为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v 4.0.7
- 【问题描述】:
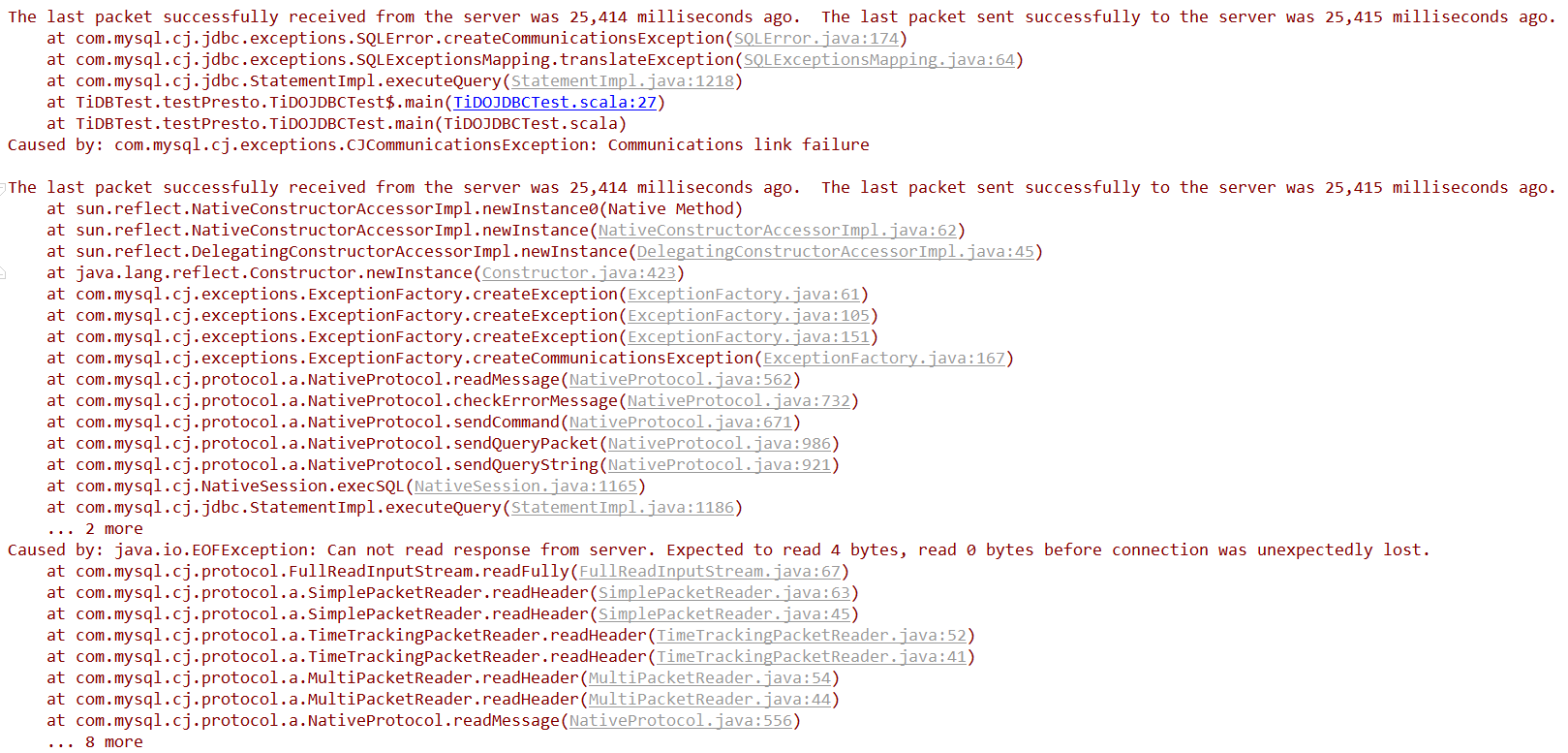
我用JDBC,调用TiDB执行复杂SQL,3台阿里云服务器,SQL 10多秒执行完。我开两个线程连接同一个PD执行同一个SQL,很快PD就会挂掉。如果我两个线程,通过JDBC的url,连接不同的PD的话,就不会挂掉。请问怎么能提高PD的负载能力?
以及PD挂掉的原因是什么?是资源不足吗?通过将PD部署到性能更好的机器上,能彻底解决这个问题吗?我们的TiDB的分析SQL的并发,需要达到每秒100条复杂SQL以上。
我们目前只能用三台节点,同时部署tidb,pd,tikv。最多再加两台机器,请问这种情况下, 有解决办法吗?
