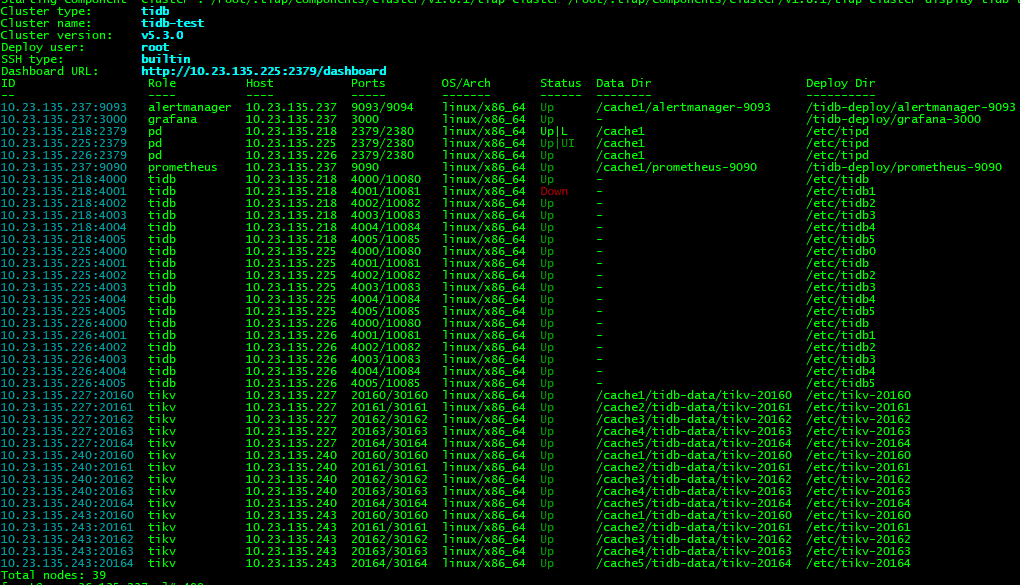
想请教下大佬使用TiDB的经验,这样的集群规模,执行的SQL延时在这个级别算正常吗?
前端业务测试的压力也不大,总共100并发左右,每个都会走以上几条SQL,没怎么看到其他人使用的情况,所以对TiDB性能能到多少没什么了解。
2 个赞
这速度很好啊
1 个赞
毫秒级,性能不错啊
1 个赞
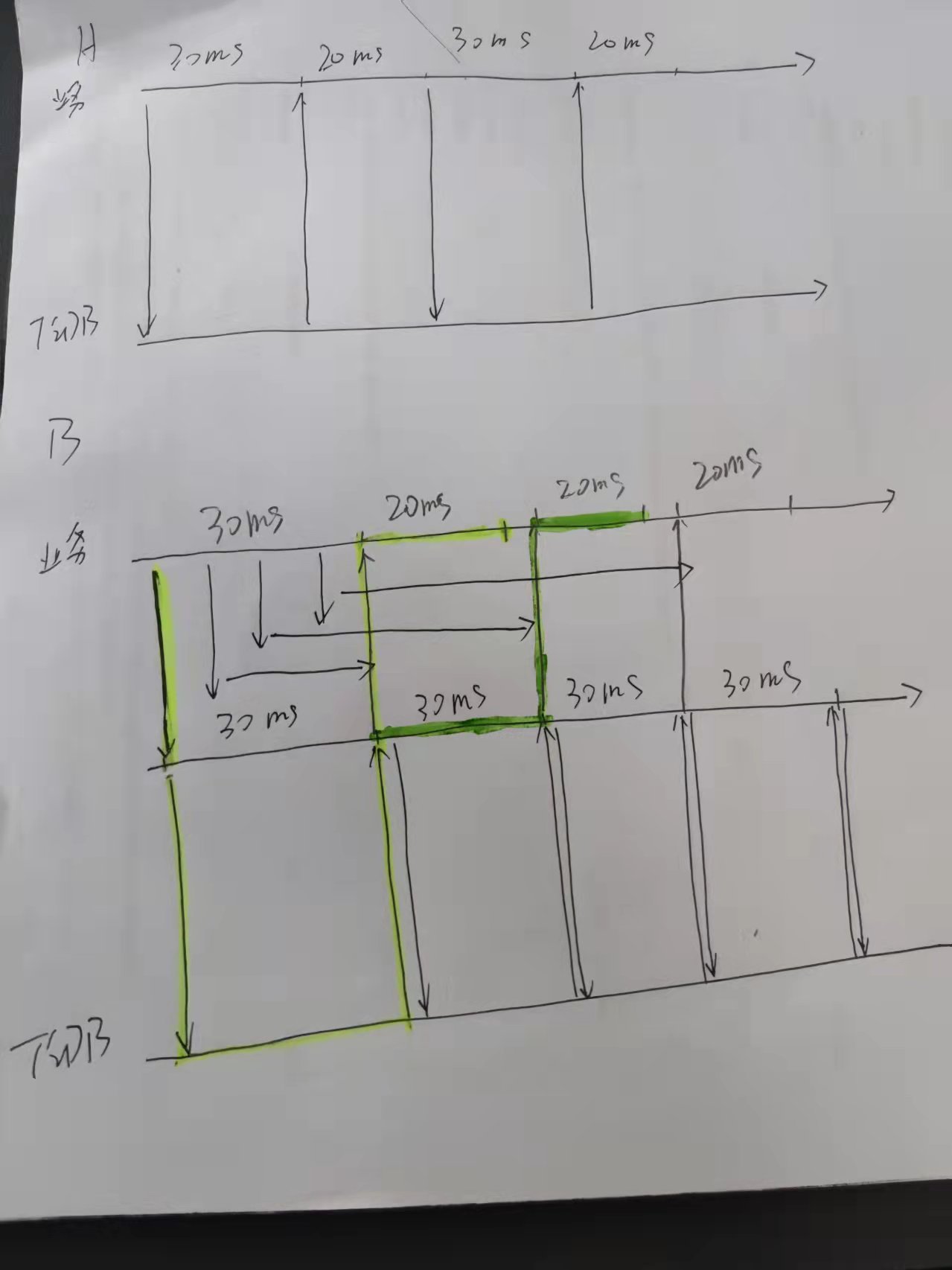
![]() 我们业务本来的时间是十几ms,改造后增加了tidb的时间,延时一下增加了30-40ms
我们业务本来的时间是十几ms,改造后增加了tidb的时间,延时一下增加了30-40ms
1 个赞
我们希望能更好,最好每条语句在3ms内,对于事务型数据库,是不是要求有点高?
