为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】 场景 + 问题概述
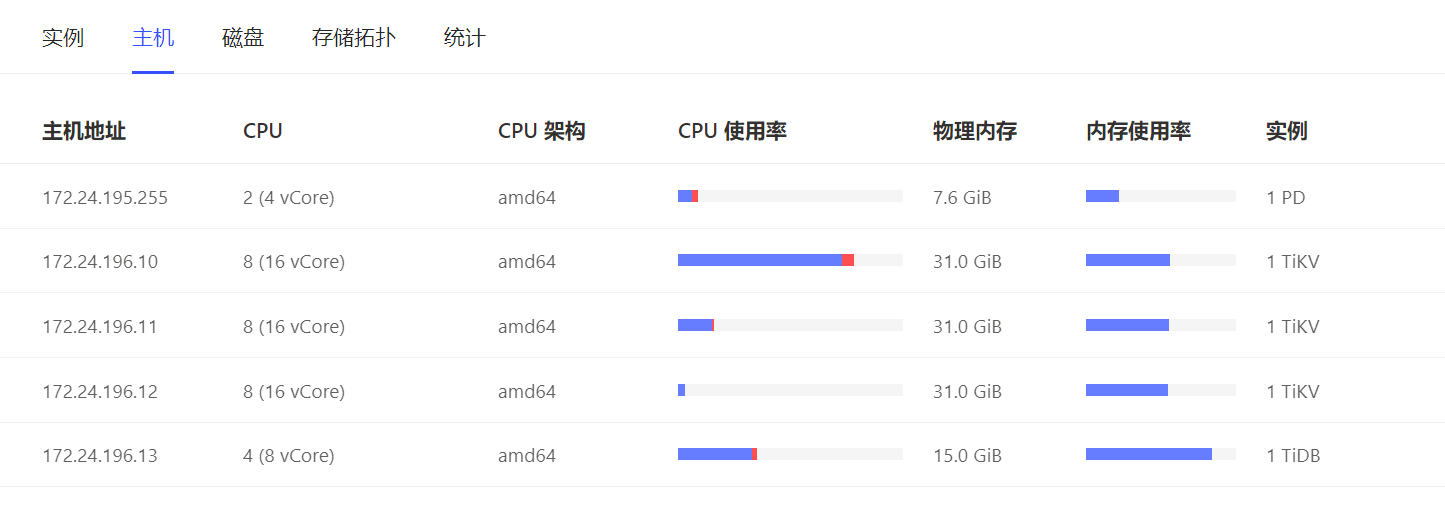
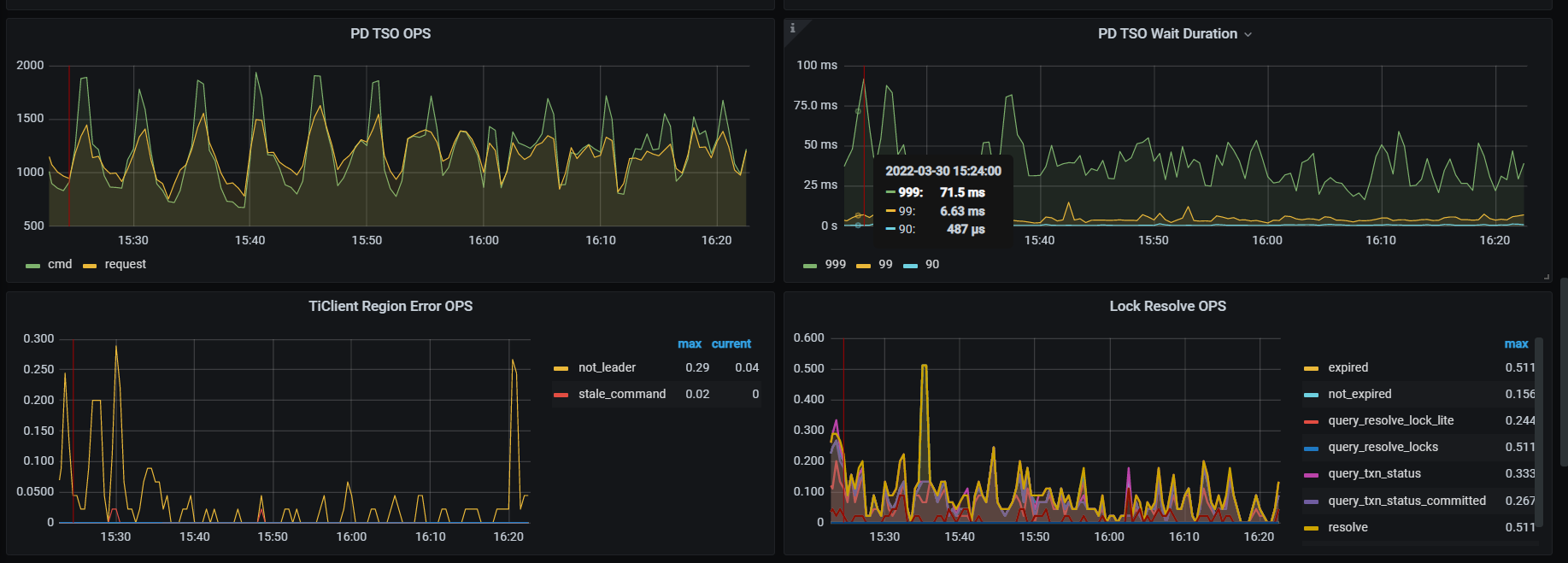
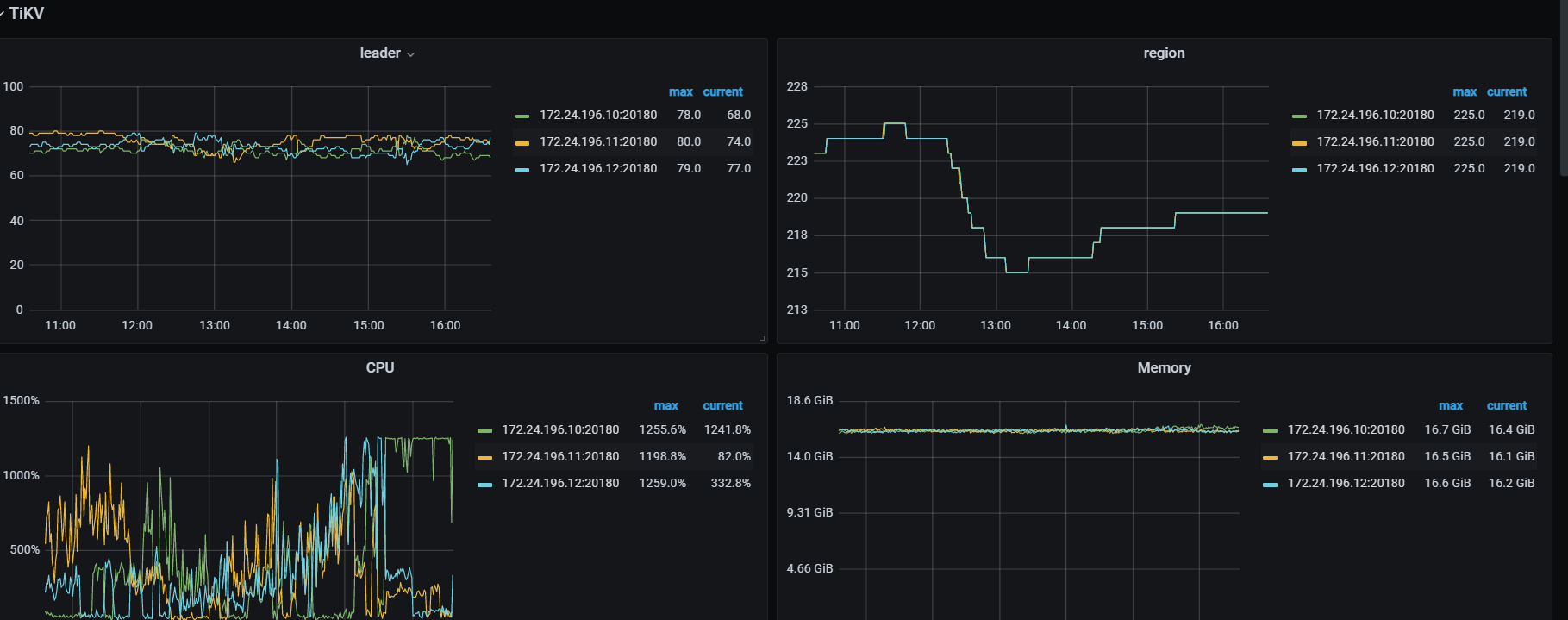
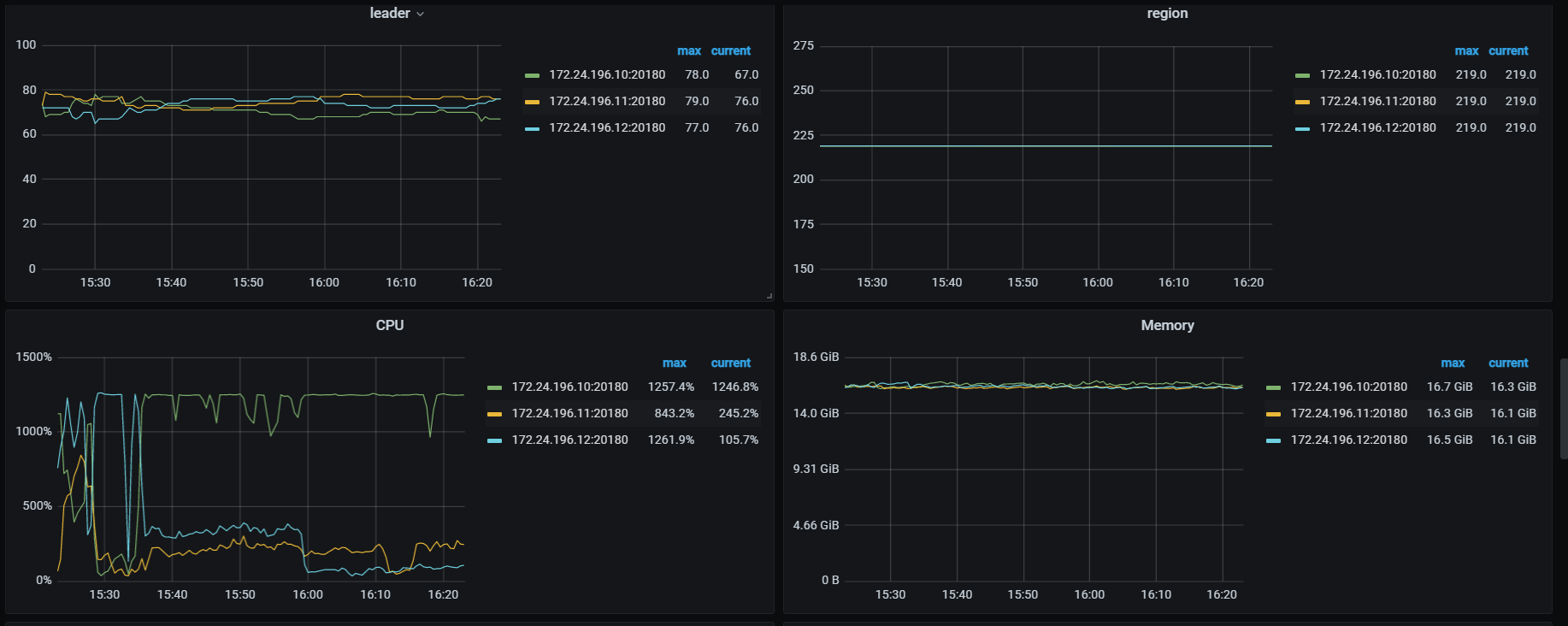
