为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0
- 【问题描述】:
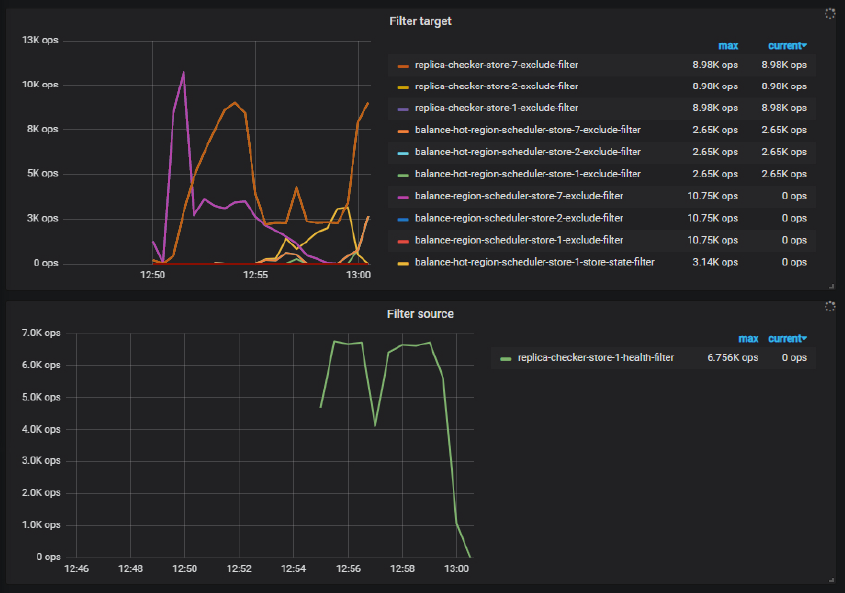
Grafana中,pd-scheduler-filter source中一直存在replica-checker-store-1-health-filter一项,同时store1在运行过程中把大量leader迁移到了其他store。请问什么原因会导致replica-checker-store-1-health-filter呢?
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
Grafana中,pd-scheduler-filter source中一直存在replica-checker-store-1-health-filter一项,同时store1在运行过程中把大量leader迁移到了其他store。请问什么原因会导致replica-checker-store-1-health-filter呢?
1、store 1 上的 leader 大量的迁移至其他 store 可能是 store 1 当前比较繁忙,处于非健康状态。replica-checker-store-1-health-filter 的趋势也能从侧面反映这个问题。关于大量的从 store 1 中将 leader 迁移走可能是 store 本身负载比较高,网络通信等问题导致。具体可以查看下 pd leader 的 log 日志,tikv-details 的监控,看下是否能找到有效的信息~~
2、filter soure 面板的说明建议查阅官方文档:
https://docs.pingcap.com/zh/tidb/stable/grafana-pd-dashboard#scheduler
但是leader是从store1迁走的,为什么显示的store1是filter source呢?
存在 leader 从 store1 transfer 到其他节点的现象,建议从 pd leader 的 log 日志,tikv-details 的监控,看下是否能找到有效的信息。
而 replica-checker-store-1-health-filter 的趋势只是侧面反映出这个 store1 可能状态是有异常的,当 store1 作为 source 时,在进行 replica-checker 的时候,被过滤掉了。
replica-checker-store-1-health-filter 这个监控项本身和 transfer leader 的这个现象不是强关联关系。
日志中有类似这种内容:
[2020/10/15 13:07:59.017 +00:00] [INFO] [cluster.go:499] [“leader changed”] [region-id=54] [from=1] [to=2]
但也没发现更详细的信息(比如change的具体原因)。请问如何发现更多线索呢?
store1 掉 leader,建议看下 pd 到这个 store1 的网络通信情况,以及 store1 本身的情况比如负载,tikv-details 的 grafana 中 store1 的相关 metrics ~~
被 healthFilter 过滤掉有两种情况,1是tikv报busy 2是30分钟以上未上报心跳。这里看起来应该是有busy的情况,可以在TiKV页面确认下是否有busy的情况,以及busy的原因。
看了下server is busy一直是空的…cpu, memory这些metric也没有发现异常
请问server is busy都会监控哪些metric呢?
