为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.7
- 【问题描述】:
我是用TiDB做复杂的SQL的分析,也就是OLAP需求,而且是作为实时数仓用的,所以需要频繁的通过JDBC调用TiDB执行SQL。
但是不管调用是不是频繁,我发现当我停止执行SQL之后,TiDB进程占用的CPU和内存长时间没有及时释放掉。理想状态下是停止执行SQL之后,tidb节点的内存和CPU使用立马降下来才对。
请问
1、为什么停止执行SQL之后,CPU和内存使用率没有立马降下来?底层原因是什么?
停止执行任何SQL好久了,但是CPU和内存还是没有下来,很高。
不再执行任何SQL后,要40分钟,内存全部释放
2、怎么优化?
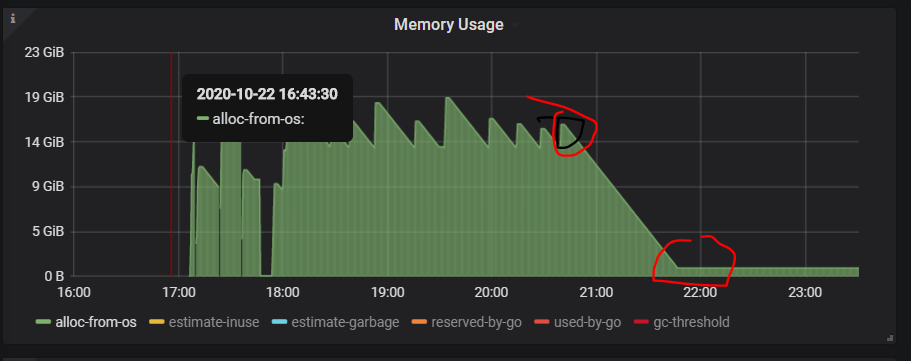
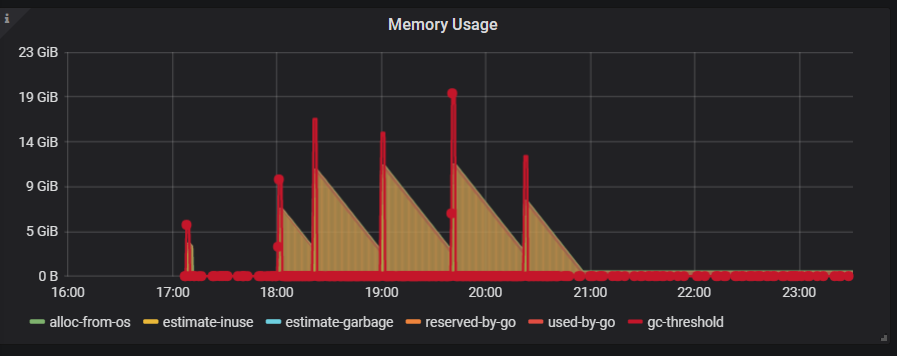
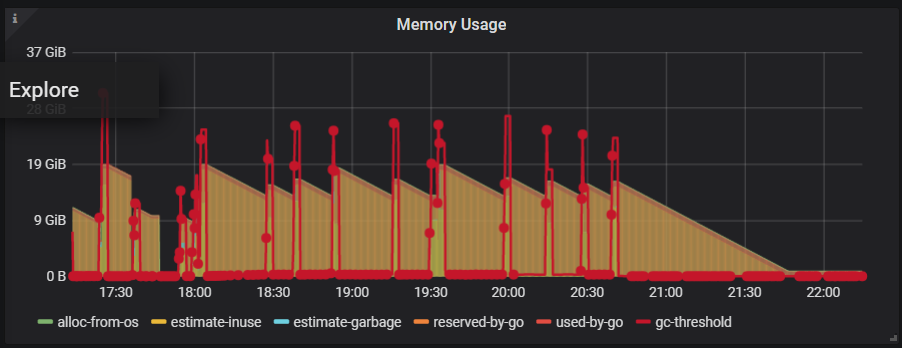
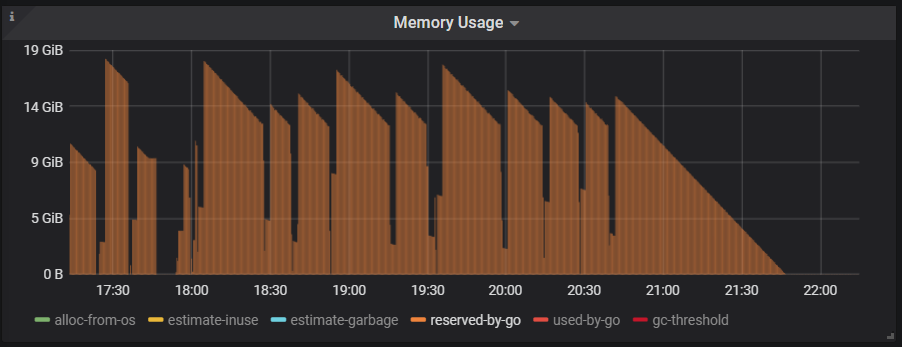
你好,我执行curl -G 没有成功,但是我看了下监控界面,应该是go保留的内存。
(上图是总的tidb节点的内存,下图是仅展示reserved-by-go的内存)
还请问问一下:
如果我有两个jdbc连接了同一个tidb。第一个连接的jdbc,go申请了很多内存,那第二个连接这个tidb节点的jdbc所提交的SQL,还可以利用这部分分配给go的空间来执行第二个JDBC的SQL吗?
也就是不同jdbc连接,可以共用同一份go的空间吗?
yilong
(yi888long)
4
可以通过 tidb 监控 server - memory usage 看“实际占用内存” edit 编辑看看 ( go_memstats_heap_sys_bytes{job=“tidb”} - go_memstats_heap_released_bytes{job=“tidb”}),
理想状态下是停止执行SQL之后,tidb节点的内存和CPU使用立马降下来才对。