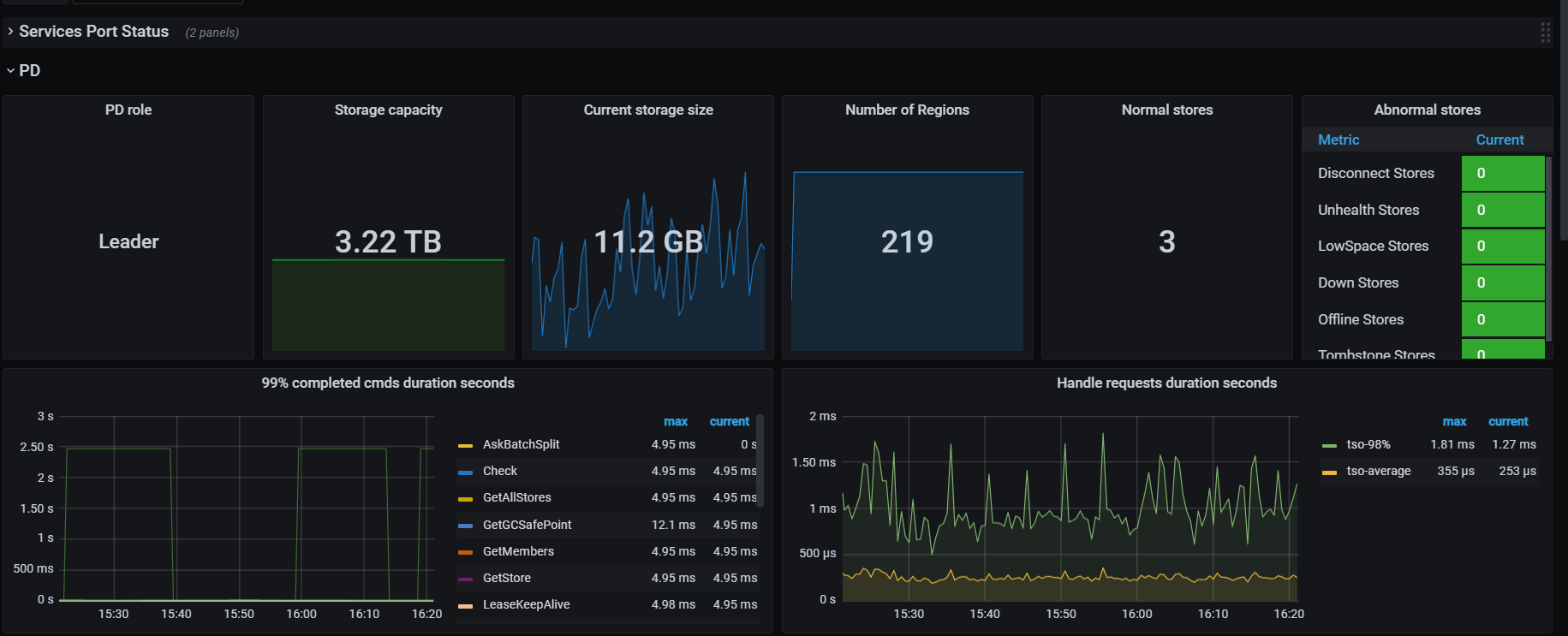
三台tikv 随机出现cpu变高的情况达到75%+ ,导致服务直接不可用。但是另外其他的机器cpu都很低
【背景】 做过哪些操作
没有做过什么操作,就是使用用户多了
【现象】 业务和数据库现象
导致页面所有接口读写都很慢,数据库直接卡死
【问题】 当前遇到的问题,参考 AskTUG 的 Troubleshooting 读性能慢-慢语句