1、查看问题时间段的 tikv-details → Error 监控面板整版的内容
2、如果方便,请根据下面的方式将问题时间段 12:30 ~ 13:30 的 tikv-details 以及 pd ,store1 的 node-exporter 监控导出:
可以的
mytidb-TiKV-Details_2020-10-20T08_41_15.031Z.json (1.5 MB) Tidb-Cluster-Node_exporter_2020-10-20T08_41_56.087Z.json (447.3 KB) mytidb-PD_2020-10-20T08_40_47.633Z.json (407.0 KB)
1、当前是在做压测,并且使用的 rawkv 吗?
2、上传的 tikv 、pd 以及 node-exporter 的监控的时间段为 10 月 20 号 16:15 ~ 16:30 左右的时间段,并非上述截图中的 03:20 ~ 03:26
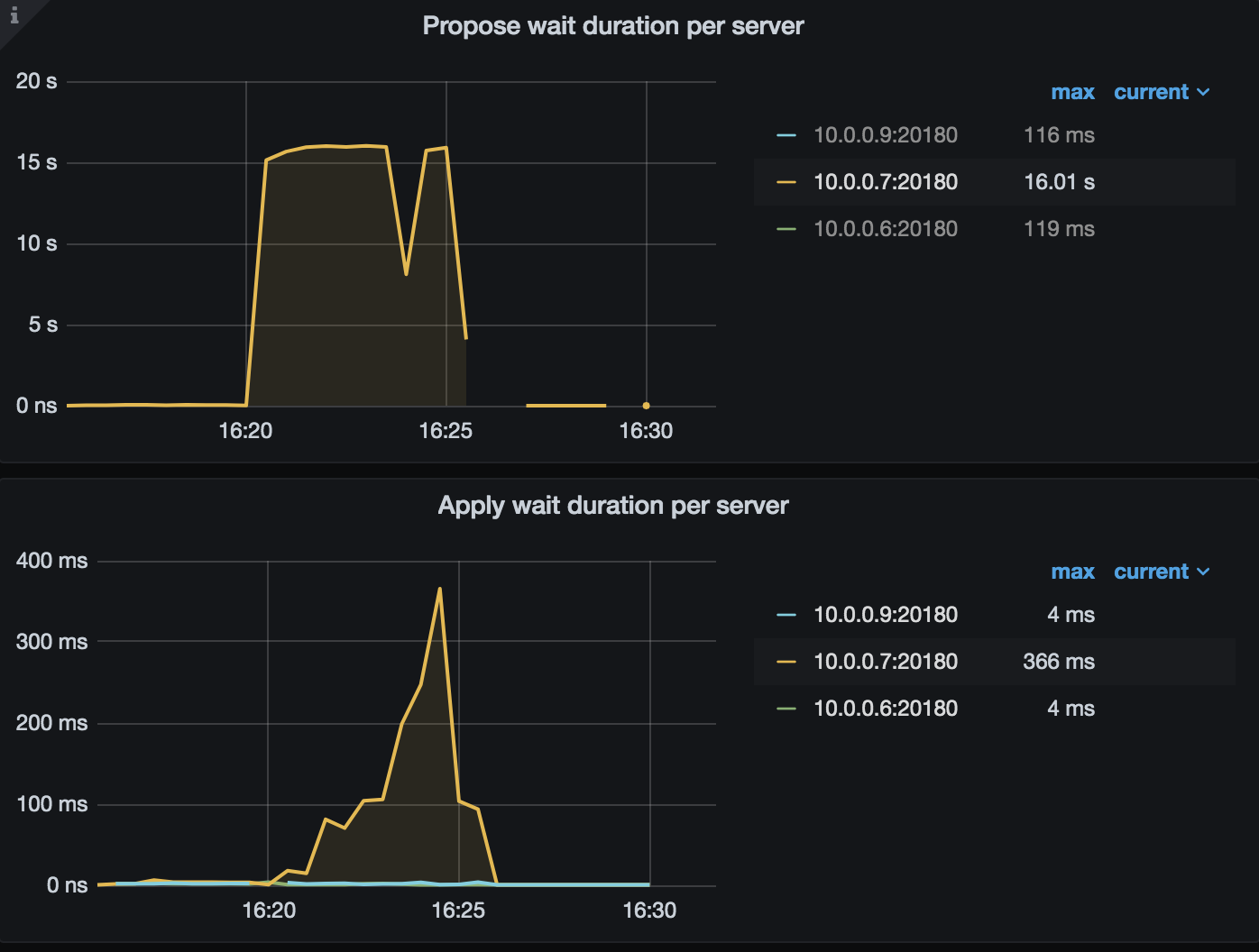
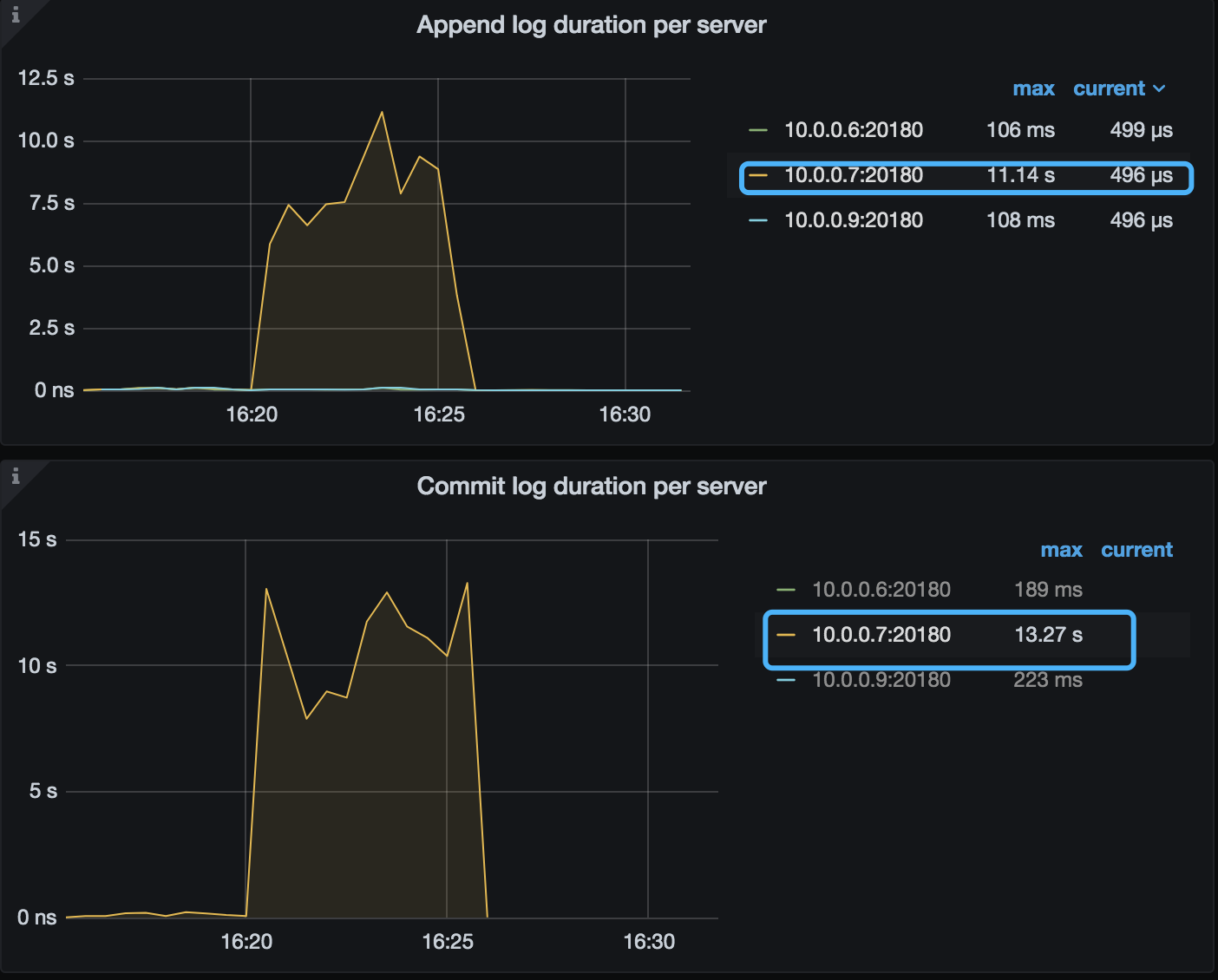
3、从已上传的监控信息可见,在 10月20 号 16:15 ~ 16:30 左右的监控中可以看到下面的信息 10.0.0.7:20160-store-1 的写入相关的指标,包括 commit log duration,propose wait,apply duration 都高于其他 store。建议检查下 10.0.0.7:20160-store-1 的 node-exporter 监控的 write latency 相关的指标。
4、某些指标也显示在压测期间 10.0.0.7:20160-store-1 处理数据的流量可能是高于其他 store,建议确认下业务行为是否有差异
