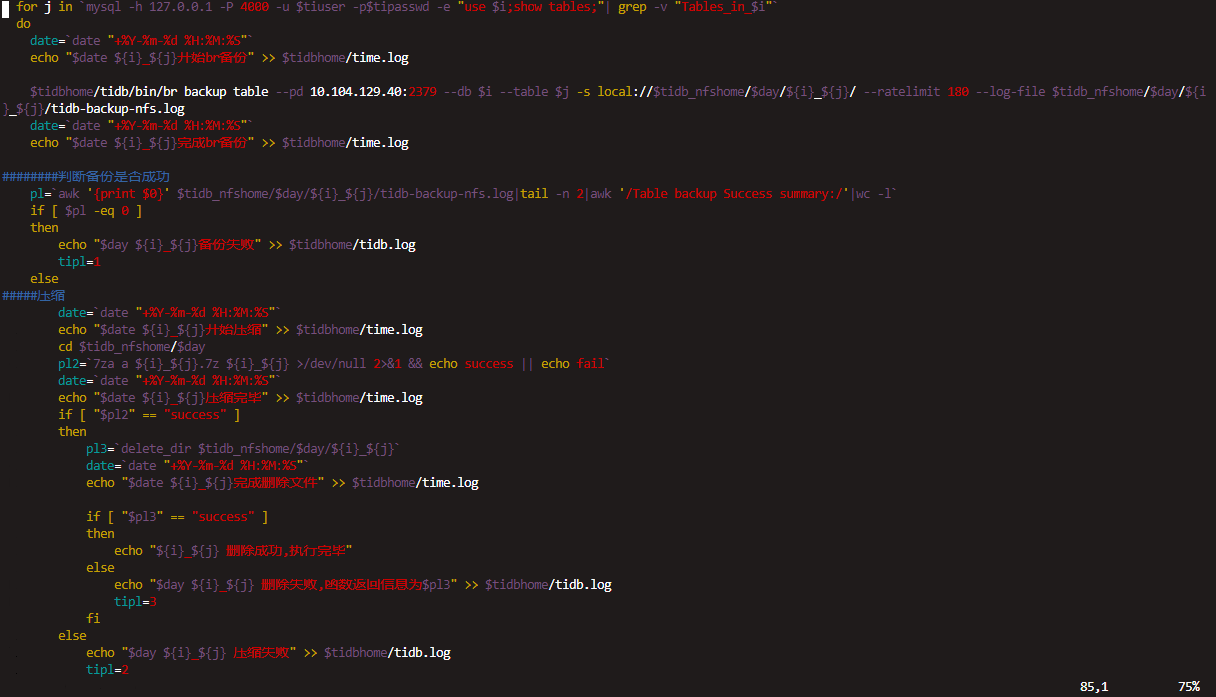
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:之前是4.0.0-rc.2版本最近几天升级到了v4.0.7
- 【问题描述】:我们数据库有2000+的表,我们备份模式是,br循环备份所有的表,一次只备份一张表,发现备份中有2张表备份失败,其他的都正常
错误信息如下图1为备份时输出文件错误,
图2是根据错误信息找到第二个节点/data1/tidb-deploy/pd-2379/log/pd_stderr.log的错误
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1、请检查下在出现问题的时间段,集群的 pd leader 是否发生过切换,上传老 pd 以及新 pd leader 的日志。
2、在备份时,BR 使用的版本也请确认下~
3、BR 备份时是在某个 pd 节点发起的备份命令吗?
说明我们又3个几点,我br备份是连的第一个节点,但是pd 切换是在第二个节点
第一个问题,看了下日志应该有发生切换
第二个问题,br 备份是用的4.0.7,当前集群的版本也是4.0.7
第三个问题,我br备份是连的第一个节点
1、从当前的报错信息可以得到的信息如下:
- PD leader 因为某种原因出现了切换,PD leader 切换的原因建议排查下下面的监控项:
- 原 PD leader 的服务器的 CPU,网络延时,负载,磁盘写延时是否有出现异常
- PD grafana 监控中 ETCD metrics 是否出现异常
- BR 在备份时发现 Leader 切换了,并进行了 try ,但最终 retry 超时
2、如果方便可以提供下 PD 以及 BR 的拓扑,比如 :
- PD 新 leader:{ip:port}
- PD 原 leader:{ip:port}
- BR 所在服务器信息:{ip:port}
3、辛苦整理下下面的信息:
1.我们有3个pd,源pd 估计是seer-1,04:56分的日志信息如下
我查看了seer-1,发现这个时间段cpu 在60%以上,因为我们备份之后还会7z压缩,所以cpu 持续几个小时都比较高
2.新pd leader在seer-2,源pd的leader在seer-1,BR备份是连的seer-1
3.BR备份大概204G,压缩之后160G,我们是基于表备份,因为之前怕br 全量备份包太大不好压缩命令为
1、再确认下 BR 这个工具安装在 pd 原 leader seer-1 上,并且备份也是从 pd 的原 leader seer-1 发起的?