【统计信息是否最新】
【执行计划内容】
【 SQL 文本、schema 以及 数据分布】
【业务影响】
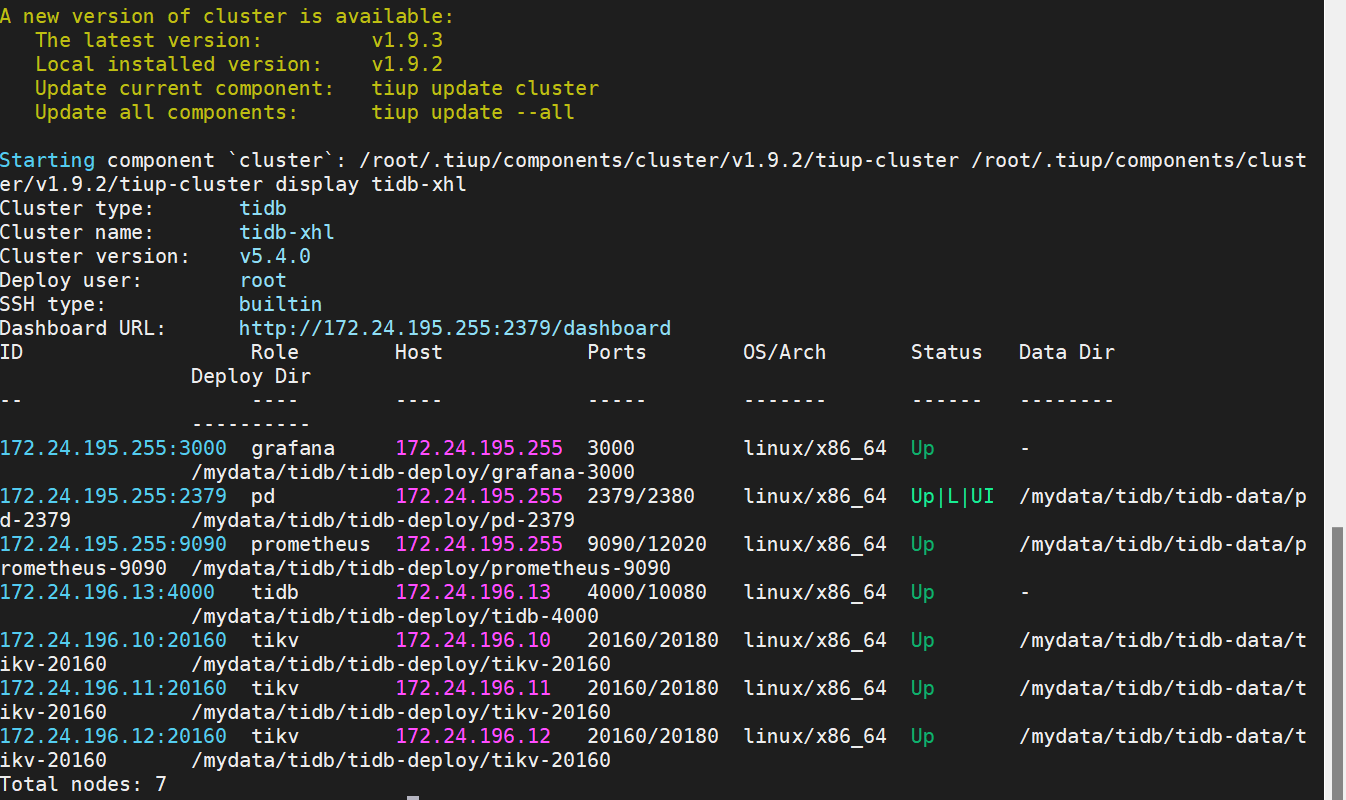
【TiDB 版本】
v5.4
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
- TiDB-Overview Grafana监控
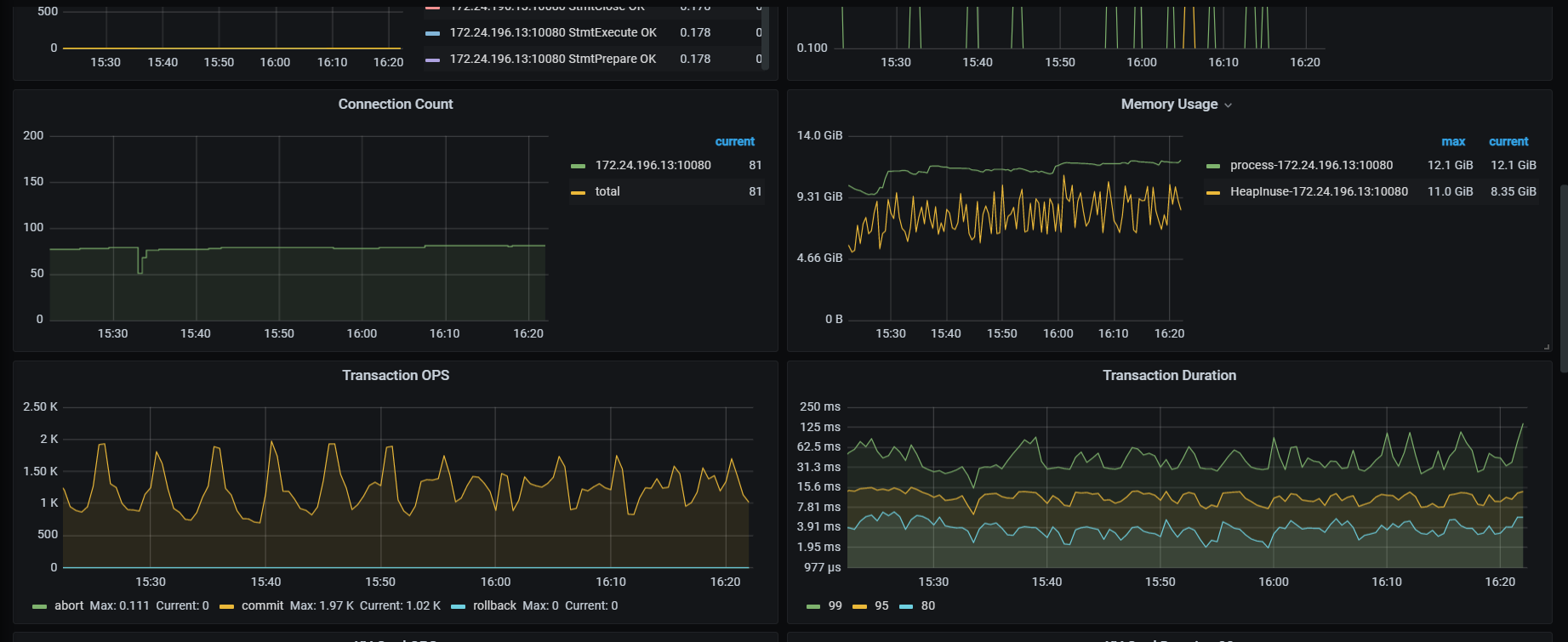
