亲爱的 TiDB 用户,如果你有在使用 TiFlash,并且觉得还行(或者还可以拯救一下),现在可以来帮助它变得更好啦~
问题背景
我们(TiFlash 的研发)最近在斟酌一个具体的问题:TiFlash 的压缩率是不是不够好。可能有些同学会注意到,同一张表,同步了 TiFlash 副本之后,TiFlash 1 副本的数据量可能会比 TiKV 1 副本的数据量要大。
说好的列存压缩率更高的,怎么比行存还差???
确实是 …… 咱们工作不到位 Orz。这里边其实有两个原因:
- TiFlash 的逻辑分裂造成数据空间浪费。
TiFlash 的存储层,会对数据进行物理分片(Segment)存储,Segment 过大之后,需要进行分裂。然后我们在早期的研发过程中,为了减少 Segment 的分裂造成的写放大,所以使用了逻辑分裂。简单来说,它不是真正的分裂,只是分裂出来的新的两个 Segment 分别引用了旧的文件(类似文件系统的 hard link)。这似乎很机智,因为分裂不用做文件重写了。但是带来一个问题:如果后续有只有一个 Segment 更新了它的文件,那么另外一个 Segment 就引用了两份数据,这两份数据其中有一份是无用的。在极端情况下,会有 50% 的数据是无效数据,即空间浪费。
在 6.0 之后,TiFlash 默认不使用逻辑分裂。并且经过各种测试,发现除了写放大系数变高了一点,大概增加了 10% 的 IO 量,其他各项性能指标没有明显变化。反而其中一个 读+写 的场景,读 QPS 有 10% 以上提升。你说气不气?我们研究了一下,读+写 场景的性能提升的主要原因是,减少了无效数据的读取,并且避免了逻辑分裂带来的复杂逻辑。
6.0 的之前版本,可以通过设置以下配置 来禁用逻辑分裂,来达到一样的效果。
[profiles.default].dt_enable_logical_split = false
- TiFlash 使用的压缩算法的压缩率没有 TiKV 好
TiFlash 默认是用 lz4 -1 压缩算法,而 TiKV 主要使用 zstd -3。虽然对不同数据集有不同的效果,但是后者通常有更好的压缩率,具体可以看这里 https://github.com/facebook/zstd 。
但是 TiFlash 选择 lz4 也是有苦衷的啊!解压缩效率要够快,查询才能跑的快呀!
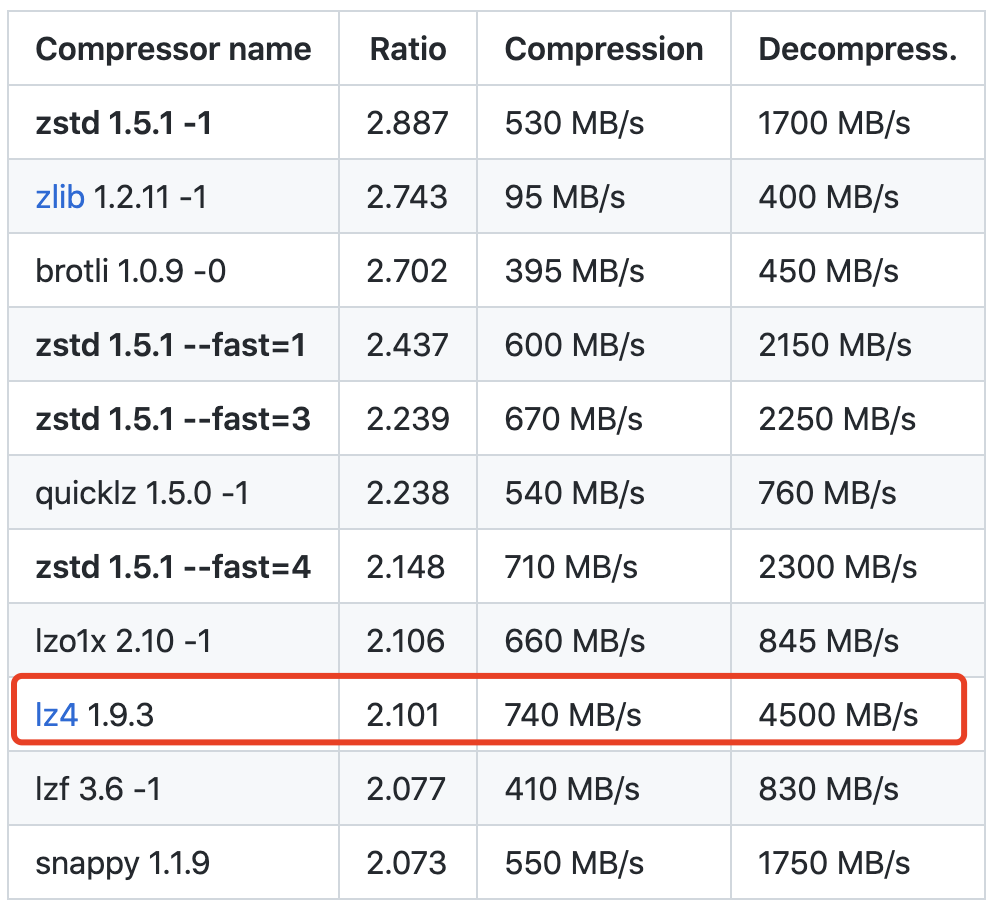
所以,即使我们已经把逻辑分裂关闭了,在某些场景(比如 ch-benchmark)也还是观察到 TiFlash 副本的数据量比 TiKV 要大。那 TiFlash 如果换成其他的压缩算法,表现会如何呢?来测试一波:
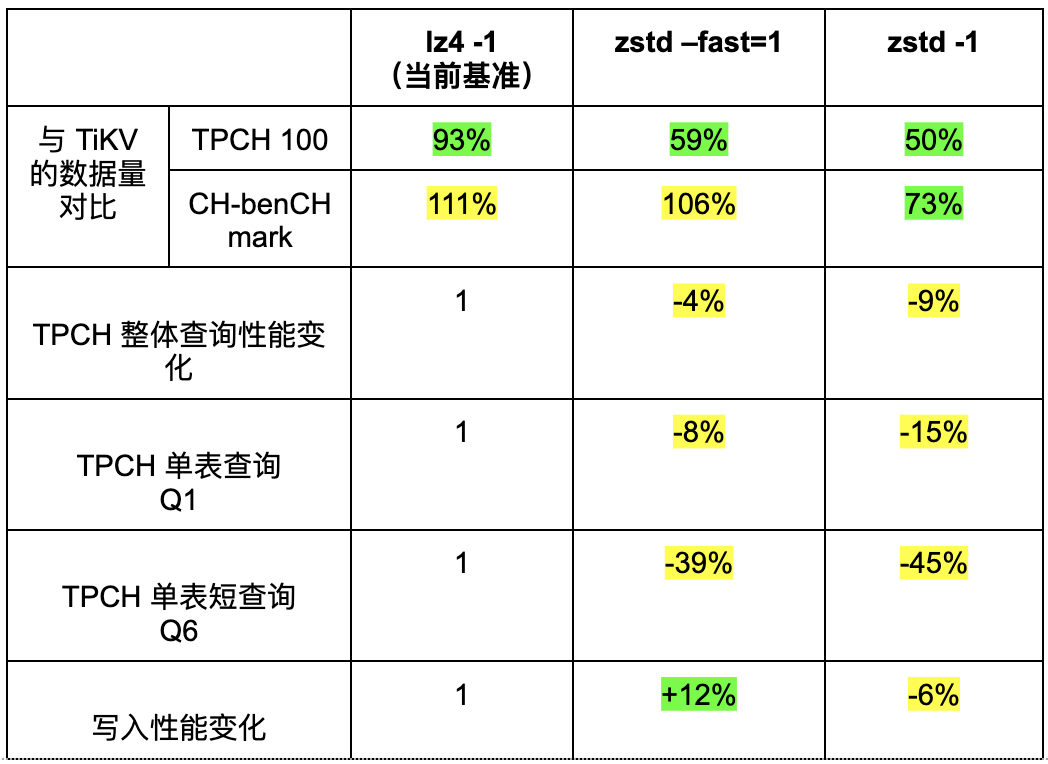
聪明的你应该看出来我们的纠结了。 压缩率越高,数据量越小,性能越差 。所以选哪个呢?好吧,咱都要!
从 6.0 开始,TiFlash 会增加以下参数,支持配置不同的压缩算法,目前支持
[profiles.default].dt_compression_method = lz4 # 压缩算法,支持 lz4、lz4hc 和 zstd,
