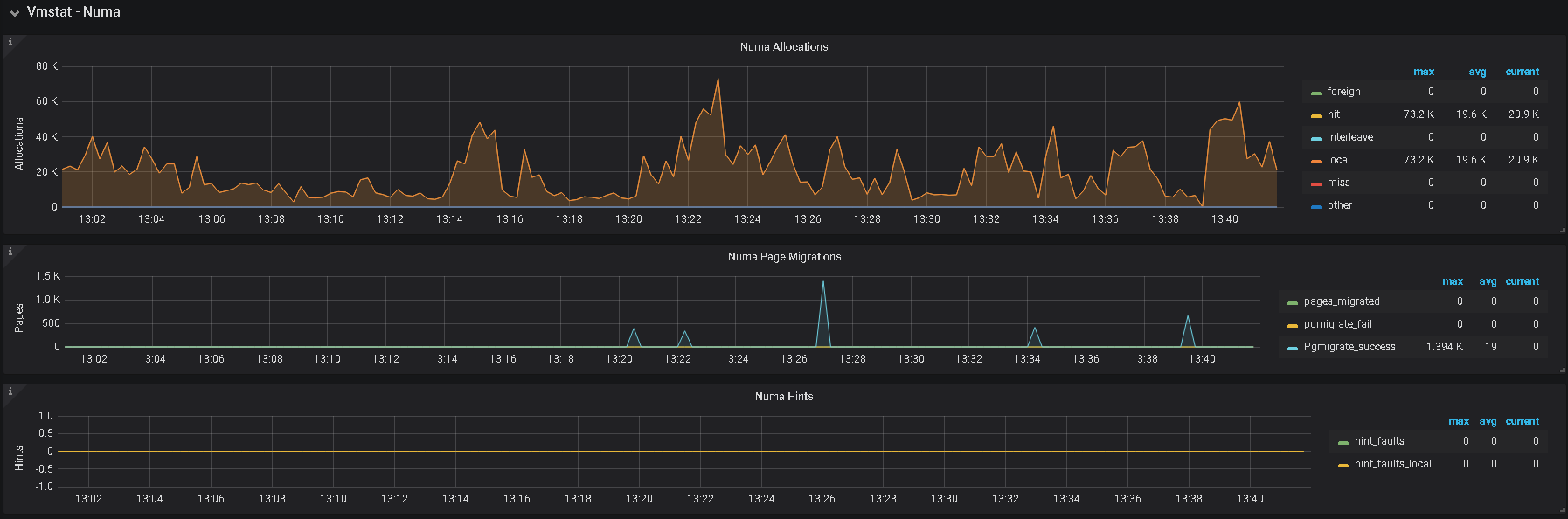
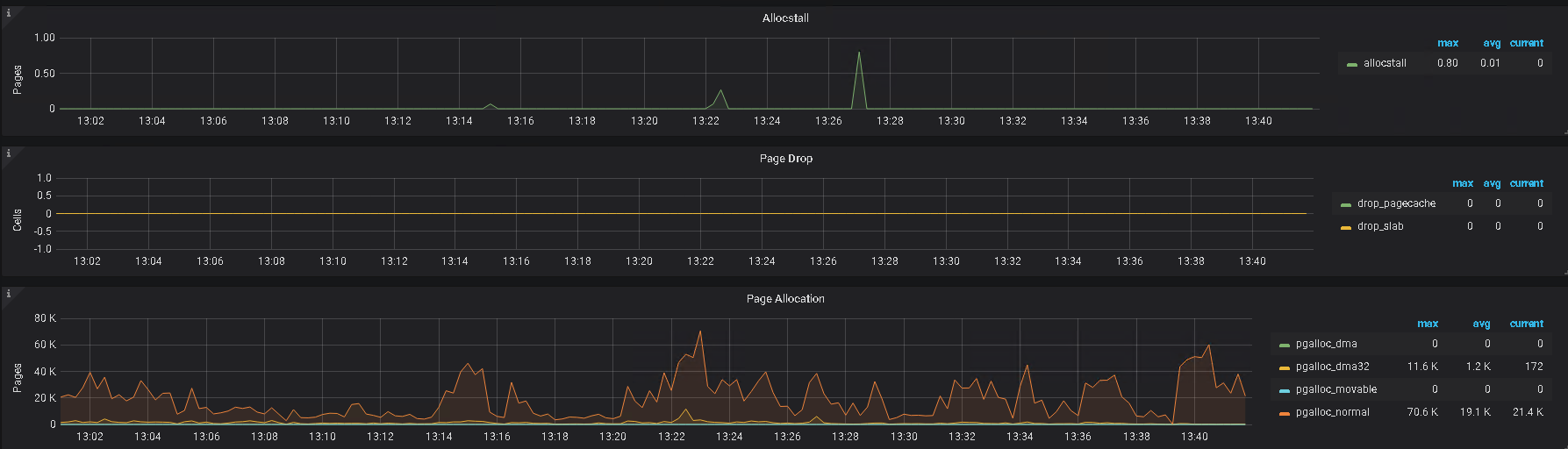
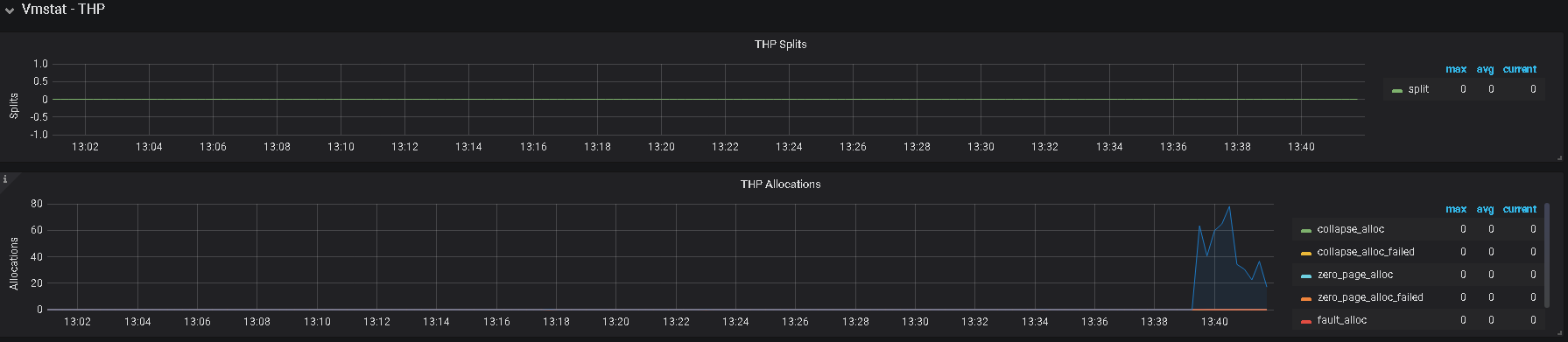
1、建议排查一下是否开启 numa 设置、及 THP 设置
cat /proc/sys/vm/zone_reclaim_mode
0
[bhuser@boohee-tikv01 log]$ cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[bhuser@boohee-tikv01 log]$ cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
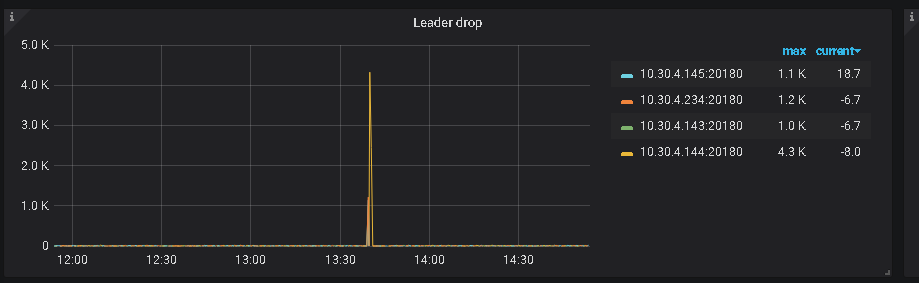
2、另外,帮看一下监控上 该 tikv 的 内存及IO 使用情况
您好,您给的参数我在集群中所有tikv上看过了。查询结果都是一模一样的。感觉应该不是这个参数问题,出问题老是自动重启服务的tikv就是指的的一台,xx.xx.xx.144。且已排查过,出问题之前IO以及内存使用都正常。
spc_monkey
(carry@pingcap.com)
11
1、能把上传的 tikv 日志格式改一下吗,我这边上面的日志看不了
2、另外,帮上传一下启动前 /var/log/message 的内容。
3、监控中有 node—exporter ,里面,对应时间的监控指标信息也帮发一下
messages (64.3 KB) messages-20201025 (109.0 KB) tikv.tar (6.0 MB)
需要的文件
您好,您吩咐的文件,都已经上传了。还请有空在帮忙看看,谢谢
spc_monkey
(carry@pingcap.com)
17
提供的日志内容都是一样的,没有有用信息,不过看现象还是服务器资源不足导致,如果服务器配置充裕,建议还是从上面提到的 numa 及 THP 考虑,如果有限制,可以取消限制,另外,可以看看 overview 里的 内存使用情况,及检查是否有其他程序占用较大内存