【 TiDB 使用环境】生产环境
【概述】 场景 + 问题概述
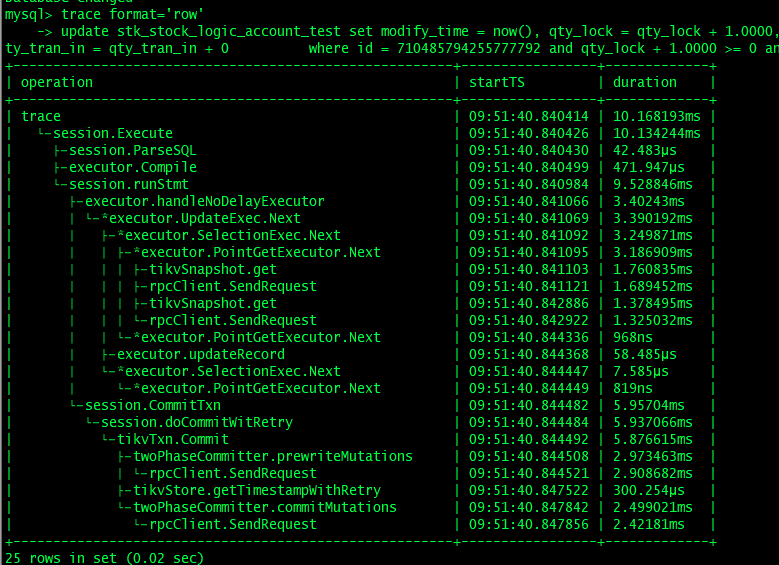
我们生产环境使用的是TiDB数据库v4.0.9,现在更新5000条数据需要花费50多秒,客户觉得时间太长,有没有什么办法可以快速更新5000条数据,由于业务的原因,这5000条更新只能在一个事务中。不能拆分。
【TiDB 版本】 V4.0.9
【 TiDB 使用环境】生产环境
【概述】 场景 + 问题概述
我们生产环境使用的是TiDB数据库v4.0.9,现在更新5000条数据需要花费50多秒,客户觉得时间太长,有没有什么办法可以快速更新5000条数据,由于业务的原因,这5000条更新只能在一个事务中。不能拆分。
【TiDB 版本】 V4.0.9
1)什么锁模式,这种建议悲观模式,防止不断重试?
2)系统负载如何?是有热点问题?
3)本身5k条数据,很可能分布在不同的region中,需要的时间相对长一些;
1.目前数据库使用的是悲观锁
2. 目前系统负载正常,没有热点,测试的表也没有其他引用访问
3. 同样的表和同样的数据,在mysql上执行3s就出结果了,但是在TiDB上执行要花费22s。而且mysql还是我随便找了一条虚拟机,硬件是TIDB集群的机器的1/10性能。
tidb的使用也是需要有场景的
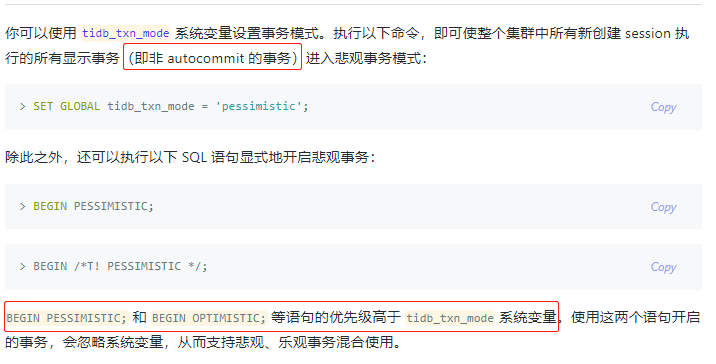
1)怎么确定业务使用的是悲观锁呢? 参考这里:
Query OK, 4861676 rows affected (24 min 54.29 sec) 5.2.3更新耗时
去掉更新列上的索引后
Query OK, 4861676 rows affected (51.89 sec)
Rows matched: 4861676 Changed: 4861676 Warnings: 0
只加1个索引
mysql> create index idx12 on ta(k);
Query OK, 0 rows affected (2 min 7.51 sec)
