- 【TiDB 版本】:2.1.14
- 【问题描述】:收到报警,显示一个tidb节点突然网络流量很大,持续了15分钟左右,查看那个时间段慢sql,发现单条的insert都要1秒左右才完成。
请问有什么排查思路么。
查看了监控,就发现tikv的coprocessor的各项指标都很高
截取了一些异常飙高的指标的grafana截图
1014.zip (672.2 KB)
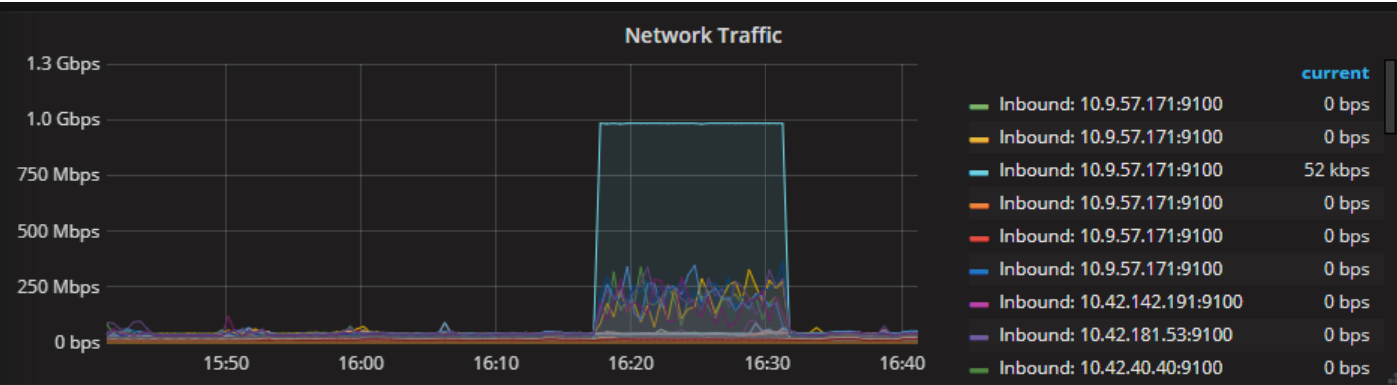
这是一个tidb节点的带宽,同一时间那个节点的内存消耗也很大。
tidb的带宽占满,我理解应该不影响tikv节点的吧,也不会影响insert的插入。
感觉是其他问题导致的
insert 操作是在其他 tidb 节点执行的吗,方便的话可以导出完整的 tidb 和 tikv-details 监控以及 insert 的 slow query 慢查询记录看看,导出监控参考 [FAQ] Grafana Metrics 页面的导出和导入
mysql> select * from information_schema.slow_query where is_internal = false order by query_time desc limit 10\G
*************************** 1. row ***************************
Time: 2020-10-14 16:34:13.347703
Txn_start_ts: 420128620370984992
User: usxxx@10.10.xx.xx
Conn_ID: 1686714
Query_time: 954.001199004
Process_time: 2372.364
Wait_time: 4.585
Backoff_time: 1.274
Request_count: 708
Total_keys: 176875855
Process_keys: 176875147
DB: xx_db
Index_ids:
Is_internal: 0
Digest: f7ac61f9d14ce294d8f011783c2145c1f35aee62fec59e8a125f57efa5c8ea72
Stats: t_order:pseudo
Cop_proc_avg: 3.35079661
Cop_proc_p90: 4.72
Cop_proc_max: 5.789
Cop_wait_avg: 0.006475988
Cop_wait_p90: 0.015
Cop_wait_max: 0.127
Mem_max: 10483142264
Query: select * from t_order group by order_id having count(1)>1 limit 100 ;