5、压测时间段的 10.0.0.7:20160-store-1 的 tikv log 辛苦上传下
1、当前是在做压测,并且使用的 rawkv 吗? 对的
2、上传的 tikv 、pd 以及 node-exporter 的监控的时间段为 10 月 20 号 16:15 ~ 16:30 左右的时间段,并非上述截图中的 03:20 ~ 03:26 这个可能是服务器时区不一样![]()
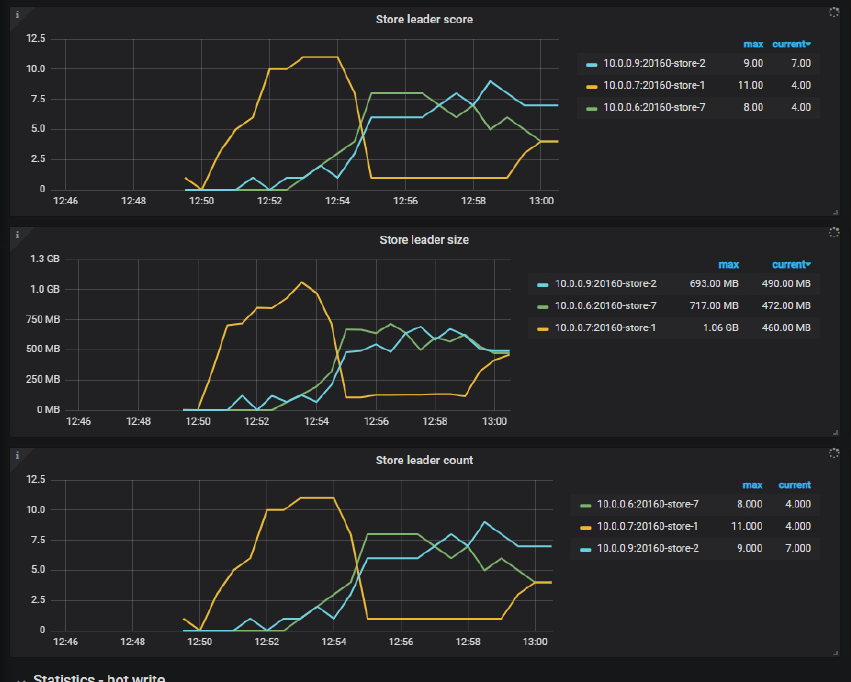
4、某些指标也显示在压测期间 10.0.0.7:20160-store-1 处理数据的流量可能是高于其他 store,建议确认下业务行为是否有差异 10.0.0.7一开始region leader比较多,这可能是流量大的原因?
下面的信息也请提供下,这里再分析看下:
3、从已上传的监控信息可见,在 10月20 号 16:15 ~ 16:30 左右的监控中可以看到下面的信息 10.0.0.7:20160-store-1 的写入相关的指标,包括 commit log duration,propose wait,apply duration 都高于其他 store。建议检查下 10.0.0.7:20160-store-1 的 node-exporter 监控的 write latency 相关的指标。
5、压测时间段的 10.0.0.7:20160-store-1 的 tikv log 辛苦上传下
之前的log被覆盖掉了,我试着重新复现了下问题。
看了下 10.0.0.7:20160-store-1 出问题时段的write latency确实比其他节点高了不少(2s VS 20-30ms)。这个会导致节点状态变成unhealthy吗?tikv和pd的源码中好像没搜到监控disk latency的代码段,而是根据heartbeat响应是否超时来决定的
