presto --> tidb的原因:
- 分析师们平时的工作就是基于presto,后面的catalog包括hive,mysql,kudu;习惯于presto的sql语法,贸然整到tidb,不习惯
- 目前tidb只是小部分数据,主要t+1还是hive
- 懒,学习成本
presto --> tidb的原因:
可以关注一下最近和 知乎 一起孵化的项目 https://github.com/pingcap-incubator/TiBigData
目前已经支持 presto 通过 TiDB 做只读支持,可以关注一下这个项目 。
可以试用下,目前是支持利用presto和flink实现 hive <------> tidb同步的,读取这一块实现是走的tikv,比jdbc拉tidb数据能快上不少
后续我们在读方面还会支持follow read,写方面会封装mysql jdbc driver,支持TiDB server列表自动发现,多个server同时去写,以应对大数据量的写入(上亿条数据从离线导入TiDB)
我现在connector用的是mysql;看这个tibigdata新实现了一个tidb,这两个的区别是?优化吗?
是优化的,因为兼容性这里是需要大量的开发成本的,尤其是从 Presto 到 TiDB。TiBigData 是由 知乎 和 TiDB 开发者社区一起来完成的,这个工具会对于你的业务使用习惯应该改变很小。
我用过Presto查询TiDB的数据,主要是做一些复杂的SQL,比如开窗函数。直接用TiDB会比较慢,所以采用Presto,能提速很多。
但缺点是,Presto查询TiDB数据不太稳定,并发度不高,并发度高了,容易宕机。
感觉还是抽数据把TiDB抽挂了,我这里做T+1,用sqoop也经常把它抽挂,现在考虑社区方案,使用TiSpark直接抽Tikv
可以关注一下这个项目 ~
好的,谢谢
tibigdata抽数据就是直接走tikv的,应该会比jdbc抽好很多
请问有没有TiBigData编译好的包下载?我编译的过程出现一些问题。比如client-java的问题。虽然最后也编译成功了。但是放到presto上启动presto的时候就报错。不管是用prestodb还是prestosql都报错。无法使用。非常感谢
@humengyu2012 老师帮忙看一下?
tibigdata 依赖特定版本的 client-java, 这是因为有时候需要一些高级功能,但是 client-java 还没有发版。所以要先到 tibigdata 项目目录下面用 ./.ci/build-client-java.sh 这个命令编译一下 client-java, 然后再编译 presto-tidb, presto 的小版本跟 tibigdata 尽量保持一致,不然可能会有奇怪的问题,比如接口废弃之类的,如果还有问题,可以把报错贴过来
你好,这是一个很久以前被标记为已解决的问题,为了不影响你发的问题被淹没,如遇到新问题请发新帖咨询,避免问题遗漏。
已经开了新贴。
老师您好,已经编译成功。但是组件无法使用
2021-12-03T10:27:16.482+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog properties etc/catalog/mysql.properties –
2021-12-03T10:27:16.482+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog mysql –
2021-12-03T10:27:16.798+0800 INFO main Bootstrap PROPERTY DEFAULT RUNTIME DESCRIPTION
2021-12-03T10:27:16.798+0800 INFO main Bootstrap case-insensitive-name-matching false false
2021-12-03T10:27:16.798+0800 INFO main Bootstrap case-insensitive-name-matching.cache-ttl 1.00m 1.00m
2021-12-03T10:27:16.798+0800 INFO main Bootstrap connection-password [REDACTED] [REDACTED]
2021-12-03T10:27:16.798+0800 INFO main Bootstrap connection-url ---- jdbc:mysql://172.26.100.60:3306
2021-12-03T10:27:16.798+0800 INFO main Bootstrap connection-user ---- root
2021-12-03T10:27:16.798+0800 INFO main Bootstrap password-credential-name ---- ----
2021-12-03T10:27:16.798+0800 INFO main Bootstrap user-credential-name ---- ----
2021-12-03T10:27:16.798+0800 INFO main Bootstrap allow-drop-table false false Allow connector to drop tables
2021-12-03T10:27:16.798+0800 INFO main Bootstrap mysql.auto-reconnect true true
2021-12-03T10:27:16.798+0800 INFO main Bootstrap mysql.connection-timeout 10.00s 10.00s
2021-12-03T10:27:16.798+0800 INFO main Bootstrap mysql.max-reconnects 3 3
2021-12-03T10:27:16.942+0800 INFO main com.facebook.airlift.bootstrap.LifeCycleManager Life cycle starting…
2021-12-03T10:27:16.942+0800 INFO main com.facebook.airlift.bootstrap.LifeCycleManager Life cycle startup complete. System ready.
