为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
5.0.2
【概述】 场景 + 问题概述
根据教程完成了ticdc sink到kafka的配置。
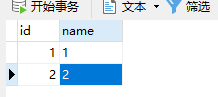
这是tidb单表
通过flink 创建kafka流式表
格式是canal-json
jar是 flink-kafka-cdc
这是flink创建完成的表
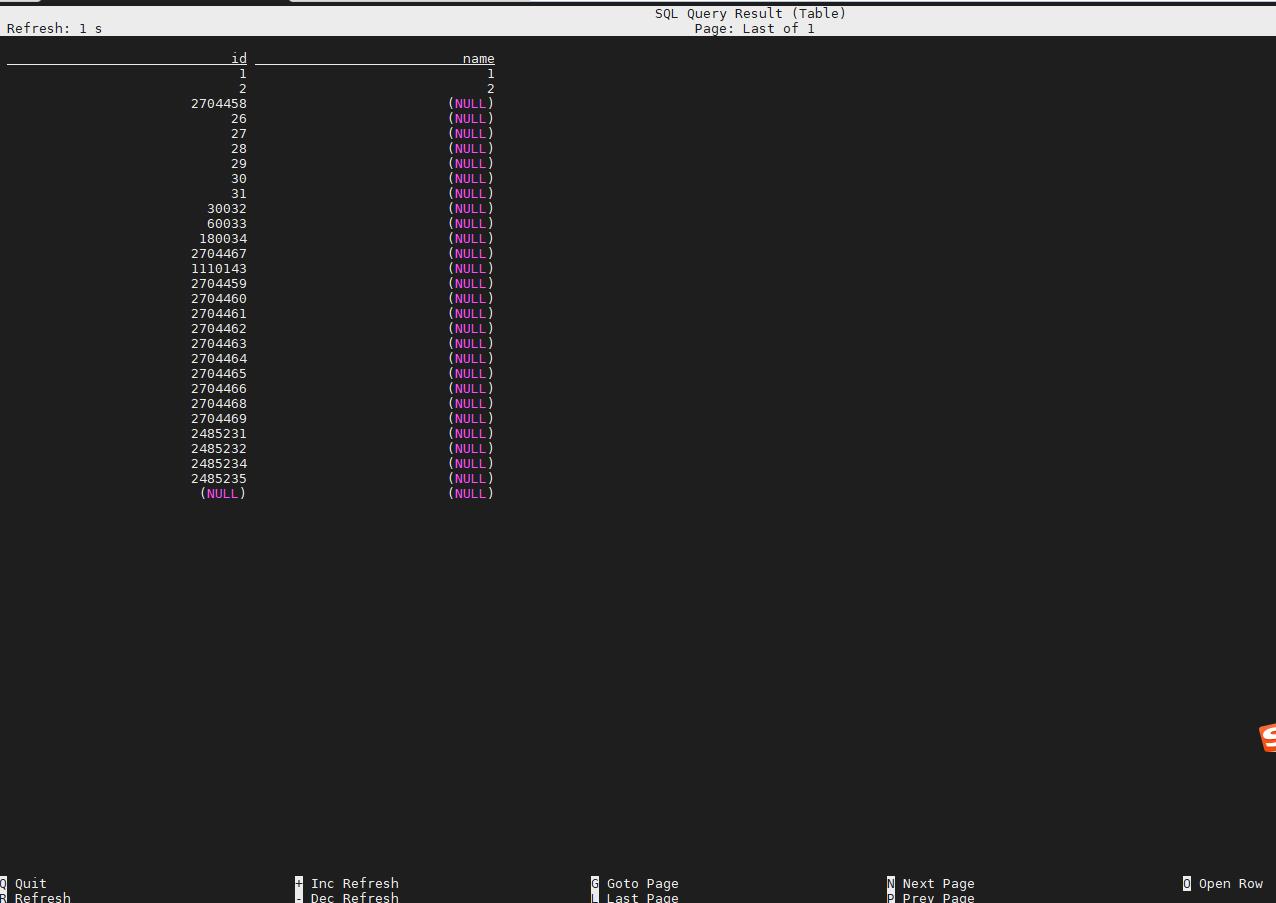
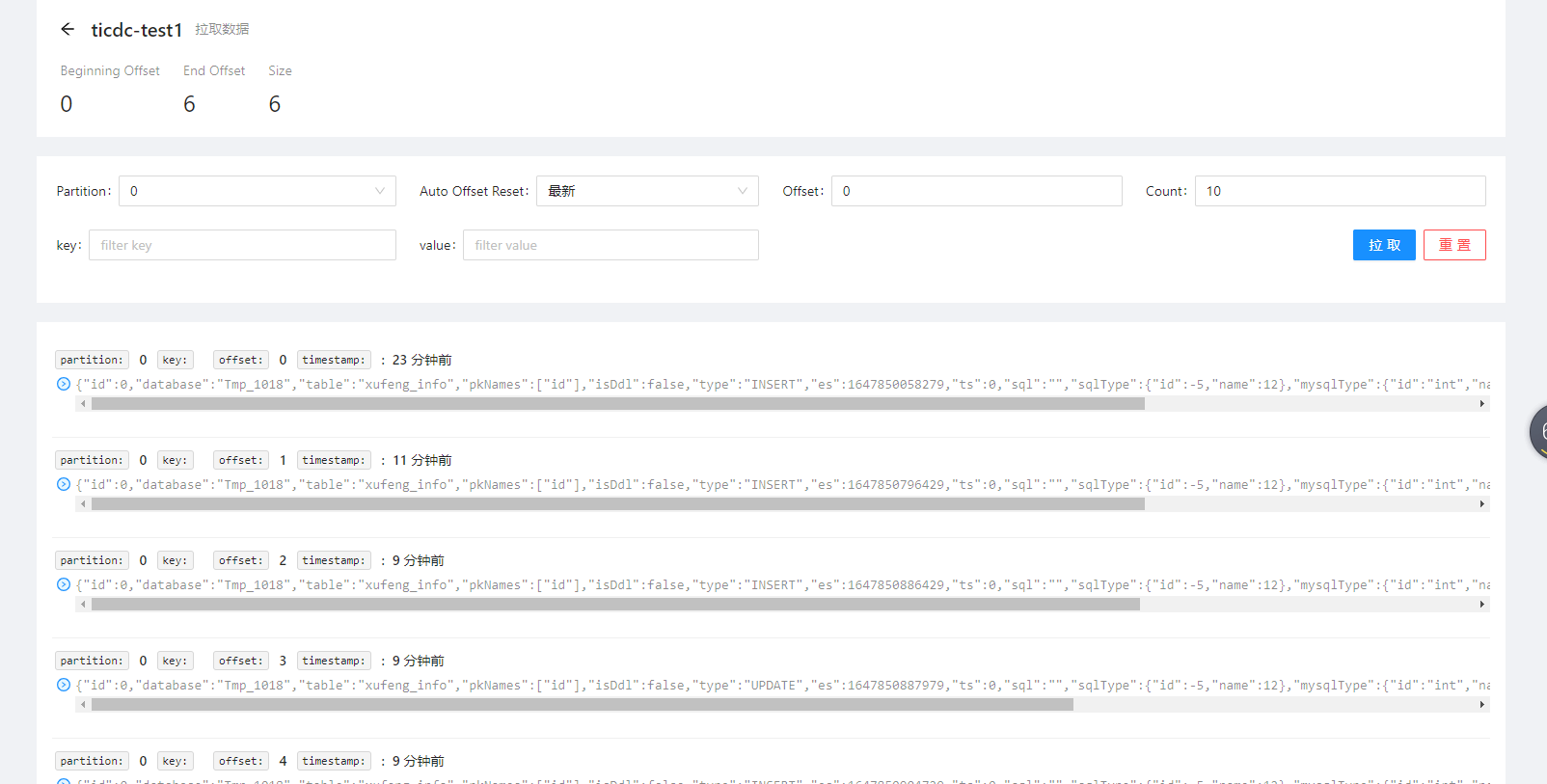
出现很多null 以及 id为 2******* 的空数据
请问需要怎么处理无用这些数据呢
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
5.0.2
【概述】 场景 + 问题概述
根据教程完成了ticdc sink到kafka的配置。
这是tidb单表
通过flink 创建kafka流式表
格式是canal-json
jar是 flink-kafka-cdc
这是flink创建完成的表
出现很多null 以及 id为 2******* 的空数据
请问需要怎么处理无用这些数据呢
上面的问题是指,原 TiDB 集群中,目标表只有 id 为 1,2 的两条记录,但是下游会出现『其他异常数据』吗?