1 个赞
这是来炫一波吗
1 个赞
大佬怎么讲?![]()
1 个赞
生产上跑这样,比我们的秀的多
1 个赞
还在测试。tidb是做为文件的索引存储的,目前小文件业务耗时大头都在tidb,大文件虽然也有这部分消耗,但相比IO耗时总体影响不大
1 个赞
什么场景需要这么严苛的时延要求?就算是单实例的mysql,我也很少见到这个级别,我们用户体验设计的时候,硬性要求是3s,希望不是弄错了单位,而且分布式系统两个衡量指标,吞吐量、处理速度,你面对的场景,可不可以通过线性扩展,增加吞吐量实现?
1 个赞
我们是对原有的对象存储系统改造,把对象的元数据存储到TiDB,原有的系统小文件的延时很小只有20ms,但在海里对象时存在不稳定的因素,改造后相同的并发要50ms,增加的延时都是TiDB 执行事务内的SQL语句,对小文件来说代价有点大,是否可以通过增加TiDB的tikv-server节点来降低延时,不过感觉做为事务型的数据库延时不可能非常低,并发上来就会增加事务的碰撞,我理解是这样的。
延时我觉得不可能降低了,或者换个思路会好一些,现在面对的问题是什么?是客户端体验整体降低了么?
我们说并发能力,比如说一个实例,处理每个文件20ms,简单的讲理论上每秒处理50个请求,原来有20个实例提供服务,每秒整体是1000个并发,应对目前这个情况,处理每个文件50ms,扩容为50个实例,每秒整体是1000个并发,我是说这种线性扩展。这种情况下,投入资源变多了,有代价的增强了稳定性。
其实,我有个建议,获取元数据和获取实际文件之间采用异步回调的方式,会不会提高效率?
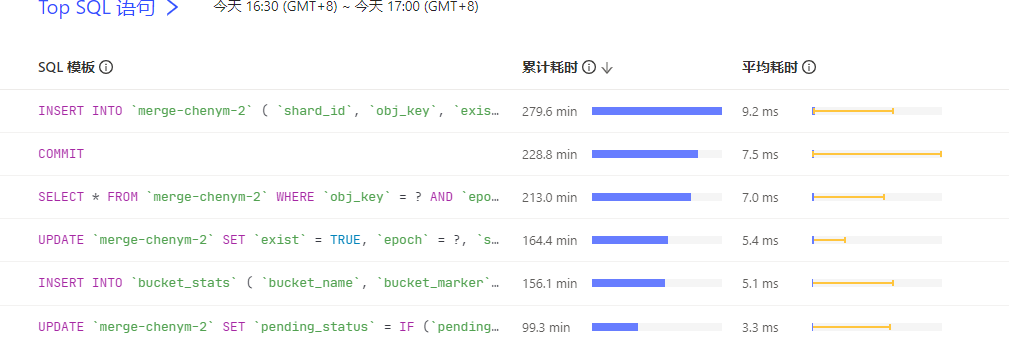
平均耗时就毫秒而已挺好的吧,单表数据大概有多少了
让人羡慕的性能了。
这配置真不错
1 个赞
应该可以更好,只是优化太需要深入到代码和业务模型了,我们之前优化数据库,深入到每个交易的每个SQL,索引,事务模型等等。太费时间了
我觉得对
我觉得分布式在纯粹的执行时间上去搞极限性能意义不大,而是在数据量逐渐大起来,并发高起来之后去体现对于单机数据库的优势,题注这个性能已经很好了吧
1 个赞
即便是IBM 主机DB2,一个普通的查询也要几十毫秒,过于追求速度没有太多的必要,任何性能的提升都是有代价的。