- TiDB Grafana 监控
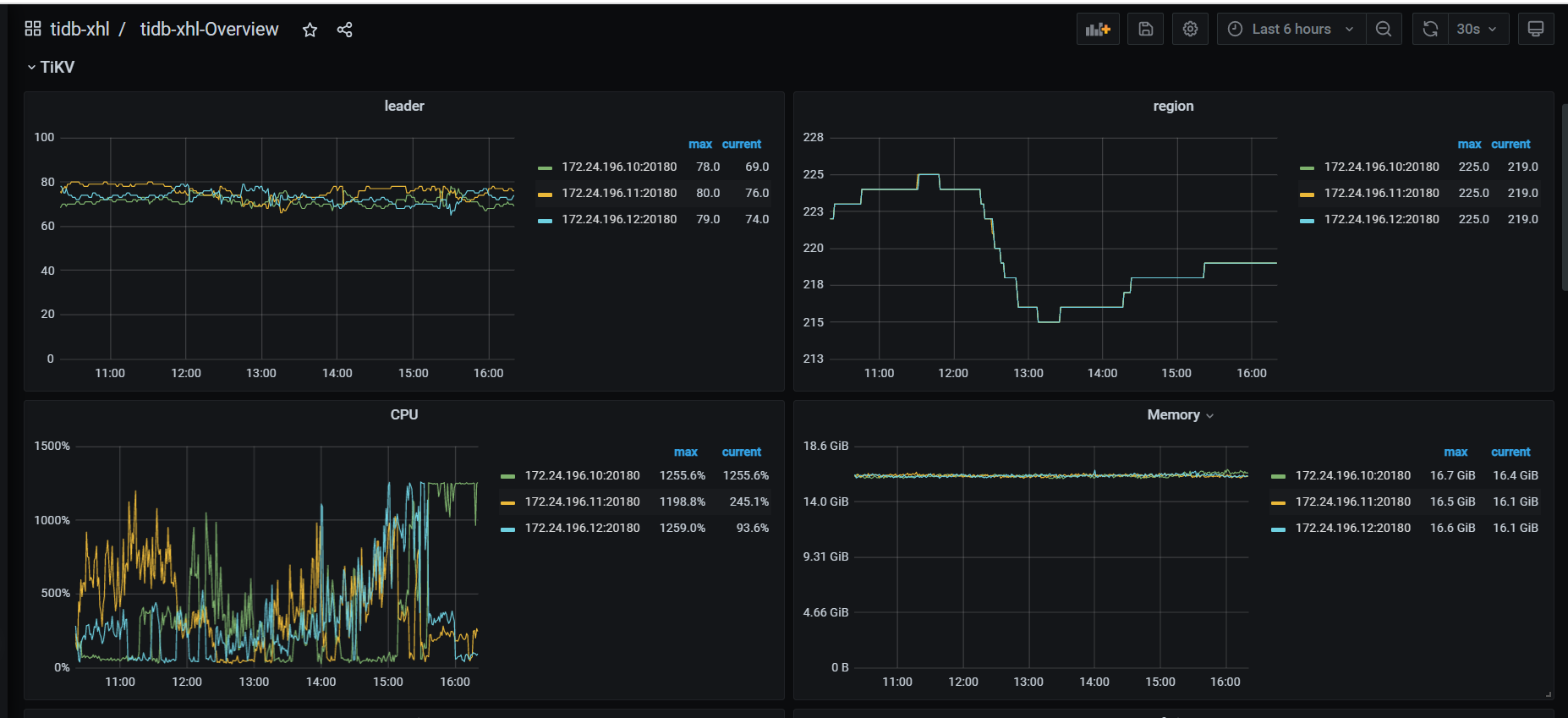
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
h5n1
(H5n1)
2
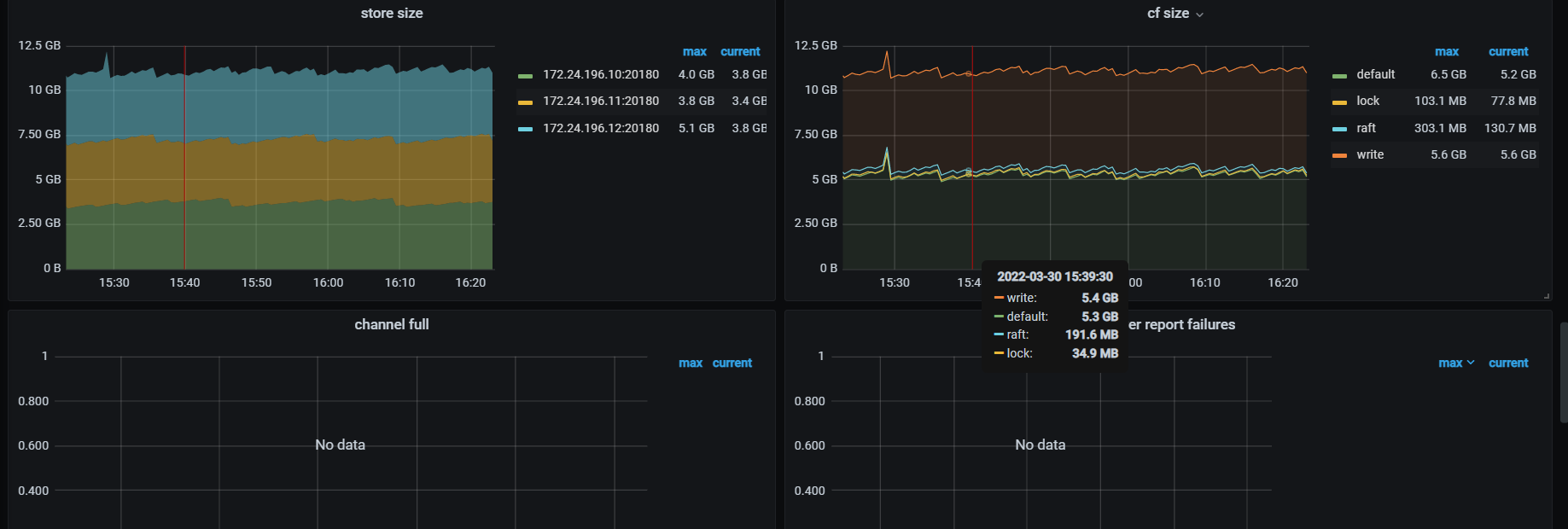
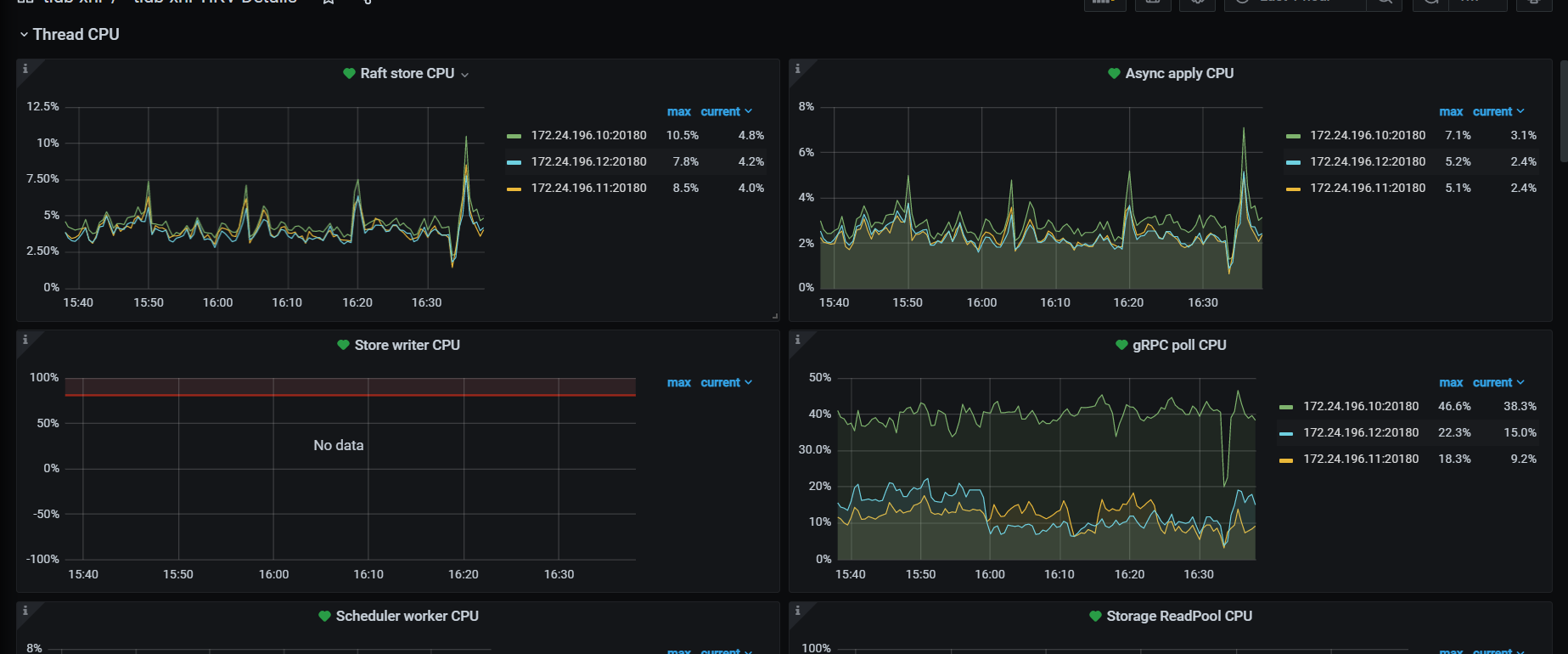