Go 的运行时是进行自动内存管理的,也就是通常所说的自动垃圾回收。在这种环境下,内存的释放不一定及时,因为回收器有自己的回收触发策略,用来平衡垃圾回收对性能的影响以及内存占用。就目前的 Go 的默认策略是当内存使用量达到上一次 GC 之后堆大小的两倍或距离上一次 GC 过去了两分钟。
但是我看了下监控界面,应该是go保留的内存。
从监控来看是这样的,这也是 Go 的内存分配器的一个策略。因为触发缺页异常从操作系统分配内存是一个开销比较高的一个操作,所以 Go 会倾向于暂时不归还内存,而是通过一个后台线程每过一段时间归还一小部分。也就是你在监控里看到的这个现象。
如果我有两个jdbc连接了同一个tidb。第一个连接的jdbc,go申请了很多内存,那第二个连接这个tidb节点的jdbc所提交的SQL,还可以利用这部分分配给go的空间来执行第二个JDBC的SQL吗?
这个是会的,准确的来说是这个 TiDB 节点之后所有的内存分配请求都会优先使用这一块保留内存,直到耗尽之后才会再继续向操作系统申请。
1 个赞
请问有没有办法,比如通过设置参数之类的,要求tidb-server更加及时的释放掉内存?
目前没有。如果你在这个机器上只使用 TiDB 不释放内存不会导致 TiDB OOM。如果是想要在闲置不用的时候减少内存占用,可以考虑在不用的时候关闭或者重启 TiDB
哦哦,好的。请问tidb-server从系统申请的内存里面,仅仅是用于分析数据,里面没有缓存热点数据吧?我们基本用不上热点数据,所以想了解下有没有可以进一步优化的地方
我用的都是默认配置,没有额外开启过 tikv-client.copr-cache这个功能。请问默认就是关闭的是吧
还想请教个问题。就是我长时间没使用TiDB之后,突然用TiDB做一下分析,执行复杂SQL。第一次会比较慢,大约10多秒。第二次及以后执行就很快。我没有开启缓存,tikv的缓存空间我也设置为0了,也就是tikv里面没保存热点数据。
请问第一次执行慢的原因,是不是因为第一次执行SQL,需要重新向操作系统申请内存,这步慢了?
yilong
(yi888long)
12
一个帖子请尽量分析一个问题,如果和cpu,内存不释放,建议重新开贴询问 tikv 组件,多谢。
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。