如果是,那么请提供下下面的信息,我们一起看下:
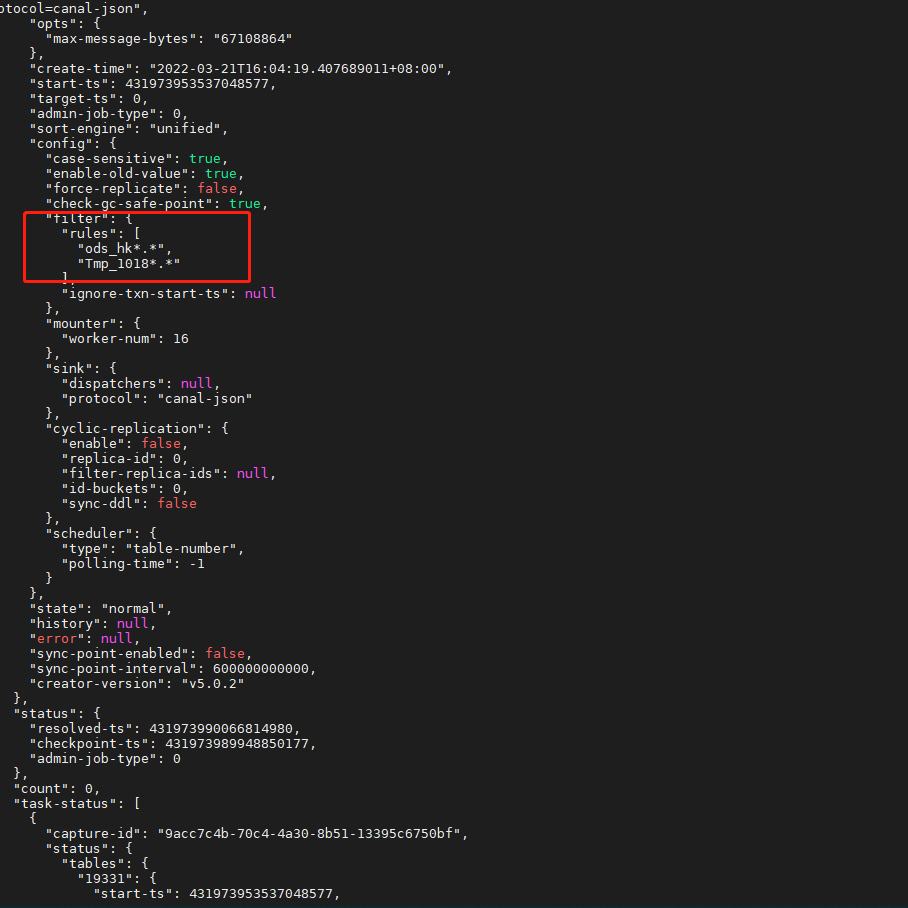
cdc 的 sink 端的配置
cdc 查询下目标 changfeed 信息,参考命令:
cdc cli changefeed query --pd=http://10.0.10.25:2379 --changefeed-id=simple-replication-task
查询下 kafka 中对应的 topic 中该表相关的数据,辛苦输入到 log 文件中
flink table 表结构信息
先说结论:问题已经解决。
我看了你的说法。因为所有库日志太多。我重新配置了相关库重新创建同步任务。
创建命令
现在topic json 正常
现在恢复了。先完结此贴
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。