[profiles.default].dt_compression_level = 1 # 压缩等级,需要参考各自压缩算法的等级规则
调研内容
虽然我们可以通过修改配置来自定义压缩算法来适配不同的场景。但是作为一个有追求的数据库,希望能有一个最合适的默认配置。
希望路过的各位,如果咱们 TiDB 集群有开启 TiFlash 副本,帮忙回答几个问题:
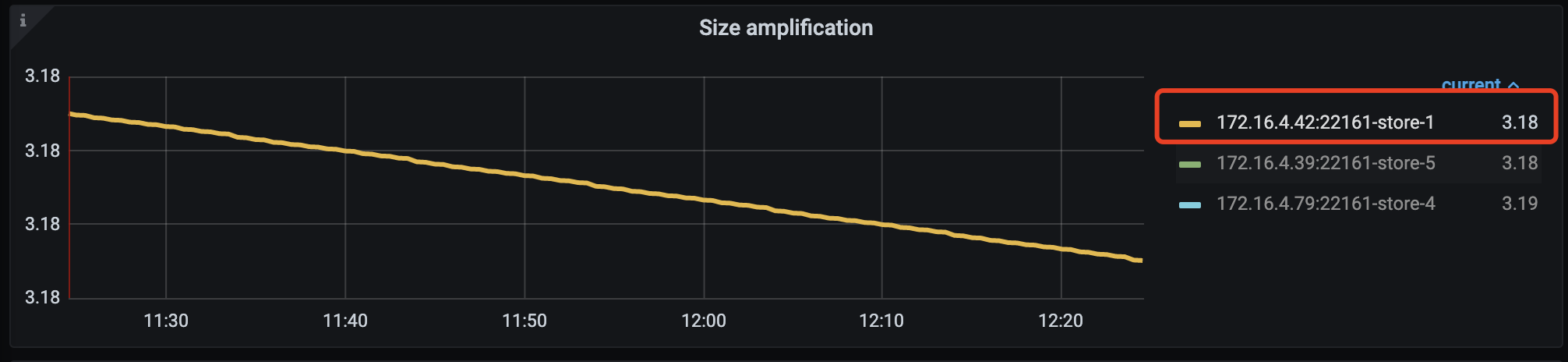
- 打开 TiDB 的 Grafana 监控,然后选择 PD 监控,Statistics - balance / Size amplification 面板,选择 store number 最小的那个,然后把数据记录下来。比如下面可以获得 tikv_compress_ratio: 3.18。
- 打开 mysql-client 连接上你的集群,把下面的 SQL 的 ’ chbenchmark ’ 改成 有 TiFlash 副本的数据量最多的 数据库名 ,然后执行。SQL 只会读取元数据,不会影响线上性能。
SELECT TRUNCATE(sum(tikv_total_size), 0) AS tikv_total_size_MB,
TRUNCATE(sum(tiflash_size_on_disk) * 1.1, 0) AS tiflash_total_size_on_disk_MB,
TRUNCATE(sum(tiflash_waste_size_on_disk), 0) AS tiflash_total_waste_size_on_disk_MB,
TRUNCATE((sum(tikv_total_size)/ sum(tiflash_size_on_disk * 1.1)), 2) AS tiflash_compress_ratio
FROM (WITH TiKV_T AS
( SELECT A.TABLE_ID TABLE_ID,
A.TABLE_SIZE tikv_total_size,
B.REPLICA_COUNT REPLICA_COUNT
FROM
(SELECT *
FROM information_schema.TABLE_STORAGE_STATS
WHERE table_schema IN ('chbenchmark')) A
JOIN
(SELECT table_id,
REPLICA_COUNT
FROM information_schema.tiflash_replica) B ON A.TABLE_ID = B.TABLE_ID ),
TiFlash_T AS
( SELECT TABLE_ID,
((8192 - avg(AVG_PACK_ROWS_IN_STABLE)) / 8192) * (sum(TOTAL_STABLE_SIZE_ON_DISK) / 1024 / 1024) AS tiflash_waste_size_on_disk ,