mytidb-PD_2020-10-26T10_36_19.368Z.json (471.7 KB) mytidb-TiKV-Details_2020-10-26T10_39_25.805Z.json (1.7 MB) Tidb-Cluster-Node_exporter_2020-10-26T10_37_57.922Z_10.0.0.7.json (504.1 KB) Tidb-Cluster-Node_exporter_2020-10-26T10_38_39.088Z_10.0.0.6.json (514.3 KB) Tidb-Cluster-Node_exporter_2020-10-26T10_39_07.408Z_10.0.0.9.json (507.3 KB) 10.0.0.7_tikv.log (206.8 KB)
1、在 tikv 中 raft 心跳是通过 raftstore 发送的,raftstore 发送的 raftlog 信息需要落盘,当磁盘出现卡顿时,心跳会因为发送不出去,而触发 raft 选举。
https://docs.pingcap.com/zh/tidb/stable/massive-regions-best-practices#raftstore-的工作流程
2、建议确认下 store-1 的服务器磁盘性能,当前服务器使用的是 SSD 还是 Nvme ?以及是否存在流量不均衡的情况,比如 store-1 承担的流量明显多于其他 store ~
好的 谢谢~
1、在 tikv 中 raft 心跳是通过 raftstore 发送的,raftstore 发送的 raftlog 信息需要落盘,当磁盘出现卡顿时,心跳会因为发送不出去,而触发 raft 选举。
心跳发不出去会在log或者grafana里有记录吗?
