为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
Release Version: v2.1.13
Git Commit Hash: 6b5b1a6802f9b8f5a22d8aab24ac80729331e1bc
Git Branch: HEAD
UTC Build Time: 2019-06-21 12:27:08
GoVersion: go version go1.12 linux/amd64
Race Enabled: false
TiKV Min Version: 2.1.0-alpha.1-ff3dd160846b7d1aed9079c389fc188f7f5ea13e
Check Table Before Drop: false
tispark:tispark-core-2.1-SNAPSHOT-jar-with-dependencies.jar
spark:spark-2.3.1-bin-hadoop2.7 - 【问题描述】:
昨天删除掉部分表数据和索引,导致大量spark程序读取数据一直报错“com.pingcap.tikv.exception.TiClientInternalException: Error reading region”“com.pingcap.tikv.exception.RegionTaskException: Handle region task failed”“com.pingcap.tikv.exception.GrpcException: request outdated”,我看垃圾回收比较慢,是该问题导致吗?官方文档和github未找到解决方案,PingCAP的老师方便帮忙看下吗?
spark driver stderr:
========================================
Exception in thread “main” java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.worker.DriverWrapper$.main(DriverWrapper.scala:65)
at org.apache.spark.deploy.worker.DriverWrapper.main(DriverWrapper.scala)
Caused by: java.lang.Exception: java.lang.Exception: java.lang.Exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 10.198.107.64, executor 4): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:147)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList$lzycompute(TiHandleRDD.scala:63)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList(TiHandleRDD.scala:61)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.(TiHandleRDD.scala:77)
at org.apache.spark.sql.tispark.TiHandleRDD.compute(TiHandleRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:142)
… 35 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:185)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: request outdated.
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:588)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:551)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:172)
… 7 more
Driver stacktrace:
at cmcc.gz.mbh.executor.HourPeriodicExecutor.executor(HourPeriodicExecutor.scala:60)
at cmcc.gz.mbh.executor.HourPeriodicExecutor$.main(HourPeriodicExecutor.scala:70)
at cmcc.gz.mbh.executor.HourPeriodicExecutor.main(HourPeriodicExecutor.scala)
… 6 more
Caused by: java.lang.Exception: java.lang.Exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 10.198.107.64, executor 4): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:147)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList$lzycompute(TiHandleRDD.scala:63)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList(TiHandleRDD.scala:61)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.(TiHandleRDD.scala:77)
at org.apache.spark.sql.tispark.TiHandleRDD.compute(TiHandleRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:142)
… 35 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:185)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: request outdated.
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:588)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:551)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:172)
… 7 more
Driver stacktrace:
at cmcc.gz.mbh.login.LoginTaskServer$class.saveAndReturnDF(LoginTaskServer.scala:163)
at cmcc.gz.mbh.login.LoginHour.saveAndReturnDF(LoginHour.scala:10)
at cmcc.gz.mbh.executor.HourPeriodicExecutor.executor(HourPeriodicExecutor.scala:23)
… 8 more
Caused by: java.lang.Exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 10.198.107.64, executor 4): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:147)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList$lzycompute(TiHandleRDD.scala:63)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList(TiHandleRDD.scala:61)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.(TiHandleRDD.scala:77)
at org.apache.spark.sql.tispark.TiHandleRDD.compute(TiHandleRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:142)
… 35 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:185)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: request outdated.
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:588)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:551)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:172)
… 7 more
Driver stacktrace:
at cmcc.gz.mbh.login.LoginTaskServer$class.saveDF(LoginTaskServer.scala:150)
at cmcc.gz.mbh.login.LoginHour.saveDF(LoginHour.scala:73)
at cmcc.gz.mbh.login.LoginTaskServer$class.saveAndReturnDF(LoginTaskServer.scala:160)
… 10 more
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 10.198.107.64, executor 4): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:147)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList$lzycompute(TiHandleRDD.scala:63)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList(TiHandleRDD.scala:61)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.(TiHandleRDD.scala:77)
at org.apache.spark.sql.tispark.TiHandleRDD.compute(TiHandleRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:142)
… 35 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:185)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: request outdated.
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:588)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:551)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:172)
… 7 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1602)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1590)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1589)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1589)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1823)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1772)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1761)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2034)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2055)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2074)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2099)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:929)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:927)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:927)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.saveTable(JdbcUtils.scala:821)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:83)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:654)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:654)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:654)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:273)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:267)
at org.apache.spark.sql.DataFrameWriter.jdbc(DataFrameWriter.scala:499)
at cmcc.gz.mbh.login.LoginTaskServer$class.saveDF(LoginTaskServer.scala:147)
… 12 more
Caused by: com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:147)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList$lzycompute(TiHandleRDD.scala:63)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.handleList(TiHandleRDD.scala:61)
at org.apache.spark.sql.tispark.TiHandleRDD$$anon$2.(TiHandleRDD.scala:77)
at org.apache.spark.sql.tispark.TiHandleRDD.compute(TiHandleRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:142)
… 35 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:185)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: request outdated.
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:588)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:551)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.jav
gc:
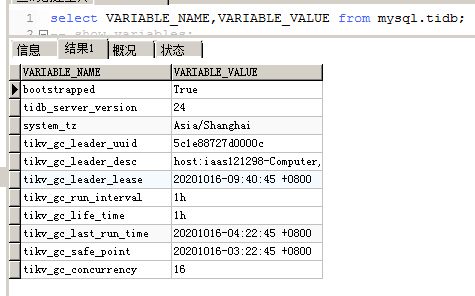
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。