mysql> update ta set k=k+10000;
Query OK, 4861676 rows affected (2 min 22.13 sec)
Rows matched: 4861676 Changed: 4861676 Warnings: 0
加回第2个索引
mysql> create index idx13 on ta(id,k,c);
Query OK, 0 rows affected (2 min 36.66 sec)
mysql> update ta set k=k+10000;
Query OK, 4861676 rows affected (3 min 40.25 sec)
Rows matched: 4861676 Changed: 4861676 Warnings: 0
谢谢大佬的回复,我们这边前期是另一个同事在做架构设计,当时选用了tidb,现在客户总是拿之前他们的mysql,oracle来和tidb做比较,解释了几次他们也没有接受。
谢谢大佬的回复。我的更新是按照主键列做为更新条件的。要更新的列上面也不存在索引。目前更新一条数据的耗时在100ms左右,但是同时有2000条更新一起操作的话总的时间就比较长。同样的表和同样的数据在mysql上3s就更新完成了,但是在tidb上需要将近20s。差距有点大,客户不是太愿意接受。你的数据也是也非常说明索引问题的。谢谢
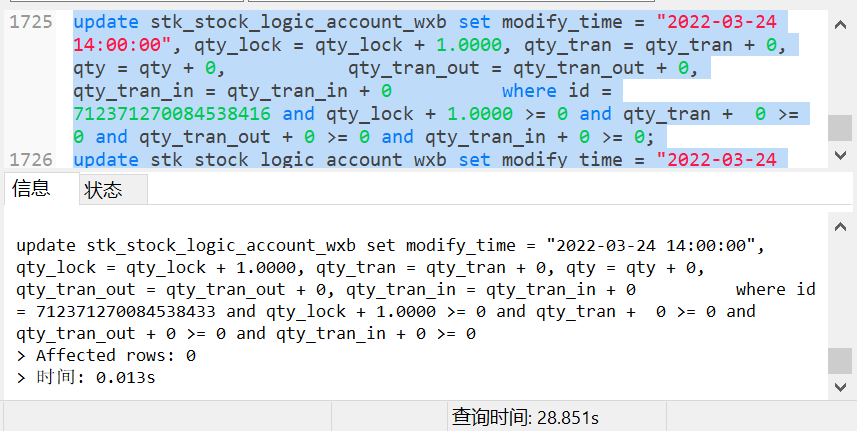
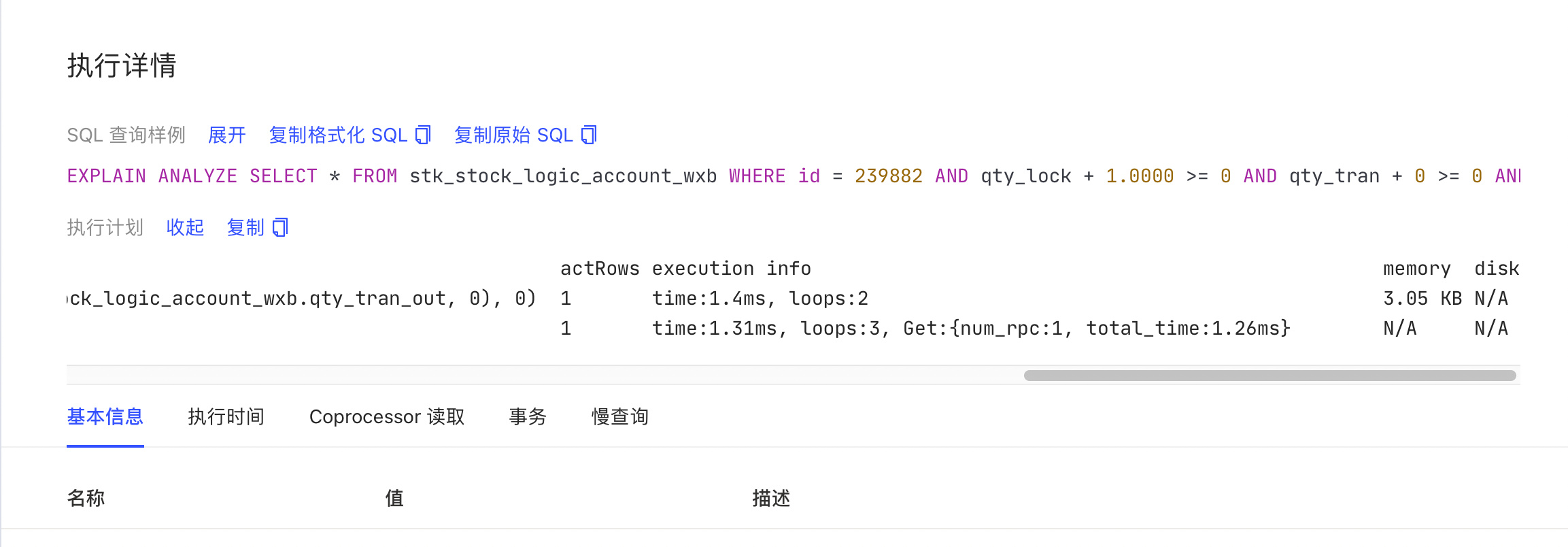
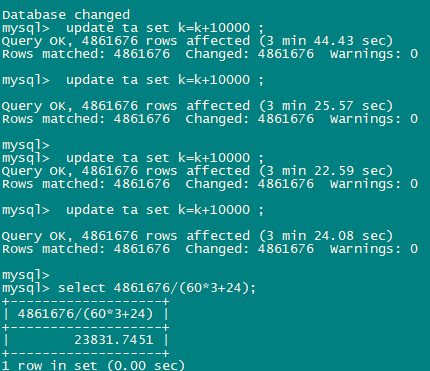
不知道我第一次那个是哪卡住了,后来试了几次486万条数据都在3分钟更新完,按这时间计算1秒钟能更新2万多条。 发下你的update 慢SQL信息dashboard或slow log里的
建库语句.sql (77.5 MB) 更新语句.sql (608.6 KB)
大佬可以看看我的情况,我的更新因为更新的条件到时候会不一样,也就是我的qty的值可能会加1,也可以会加其他的值,所以没法固定下来,只能根据id一个一个进行更新。