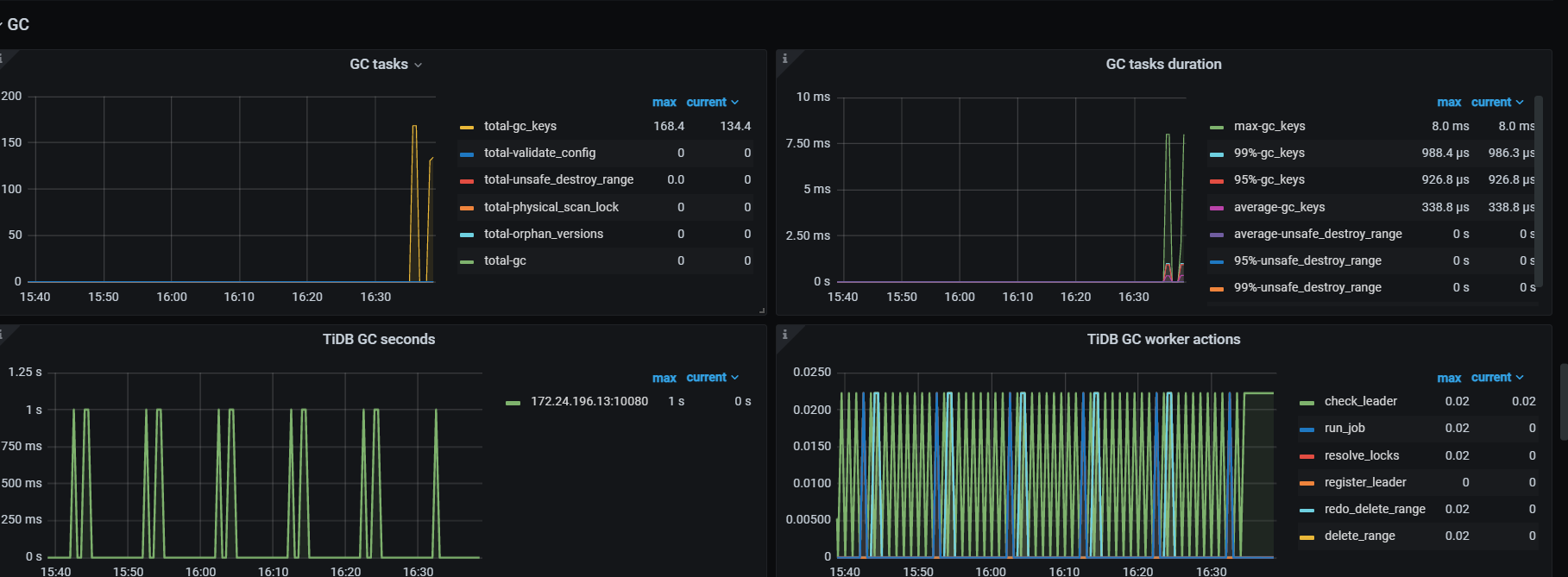
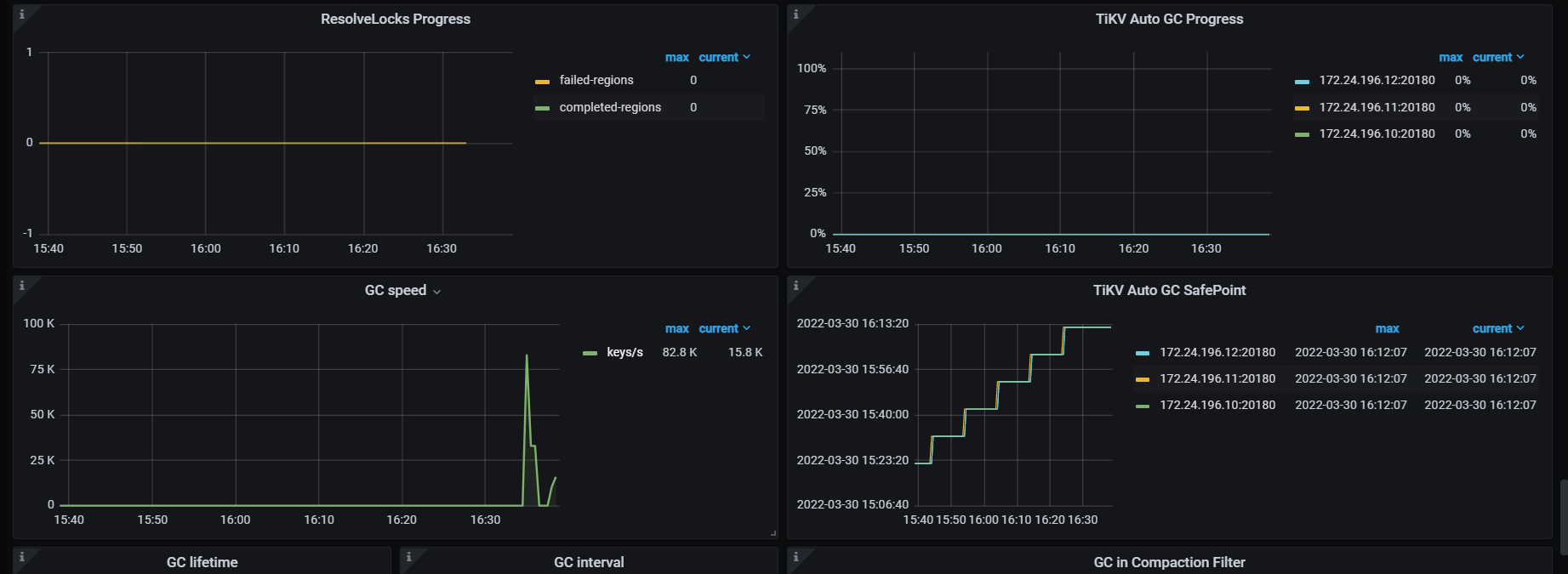
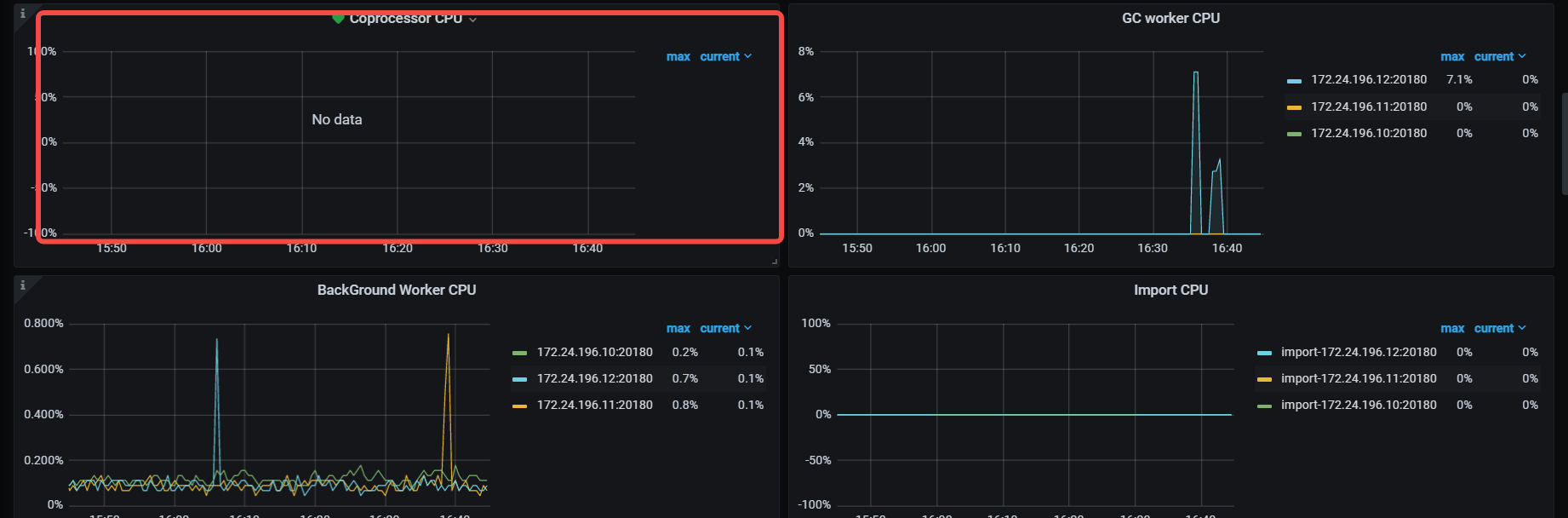
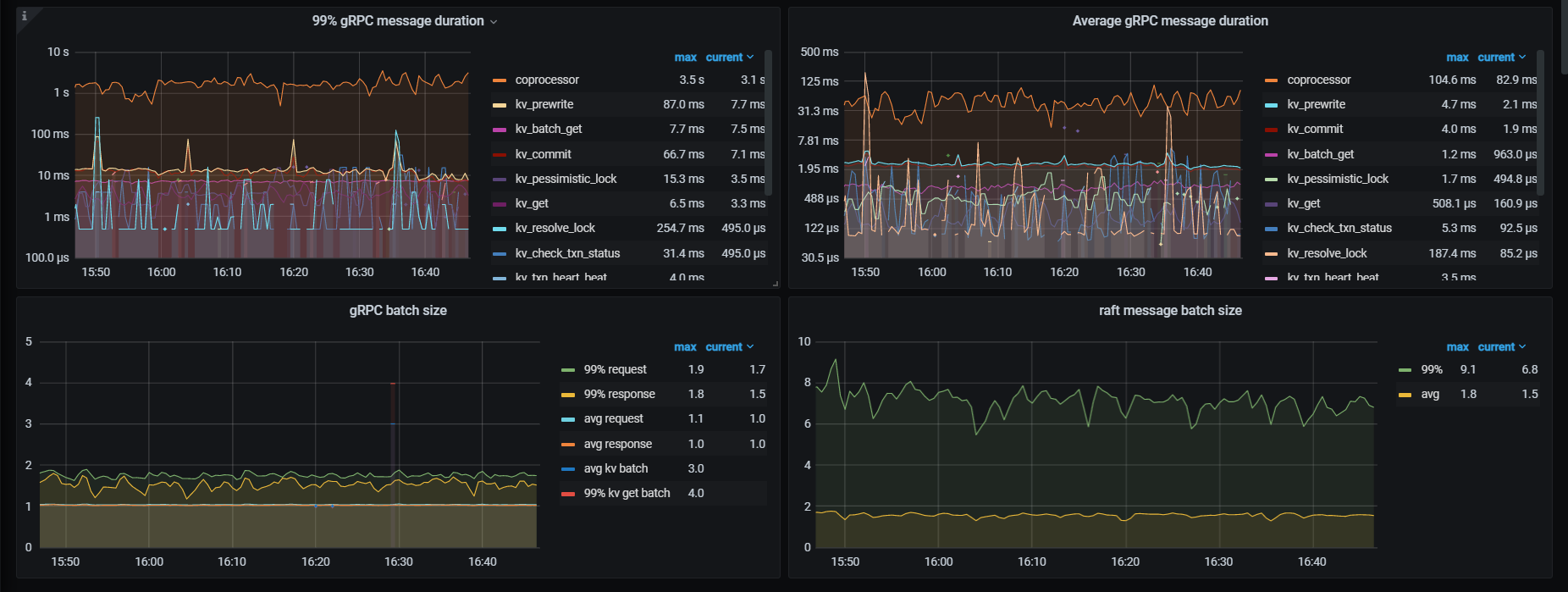
看下tikv detail 下thread CPU 、GC监控、rocksdb的compaction监控