*************************** 2. row ***************************
Time: 2020-10-14 16:32:10.480918
Txn_start_ts: 420128603528232980
User: usxxx@10.10.xx.xx
Conn_ID: 1686710
Query_time: 895.367755841
Process_time: 2721.074
Wait_time: 5.392
Backoff_time: 10.987
Request_count: 708
Total_keys: 176875855
Process_keys: 176875147
DB: xx_db
Index_ids:
Is_internal: 0
Digest: f7ac61f9d14ce294d8f011783c2145c1f35aee62fec59e8a125f57efa5c8ea72
Stats: t_order:pseudo
Cop_proc_avg: 3.843324858
Cop_proc_p90: 5.418
Cop_proc_max: 6.623
Cop_wait_avg: 0.007615819
Cop_wait_p90: 0.018
Cop_wait_max: 0.142
Mem_max: 6101556509
Query: select * from t_order group by order_id having count(1)>1 limit 100 ;
又看了下慢查询,带宽满的那个tidb节点上有这两个慢查询,看上去似乎和这两个sql有关
TiDB 监控 Statement OPS 可以按照 instance 看下 Insert 类型的SQL,如果两个 TiDB instance 上都存在 OPS,那其中一个 TiDB 带宽占满也会导致 Insert Duration 升高


TiKV 监控 gRPC message 没有明显变化,但 Duration 却明显上涨,包括 kv_prewrite 和 kv_commit 影响写入延迟
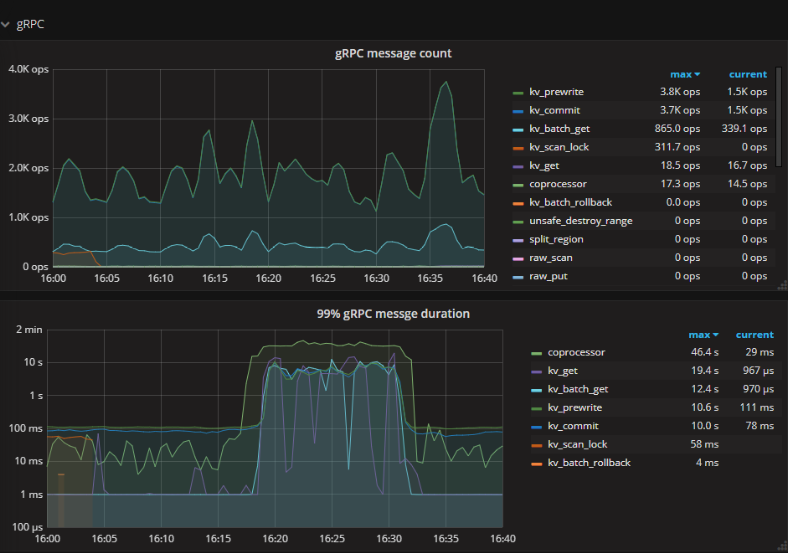
scheduler - prewrite/commit duration 看上去比较正常,可以 edit 编辑公式调大精度如 0.99999 确认此处的影响

storage async write duration 也没有抖动,同样可以 edit 调大精度确认下
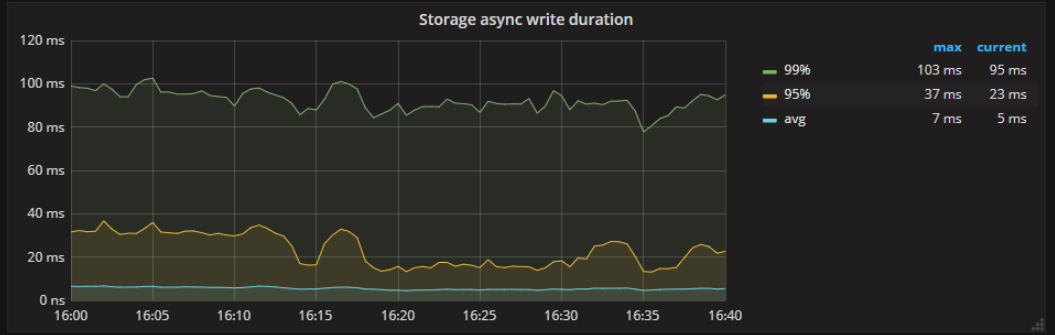
如果确认 TiKV 后端组件没有延迟升高的情况,那 TiKV 侧的延迟应该来源于 gRPC,推测 gRPC 受网络带宽影响可能会有消息堆积