sum(TOTAL_STABLE_SIZE_ON_DISK) / 1024 / 1024 AS tiflash_size_on_disk
FROM information_schema.tiflash_tables
WHERE tidb_database IN ('chbenchmark')
GROUP BY TABLE_ID )
SELECT TiKV_T.tikv_total_size AS tikv_total_size,
TiFlash_T.tiflash_size_on_disk / TiKV_T.REPLICA_COUNT AS tiflash_size_on_disk,
TiFlash_T.tiflash_waste_size_on_disk / TiKV_T.REPLICA_COUNT AS tiflash_waste_size_on_disk
FROM TiKV_T
JOIN TiFlash_T ON TiKV_T.TABLE_ID = TiFlash_T.TABLE_ID) B \G
执行结果长这样:
tikv_total_size_MB: 252119
tiflash_total_size_on_disk_MB: 93279
tiflash_total_waste_size_on_disk_MB: 4546
tiflash_compress_ratio: 2.97
- 然后把上面的结果整理一下,并回复本帖子。如果你有多个数据集那就更好了!可以写多几份。示例:
数据库名(选填):chbenchmark
TiDB 版本:5.4.0
运行环境: 本地部署 # 选项:本地部署,阿里云、aws 等)
tikv_total_size_MB: 252119
tiflash_total_size_on_disk_MB: 93279
tiflash_total_waste_size_on_disk_MB: 4546
tiflash_compress_ratio: 2.97
tikv_compress_ratio (从Grafana 获取): 3.18
你希望的 TiFlash 默认压缩算法和等级: zstd --fast=1 # 选项:lz4 -1, zstd --fast=1, zstd -1 或者你建议的其他算法
你最期待 TiFlash 优化的点,或者新功能: xxxx # 来都来了,多提点要求吧……
参与调研回复的内容包含
【TiDB 版本】
【运行环境】本地部署 / 云环境
【tikv_total_size_MB】
【tiflash_total_size_on_disk_MB】
【tiflash_total_waste_size_on_disk_MB】
【tiflash_compress_ratio】
【tikv_compress_ratio (从Grafana 获取)】
【你希望的 TiFlash 默认压缩算法和等级】 zstd --fast=1 # 选项:lz4 -1, zstd --fast=1, zstd -1 或者你建议的其他算法
【你最期待 TiFlash 优化的点或者新功能】
(如果不方便把数据放在帖子里,可以私信我)
参与调研奖励
100 经验值&积分。