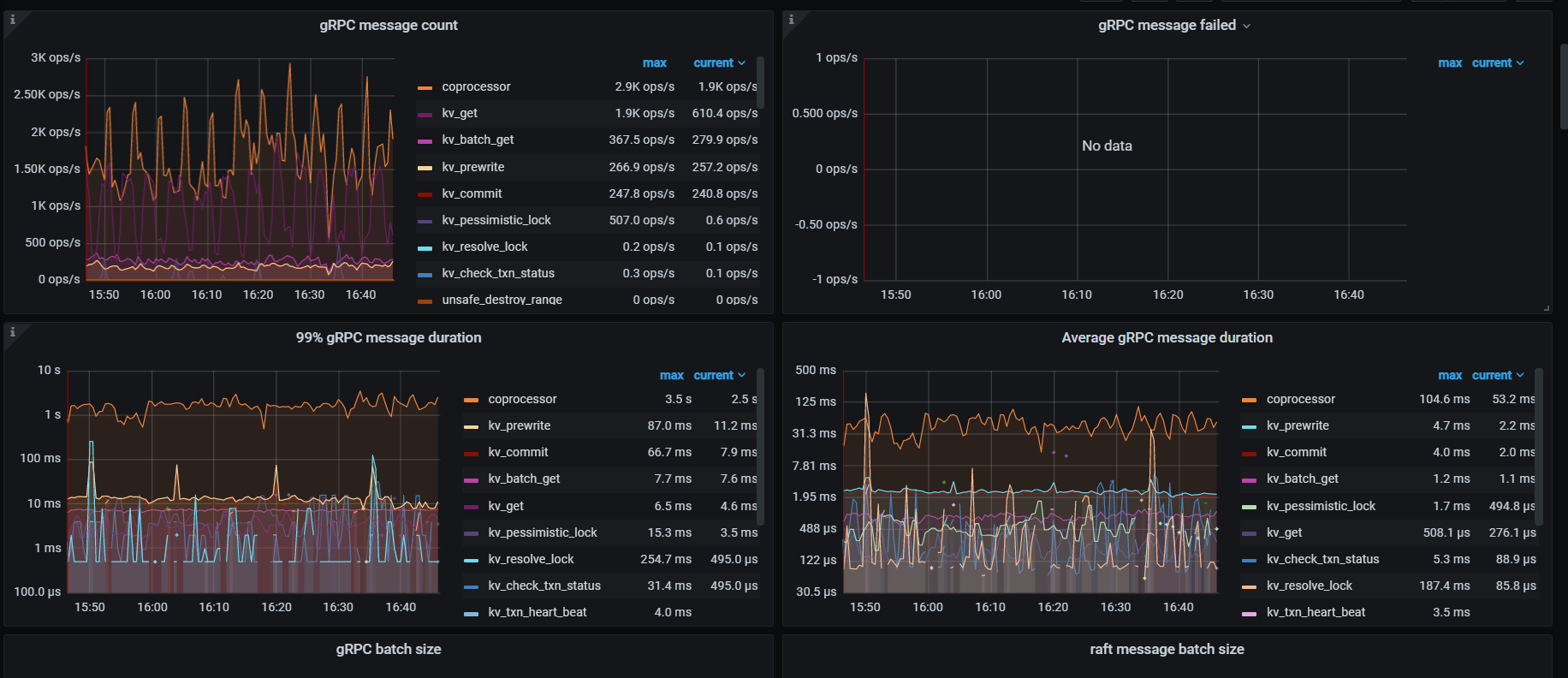
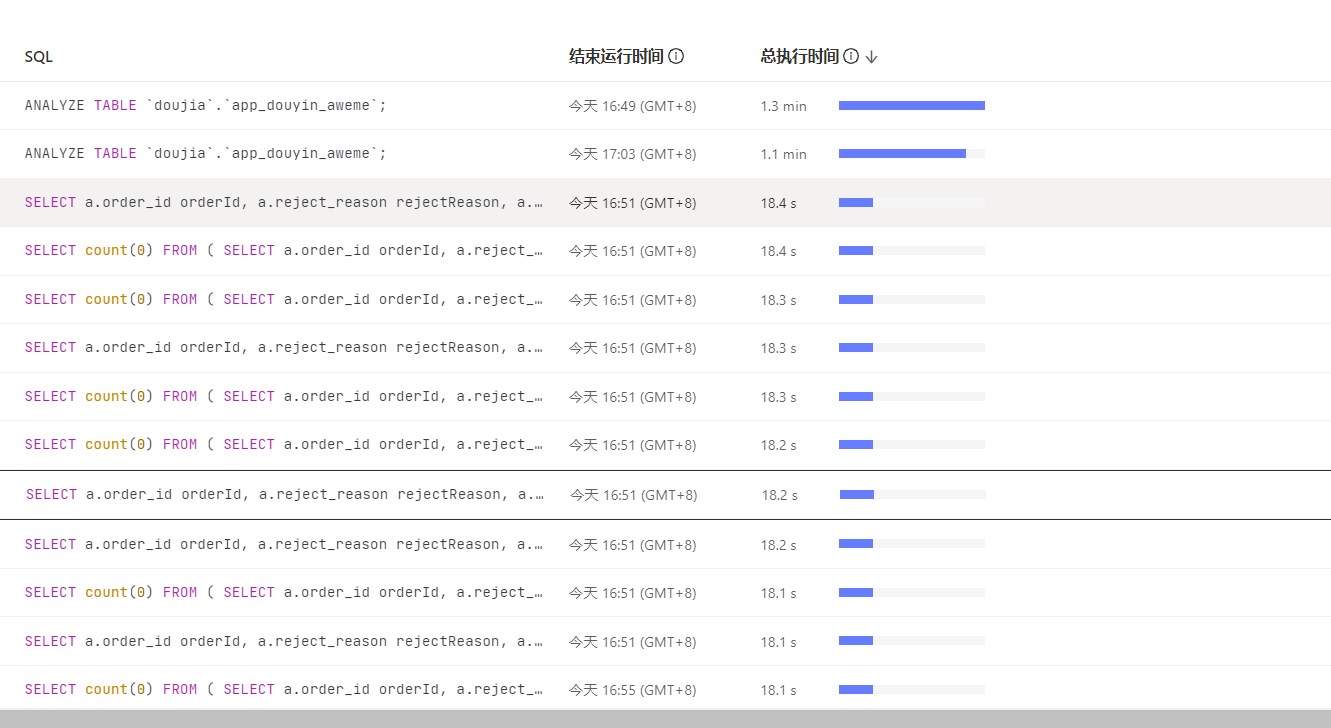
看慢sql统计是没有问题的,当cpu上来之后都成慢sql了
h5n1
(H5n1)
6
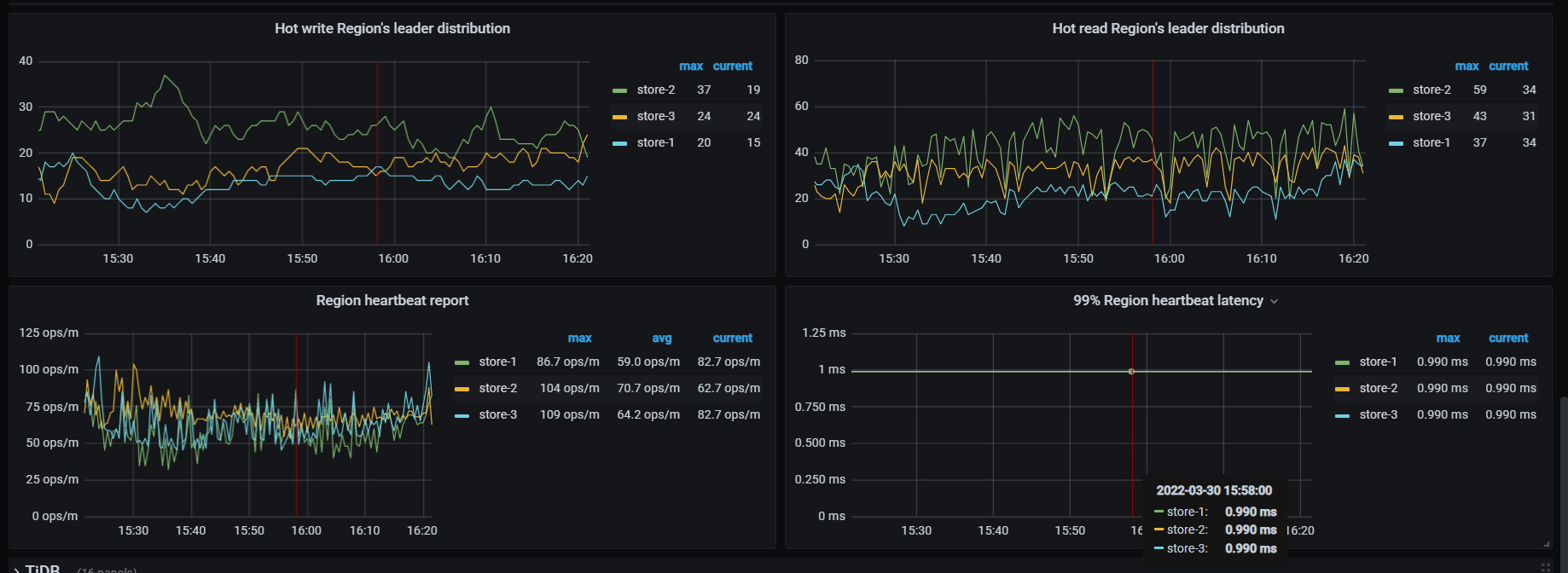
thread cpu下面那些CPU利用率呢,看grpc cpu,有热点,看看慢SQL,dashboard上 流量可视化可以看热点表