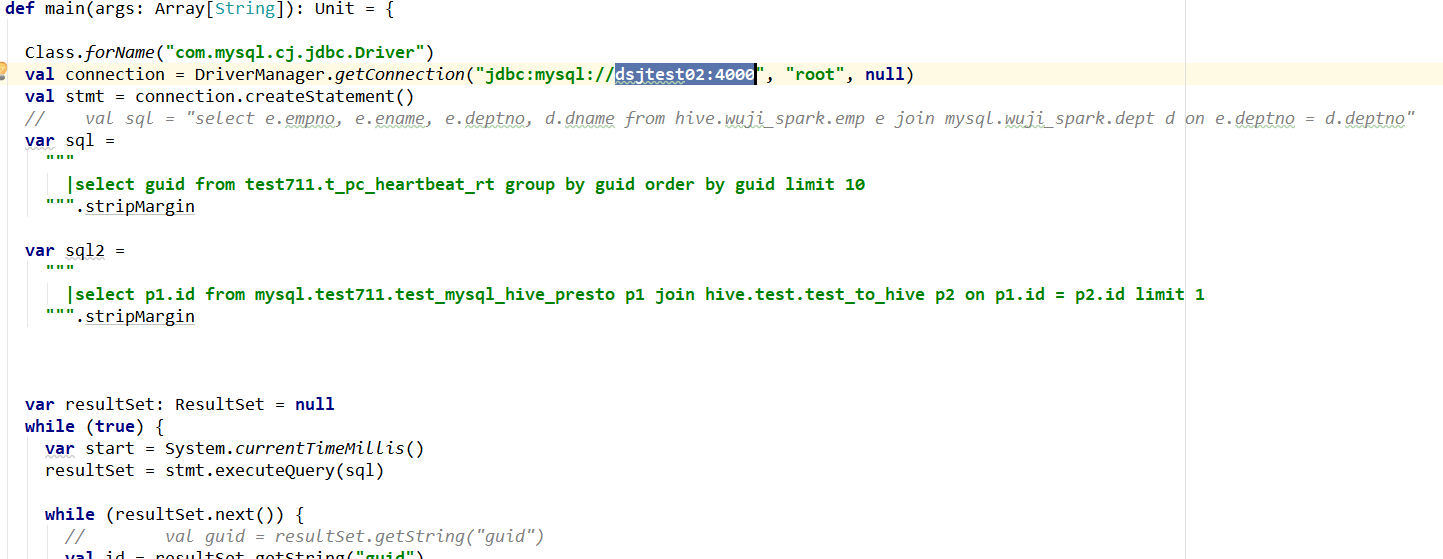
1、我所说的两个线程连接同一个PD的意思是:在这两个线程的连接TiDB的JDBC的URL里面,填写的是同一个主机的地址。
如下:
里面的dsjtest02:4040. 然后把这个程序启动两次。
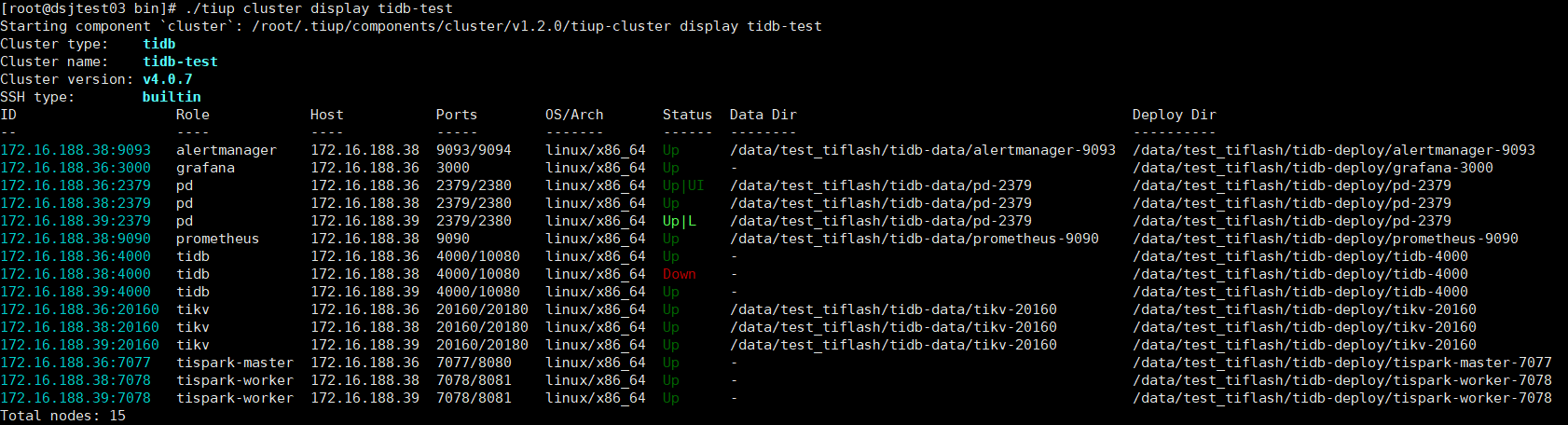
我考虑过是不是锁引起的,所以两次运行之间,SQL修改了一下,执行的是不同的SQL,但是依然会报错,通过tiup cluster display ,发现dsjtest02 的 tidb节点挂了,过不大一小会就自己恢复了,但是程序已经挂了。
2、我同时在生产集群和测试集群试了一下。
测试集群,3台节点,8核32G,执行500w行数据的表的group by order by 的操作,并发达到2就会挂。
生产集群,3台节点,32核128G, 执行同样SQL,并发到15的时候会挂,然后会自动恢复(10个并发的时候,内存使用达到了70多G)。
也就是说,具体会不会挂,和核数还有内存相关。
我试过在9台节点部署TiDB,将TiDB,TiKV,PD分开部署。但是好像是节点间数据传输有点慢,所以好像延迟变高了。