2、请将 pd 原 leader 问题时间段的 grafana 的 node-exporter,pd 监控导出,一起分析下 pd leader 切换的原因
3、在备份开始时,BR 向 pd 获取 tso ,如果失败最大重试次数为 10 次,根据报错信息超时时间也会有差异,故请将新 pd leader 的 log 文件上传下,一起看下重试超时的原因
你好,
1.BR安装在seer-1,备份也是从seer-1发起的,seer-1 就是原leader
2.导出的文件不知道可不可以Tidb-Cluster-Node_exporter-1603193084085.json (229.6 KB)
tidb-seer-PD-1603193144573.json (212.0 KB)
3.seer-1的日志
pd.log (1.7 MB)
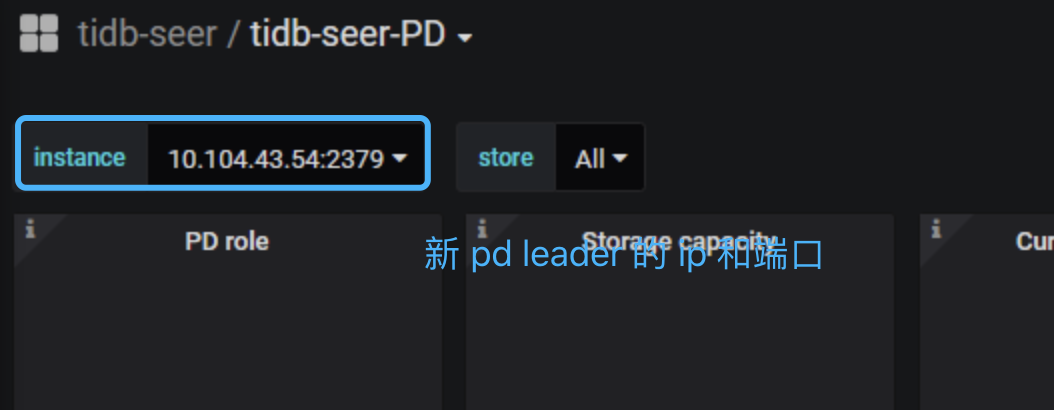
1、导出的两个 json 监控都没有办法打开,辛苦重新导出,并使用 https://metricstool.pingcap.com/ 确认可以正确打开。
另外,在导出 pd grafana 监控面板时,请在 instance 信息处选择新 pd leader 的 ip 端口信息:
2、在 pd seer1 的 log 中发现有下述的日志信息,从信息推断可能是因为原 pd leader seer-1 可能是因为磁盘写入速度太慢,pd 心跳发送超时。建议进一步确认下原 pd leader seer-1 的 grafana 监控中 disk performance 中的磁盘带宽,以及写入延时的 metrics:
[2020/10/20 04:56:19.552 +08:00] [WARN] [wal.go:712] ["slow fdatasync"] [took=3.059447487s] [expected-duration=1s]
[2020/10/20 04:56:19.567 +08:00] [INFO] [raft.go:844] ["c9510e4430b47da4 [logterm: 3, index: 13088194, vote: c9510e4430b47da4] ignored MsgPreVote from 7e50f444e2e8e93b [logterm: 3, index: 13088193] at term 3: lease is not expired (remaining ticks: 2)"]
[2020/10/20 04:56:19.572 +08:00] [INFO] [raft.go:844] ["c9510e4430b47da4 [logterm: 3, index: 13088194, vote: c9510e4430b47da4] ignored MsgVote from 7e50f444e2e8e93b [logterm: 3, index: 13088193] at term 3: lease is not expired (remaining ticks: 2)"]
[2020/10/20 04:56:19.572 +08:00] [WARN] [raft.go:363] ["leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk"] [to=ab8b522f0700fb41] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=2.517468313s]
[2020/10/20 04:56:19.572 +08:00] [WARN] [raft.go:363] ["leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk"] [to=7e50f444e2e8e93b] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=2.517484191s]
[2020/10/20 04:56:19.572 +08:00] [INFO] [raft.go:859] ["c9510e4430b47da4 [term: 3] received a MsgApp message with higher term from 7e50f444e2e8e93b [term: 4]"]
[2020/10/20 04:56:19.572 +08:00] [INFO] [raft.go:700] ["c9510e4430b47da4 became follower at term 4"]
[2020/10/20 04:56:19.572 +08:00] [INFO] [log.go:132] ["found conflict at index 13088194 [existing term: 3, conflicting term: 4]"]
[2020/10/20 04:56:19.572 +08:00] [INFO] [log_unstable.go:129] ["replace the unstable entries from index 13088194"]
[2020/10/20 04:56:19.572 +08:00] [INFO] [node.go:327] ["raft.node: c9510e4430b47da4 changed leader from c9510e4430b47da4 to 7e50f444e2e8e93b at term 4"]
[2020/10/20 04:56:19.574 +08:00] [WARN] [util.go:144] ["apply request took too long"] [took=698.392049ms] [expected-duration=100ms] [prefix="read-only range "] [request="key:\"/topology/tidb/\" range_end:\"/topology/tidb0\" "] [response=] [error="etcdserver: leader changed"]
[2020/10/20 04:56:19.581 +08:00] [INFO] [trace.go:145] ["trace[90260158] range"] [detail="{range_begin:/topology/tidb/; range_end:/topology/tidb0; }"] [duration=705.434264ms] [start=2020/10/20 04:56:18.876 +08:00] [end=2020/10/20 04:56:19.581 +08:00] [steps="[\"trace[90260158] 'agreement among raft nodes before linearized reading' (duration: 698.390203ms)\"]"]
[2020/10/20 04:56:19.575 +08:00] [WARN] [etcd_kv.go:156] ["txn runs too slow"] [response="{\"header\":{\"cluster_id\":9653755028176048402,\"member_id\":14506391560774778276,\"revision\":11304667,\"raft_term\":3},\"succeeded\":true,\"responses\":[{\"Response\":{\"ResponsePut\":{\"header\":{\"revision\":11304667}}}}]}"] [cost=3.079943104s] []
[2020/10/20 04:56:19.581 +08:00] [INFO] [server.go:1173] ["etcd leader changed, resigns leadership"] [old-leader-name=pd-10.104.129.40-2379]
3、上面的跟帖有建议上传新 pd leader seer-2 在问题时间段的 log ,辛苦一并上传下
4、BR 备份使用的是 nfs 挂载网盘,一套 tidb 集群中每个 tikv 均挂载了 nfs 网盘然后发起的备份吧?