我们的现在已经进行到下面的步骤了。在业务低峰,我的表中有2000w的数据,在一个事务中有1800条更新语句,执行这个事务花费了10s以上,客户不能接受这个时间。客户需要将时间控制在3-5s,不知道在不拆分事务和拆分之后事务并行的情况下,还能怎么操作。由于拆分事务带来的业务代码修改工作量太大。我们检查过系统的性能, 所有资源的使用都处于低点。
业务无冲突的情况下,能否尝试乐观事务来执行,可以通过 begin optimistic; 开启或者 set tidb_txn_mode = ‘optimistic’; 单独操作需要乐观事务的 session。
但是,不拆分事务单线程下,利用不起来分布式数据库的资源优势,完全达到跟 MySQL 一样的的性能估计有困难。
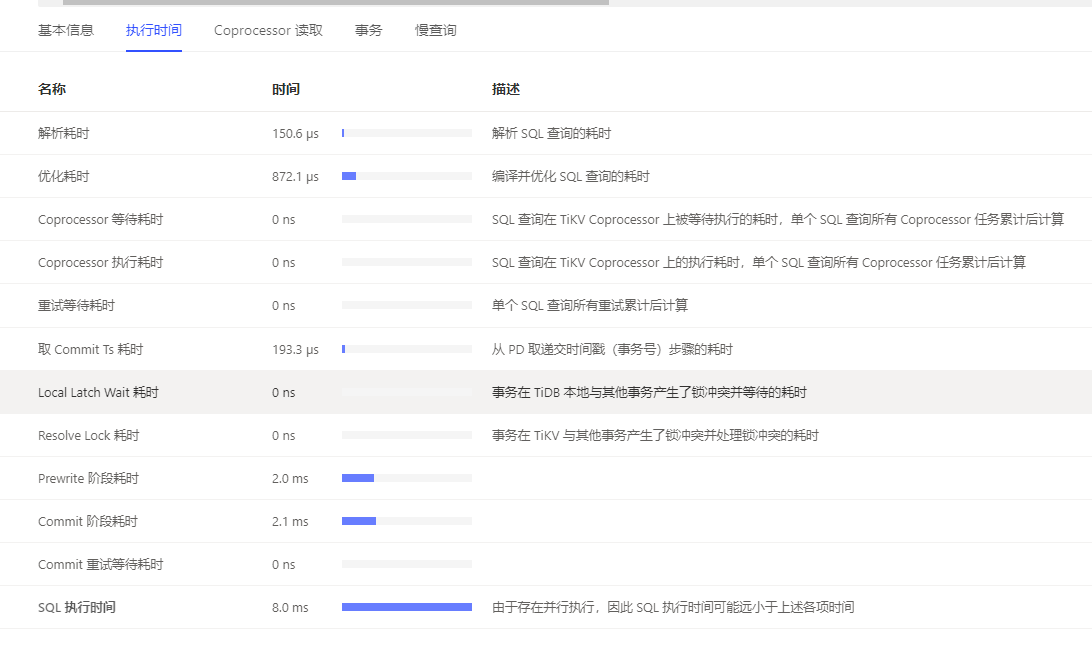
另外,可以看一下,TiDB → Transaction 下的这个面板,看有没有等待。如果有,可以把 https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file#committer-concurrency 调大试试。
多问一下,会有批量的这种事物并行执行吗?有可能 where 条件中互相有冲突吗业务上?
可以考虑分区切片,切割刀多个region,就可以利用到并行,如果在一个region那并行能力就没有了。
由于我们开发对事务的控制太差,经常发生冲突,使用乐观锁我害怕带来更多的问题。
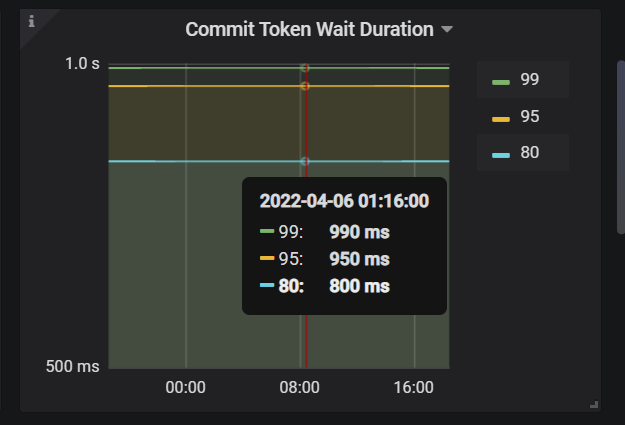
我看了下commit-token wait duration 平均都在1s左右,committer-concurrency用的还是v4.0.9的默认的16,我晚上将这个改大点测试下。我之前问过业务,这种事务一般不会并行,但是也不排除会有并行,并行的时候可能会存在冲突。
你的意思是建表的时候通过SHARD_ROW_ID_BITS进行控制嘛?
请问有调整吗? 效果如何?
有调大到128,但是没有任何作用