2021-12-03T10:27:16.943+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Added catalog mysql using connector mysql –
2021-12-03T10:27:16.944+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog properties etc/catalog/hive.properties –
2021-12-03T10:27:16.944+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog hive –
2021-12-03T10:27:18.074+0800 WARN main org.apache.hadoop.util.NativeCodeLoader Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
2021-12-03T10:27:18.164+0800 INFO main org.apache.hadoop.io.compress.bzip2.Bzip2Factory Successfully loaded & initialized native-bzip2 library system-native
2021-12-03T10:27:18.166+0800 INFO main org.apache.hadoop.io.compress.zlib.ZlibFactory Successfully loaded & initialized native-zlib library
2021-12-03T10:27:18.753+0800 INFO main com.facebook.airlift.bootstrap.LifeCycleManager Life cycle starting…
2021-12-03T10:27:18.754+0800 INFO main com.facebook.airlift.bootstrap.LifeCycleManager Life cycle startup complete. System ready.
2021-12-03T10:27:18.764+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Added catalog hive using connector hive-hadoop2 –
2021-12-03T10:27:18.765+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog properties etc/catalog/kudu.properties –
2021-12-03T10:27:18.765+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog kudu –
2021-12-03T10:27:19.101+0800 INFO main Bootstrap PROPERTY DEFAULT RUNTIME DESCRIPTION
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.client.default-admin-operation-timeout 30.00s 60.00s
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.client.default-operation-timeout 30.00s 60.00s
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.client.default-socket-read-timeout 10.00s 60.00s
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.client.disable-statistics false false
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.kerberos-auth.debug.enabled false false
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.kerberos-auth.enabled false false
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.kerberos-auth.keytab ---- ----
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.kerberos-auth.principal ---- ----
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.client.master-addresses ---- [172.28.8.101:7051, 172.28.8.102:7051, 172.28.8.103:7051]
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.schema-emulation.enabled false false
2021-12-03T10:27:19.101+0800 INFO main Bootstrap kudu.schema-emulation.prefix presto:: presto::
2021-12-03T10:27:19.269+0800 INFO main org.apache.kudu.client.AsyncKuduClient defaultSocketReadTimeoutMs is deprecated
2021-12-03T10:27:19.503+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Added catalog kudu using connector kudu –
2021-12-03T10:27:19.503+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog properties etc/catalog/tidb.properties –
2021-12-03T10:27:19.503+0800 INFO main com.facebook.presto.metadata.StaticCatalogStore – Loading catalog tidb –
2021-12-03T10:27:19.506+0800 ERROR main com.facebook.presto.server.PrestoServer com.facebook.presto.spi.connector.ConnectorContext.getTypeManager()Lcom/facebook/presto/spi/type/TypeManager;
java.lang.NoSuchMethodError: com.facebook.presto.spi.connector.ConnectorContext.getTypeManager()Lcom/facebook/presto/spi/type/TypeManager;
at io.tidb.bigdata.prestodb.tidb.TiDBConnectorFactory.create(TiDBConnectorFactory.java:51)
at com.facebook.presto.connector.ConnectorManager.createConnector(ConnectorManager.java:379)
at com.facebook.presto.connector.ConnectorManager.addCatalogConnector(ConnectorManager.java:231)
at com.facebook.presto.connector.ConnectorManager.createConnection(ConnectorManager.java:223)
at com.facebook.presto.connector.ConnectorManager.createConnection(ConnectorManager.java:209)
at com.facebook.presto.metadata.StaticCatalogStore.loadCatalog(StaticCatalogStore.java:123)
at com.facebook.presto.metadata.StaticCatalogStore.loadCatalog(StaticCatalogStore.java:98)
at com.facebook.presto.metadata.StaticCatalogStore.loadCatalogs(StaticCatalogStore.java:80)
at com.facebook.presto.metadata.StaticCatalogStore.loadCatalogs(StaticCatalogStore.java:68)
at com.facebook.presto.server.PrestoServer.run(PrestoServer.java:150)
at com.facebook.presto.server.PrestoServer.main(PrestoServer.java:85)
启动presto的时候报错。prestosql和prestodb都试过
presto版本0.265.1 tidb版本v5.3.0
当前编译的 presto 版本是 0.234.2 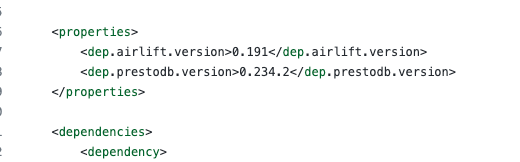
可能你用的 presto 版本和这个版本的某些 api 不兼容了
请问是否兼容trino?