hygame
2022 年3 月 28 日 08:32
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
haproxy配置:
listen prod-tidb-cluster
bind 10.106.10.91:5000
mode tcp
balance roundrobin
server 10.106.30.17:4000 10.106.30.17:4000 send-proxy check inter 2000 rise 2 fall 3
server 10.106.30.19:4000 10.106.30.19:4000 send-proxy check inter 2000 rise 2 fall 3
tidb配置:
注:透传功能正常,业务正常,tidb-server日志erro刷得太快
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
【附件】
TiUP Cluster Display 信息
TiUP Cluster Edit Config 信息
TiDB- Overview 监控
h5n1
2022 年3 月 28 日 08:56
2
配置proxy-protocol.networks后 参数里的IP只能使用harpxoy去连,不能直连tidb server了
hygame
2022 年3 月 28 日 09:04
3
h5n1:
proxy-protocol.networks
proxy-protocol.networks里面的ip是haproxy的,是不是不应该写haproxy的ip,用*啊
hygame
2022 年3 月 28 日 09:16
6
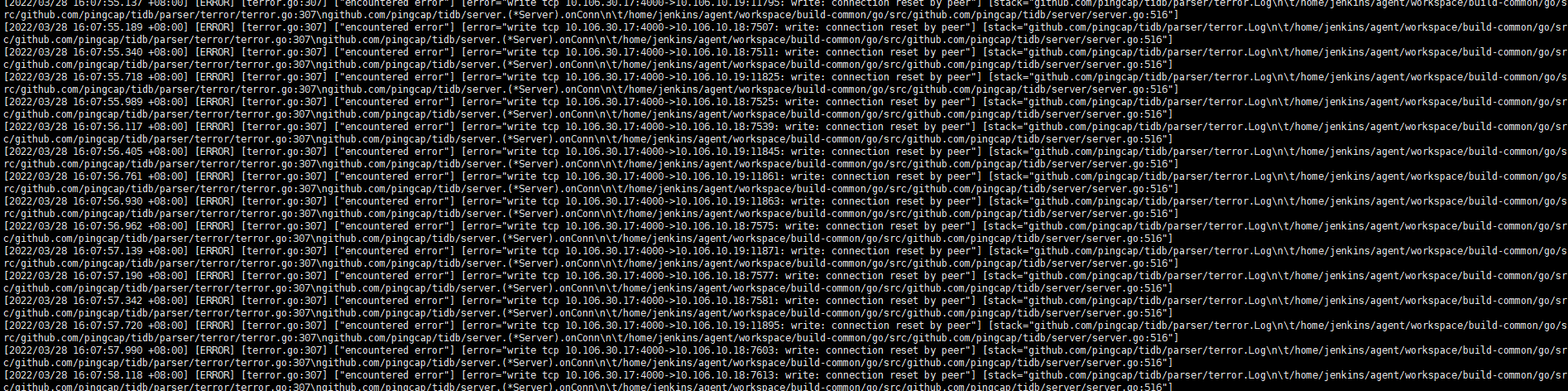
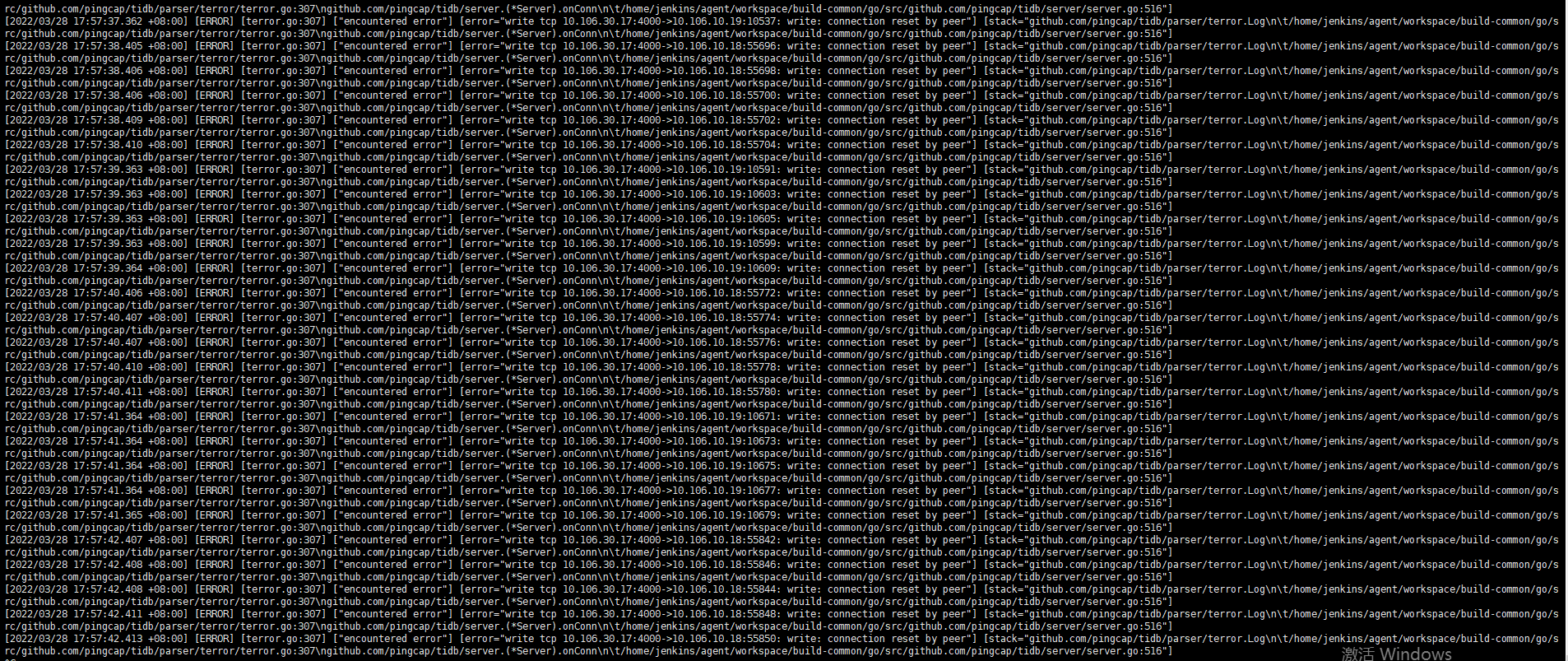
proxy-protocol.networks中的两个ip是允许这两个ip使用proxy协议连接tidb,那相当于我配置是对的,可为什么tidb-server 还会报[ERROR] [terror.go:307] [“encountered error”] [error=“write tcp 10.106.30.17:4000->10.106.10.18:7613: write: connection reset by peer”] [stack=“github.com/pingcap/tidb/parser/terror.Log\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\
github.com/pingcap/tidb/server.(*Server ).onConn\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:516”]
hygame
2022 年3 月 28 日 09:19
7
我前端有两个haproxy,10.106.10.18,10.106.10.19,这两个是ip,程序连接的域名映射的是一个vip,在10.106.10.18,10.106.10.19这两个上面飘
h5n1
2022 年3 月 28 日 09:53
10
应该是17像18普罗写数据,18和17间因为18配置了透传,不能直连,导致的报错
hygame
2022 年3 月 28 日 09:59
11
10.106.30段是tidb,10.106.10段是haproxy,这个是tidb server访问haproxy端口导致的,但是不知道为啥要访问haproxy的端口
hygame
2022 年3 月 29 日 03:08
13
请问这个怎么解决,tidb-server日志因为这个错误增长太快
system
2022 年10 月 31 日 19:25
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。