CAICAI
(Fengzhencai)
1
MySQL:5.7.25
TiDB:5.2
如何将MySQL中上T的数据全量快速的导入到TiDB里面去呢,用dumpling吗,有人试过更快效率的导入方式吗
补充记录:
我用的dumpling从测试环境的MySQL导数据出来,好慢,我的参数是:
./dumpling -h 127.0.0.1 -P 3306 -u root -p *** -t 32 -F 5GB -r 2000000 -B ddm -o /data/tools/db/
这个测试库总共800G+,有一个大表450G,日志如下:
[2022/03/26 11:20:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=406410234] [“estimate total rows”=629806175] [“finished size”=45.77GB] [“average speed(MiB/s)”=0.5925177294306065]
[2022/03/26 11:22:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=407247251] [“estimate total rows”=629806175] [“finished size”=45.85GB] [“average speed(MiB/s)”=0.5927157072989034]
[2022/03/26 11:24:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=408082623] [“estimate total rows”=629806175] [“finished size”=45.92GB] [“average speed(MiB/s)”=0.5922591735614775]
[2022/03/26 11:26:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=408907071] [“estimate total rows”=629806175] [“finished size”=46GB] [“average speed(MiB/s)”=0.584776183484279]
基本上2分钟0.05G导出,已经导了12个小时了,这才导出46G 
是我这参数有问题吗?
啦啦啦啦啦
2
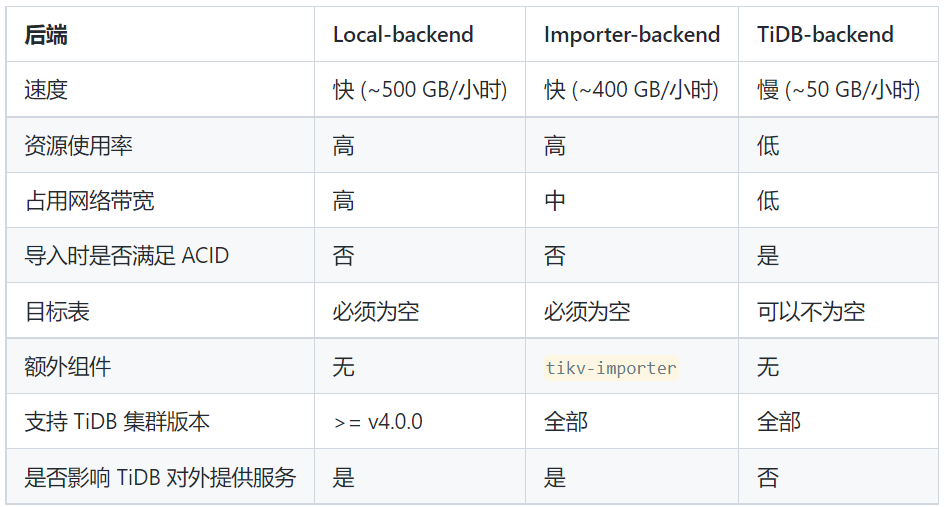
异构数据库只能使用逻辑备份导入。dumpling+ TiDB Lightning (Local-backend)速度已经够快了,后端使用 Local-backend最快。
TiDB Lightning导入数据参考这里
https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-backends
1 个赞
wakaka
(Wakaka)
4
dumpling+lightling最快,注意导入后端模式选择,然后dm属于正常的dump速度。
CAICAI
(Fengzhencai)
6
我用的dumpling从测试环境的MySQL导数据出来,好慢,我的参数是:
./dumpling -h 127.0.0.1 -P 3306 -u root -p *** -t 32 -F 5GB -r 2000000 -B ddm -o /data/tools/db/
这个测试库总共800G+,有一个大表450G,日志如下:
[2022/03/26 11:20:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=406410234] [“estimate total rows”=629806175] [“finished size”=45.77GB] [“average speed(MiB/s)”=0.5925177294306065]
[2022/03/26 11:22:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=407247251] [“estimate total rows”=629806175] [“finished size”=45.85GB] [“average speed(MiB/s)”=0.5927157072989034]
[2022/03/26 11:24:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=408082623] [“estimate total rows”=629806175] [“finished size”=45.92GB] [“average speed(MiB/s)”=0.5922591735614775]
[2022/03/26 11:26:49.691 +08:00] [INFO] [status.go:37] [progress] [tables=“109/110 (99.1%)”] [“finished rows”=408907071] [“estimate total rows”=629806175] [“finished size”=46GB] [“average speed(MiB/s)”=0.584776183484279]
基本上2分钟0.05G导出,已经导了12个小时了,这才导出46G
是我这参数有问题吗?
CAICAI
(Fengzhencai)
7
CAICAI
(Fengzhencai)
11
去掉-F也不行,average speed(MiB/s)"=2.650334930539276 还是很慢,主要是遇到那个大表的时候,就慢了,测试环境,负载也不高,不知道这个瓶颈是在哪
[2022/03/26 15:05:30.630 +08:00] [INFO] [status.go:37] [progress] [tables=“103/110 (93.6%)”] [“finished rows”=24759755] [“estimate total rows”=629806548] [“finished size”=12.1GB] [“average speed(MiB/s)”=2.650334930539276]
[2022/03/26 15:07:30.630 +08:00] [INFO] [status.go:37] [progress] [tables=“103/110 (93.6%)”] [“finished rows”=27108172] [“estimate total rows”=629806548] [“finished size”=12.39GB] [“average speed(MiB/s)”=2.3419644224072664]
[2022/03/26 15:09:30.629 +08:00] [INFO] [status.go:37] [progress] [tables=“104/110 (94.5%)”] [“finished rows”=29195526] [“estimate total rows”=629806548] [“finished size”=12.65GB] [“average speed(MiB/s)”=2.071752619906276]
h5n1
(H5n1)
12
estimate total rows”=629806548 ,大表450G, 这个大小怎么算出来的,表里有什么特殊字段吗,6.2亿的表一般不至于能到450G吧。 也可能历史版本过多
CAICAI
(Fengzhencai)
13
这个表存的是Json数据,虽然一行数据,但是一行里面的json数据存的内容可多了,整一行的数据大小还是蛮大的
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。