FENG
2020 年10 月 22 日 02:34
1
[2020/10/21 09:26:10.066 +08:00] [WARN] [proxy.go:181] [“fail to recv activity from remote, stay inactive and wait to next checking round”] [remote=0.0.0.0:4000] [interval=2s] [error=“dial tcp 0.0.0.0:4000: connect: connection refused”]
[2020/10/21 09:26:33.668 +08:00] [WARN] [cluster.go:427] [“store does not have enough disk space”] [store-id=1] [capacity=53660876800] [available=2030014464]
报错之后 日志狂增,没多一会,pd和tikv就自动断开,tidb.log日志持续增长,数据库无法访问,请大神指点!
1、部署的方式和架构、当前的版本提供下
1) tidb log
2) tikv log
3) pd log
3、当前环境中有空间不足的提示,建议再拿下 pd-ctl config show all 以及 pd-ctl store 信息
FENG
2020 年10 月 22 日 04:57
3
pd.log (66.4 KB) tikv.log (353.6 KB)
tidb 的log日志 90M 上传失败,以下是tidb.log中一直再写的日志:http://127.0.0.1:2379 ] [error=“error:rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused" target:127.0.0.1:2379 status:TRANSIENT_FAILURE”]http://127.0.0.1:2379 ]”]http://127.0.0.1:2379 ] [error=“error:rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused" target:127.0.0.1:2379 status:TRANSIENT_FAILURE”]http://127.0.0.1:2379 ]”]http://127.0.0.1:2379 ] [error=“error:rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused" target:127.0.0.1:2379 status:TRANSIENT_FAILURE”]http://127.0.0.1:2379 ]”]http://127.0.0.1:2379 ] [error=“error:rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused" target:127.0.0.1:2379 status:TRANSIENT_FAILURE”]http://127.0.0.1:2379 ]”]http://127.0.0.1:2379 ] [error=“error:rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused" target:127.0.0.1:2379 status:TRANSIENT_FAILURE”]http://127.0.0.1:2379 ]”]
目前是在centos中单点部署的模式,版本tidb-v4.0.4-linux-amd64。请大神过目!
1、确认下部署的架构是在一台服务器上同时部署了tidb ,tikv 以及 pd ,节点数量分别是多少 ? tiup cluster edit-config {cluster_name} 上传下当前的配置信息
FENG
2020 年10 月 23 日 00:44
5
单机部署仍然可以使用 tiup 工具,只是在 topology.yaml 文件中,各个组件的数量保持一个即可。另外,将集群 tikv 的 region 副本数调整为 1,对应 pd 的参数为 replication.max-replicas。
https://docs.pingcap.com/zh/tidb/stable/pd-configuration-file#max-replicas
建议使用物理 IP 地址,不要使用回环地址 127.0.0.1。 此部署方式仅适用于测试环境,对高可用没有强需求。生产环境强烈建议安装官方推荐进行部署。
FENG
2020 年10 月 27 日 09:46
9
topology.yaml文件 应该创建在哪个目录下呢?
理论上任意目录都可以,有权限读取即可。为方便管理建议单独建立目录来存放 topo 以及后续的 scale-in 脚本 ~
FENG
2020 年10 月 28 日 10:02
12
建议先看下 debug log 中的具体报错信息 ~
FENG
2020 年10 月 29 日 07:22
16
谢谢大神,安装成功了,但是启动的时候,kitv报错 一直启动失败,请大神指教!
tikv.log (156.8 KB)
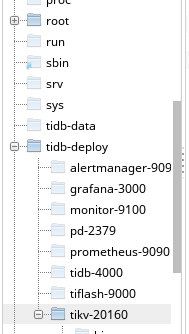
1、tikv 的部署目录是什么?
FENG
2020 年10 月 29 日 10:28
18
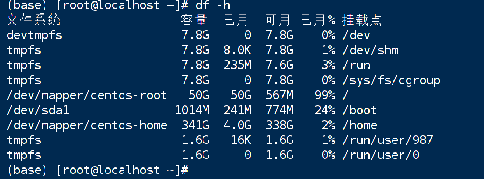
目前默认安装在这个位置,空间使用率centos-root还有567M 是空间不足了吗?
使用率到 99% 了,建议清理下目录再尝试启动看看 ~
FENG
2020 年10 月 30 日 01:02
20
清理出来1.2G的空间 还是启动失败,问题还是一样
建议保持剩余可使用空间在 30%+,如果无法清理,请扩容后再试~