磁盘用的全都是SSD。store1一开始ycsb load阶段的流量就比较多(region leader也多)。
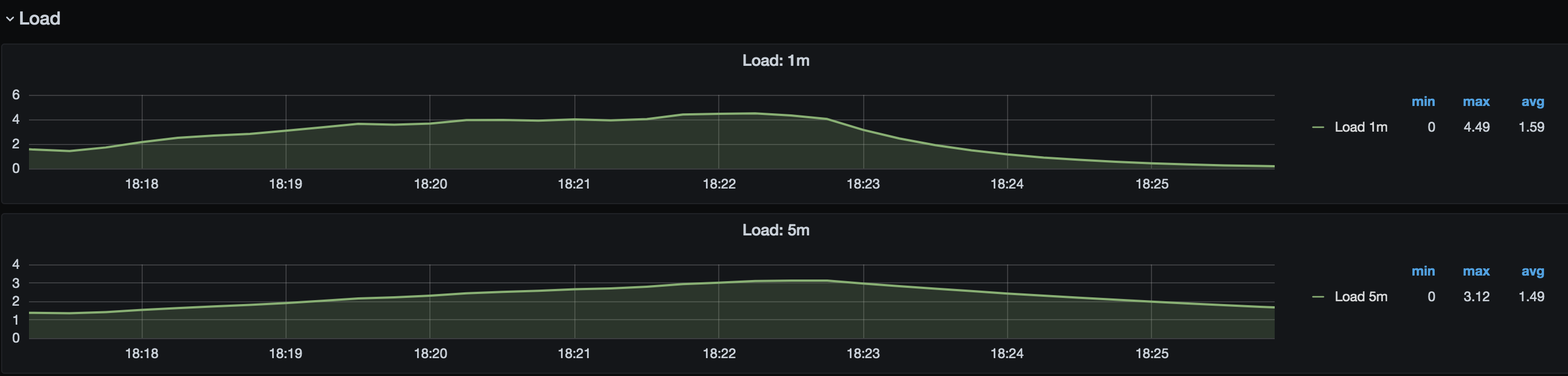
监控可见 \rtikv 的 cpu 核数只有 4C ,在压测期间,10.0.0.7除磁盘延时高外,服务器的 load 也比较高:
10.0.0.9 服务器 load:
心跳发送在 grafana 和 tikv log 中没有特别直观的展示,但是可以通过下面的信息来进行推断:
1)在 10.0.0.7 的 store 日志中,有大量的 raft 选举的信息,如下:
[2020/10/26 10:23:24.027 +00:00] [INFO] [raft.rs:1003] ["received a message with higher term from 20"] ["msg type"=MsgRequestVote] [message_term=10] [term=9] [from=20] [raft_id=19] [region_id=18]
[2020/10/26 10:23:24.027 +00:00] [INFO] [raft.rs:783] ["became follower at term 10"] [term=10] [raft_id=19] [region_id=18]
[2020/10/26 10:23:24.027 +00:00] [INFO] [raft.rs:1192] ["[logterm: 9, index: 83123, vote: 0] cast vote for 20 [logterm: 9, index: 83123] at term 10"] ["msg type"=MsgRequestVote] [term=10] [msg_index=83123] [msg_term=9] [from=20] [vote=0] [log_index=83123] [log_term=9] [raft_id=19] [region_id=18]
2)可以到其他 store 上过滤下压测时间段的 region 18 的相关信息,看下 region 18 详细的选举信息。
感谢!请问这个load是根据什么计算的呀
这个 load 就是服务器的负载,非数据库软件的负载