db_user
(Db User)
10
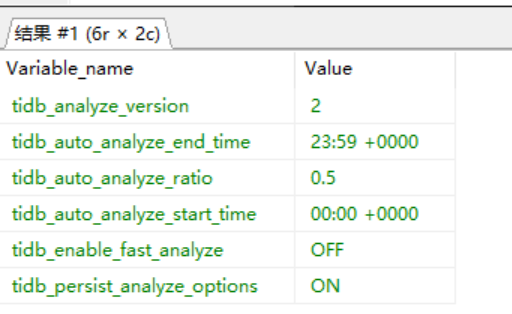
看下analyze状态呢:show analyze status;
是不是有一直不成功的analyze,或者大表analyze导致的。
另外看下analyze的相关配置:
show variables like ‘%analyze%’
db_user
(Db User)
13
可以看下cpu升高的时间有没有对应的analyze failed的消息,然后可以尝试下更改start_time,end_time到一个小时,或者一个小的时间段,更改version为1观测下情况
db_user
(Db User)
18
h5n1
(H5n1)
21
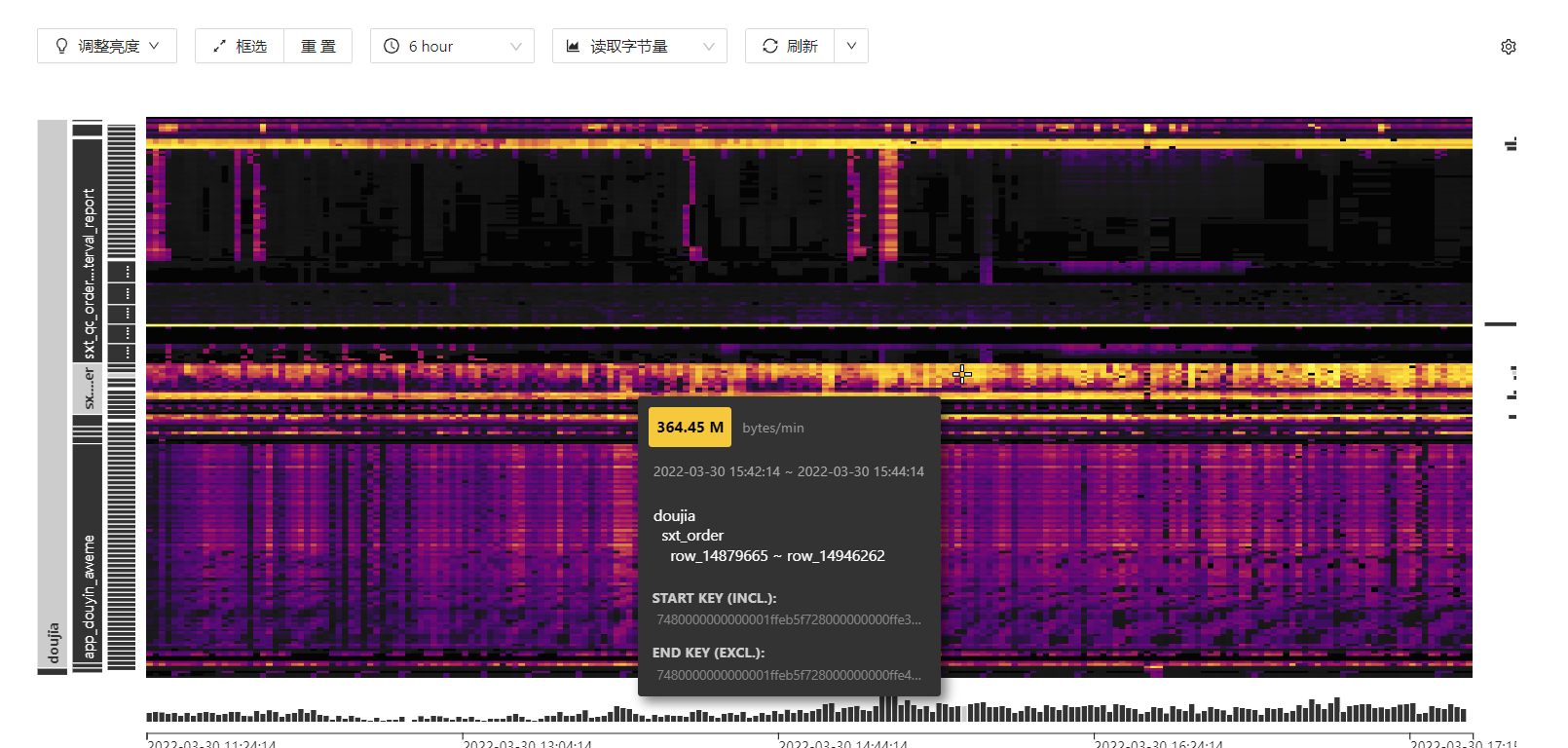
细长的亮条就是热点的对象,先分析下相关的SQL执行计划