为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
centos7.5+tidb v4.0.13
【概述】场景+问题概述
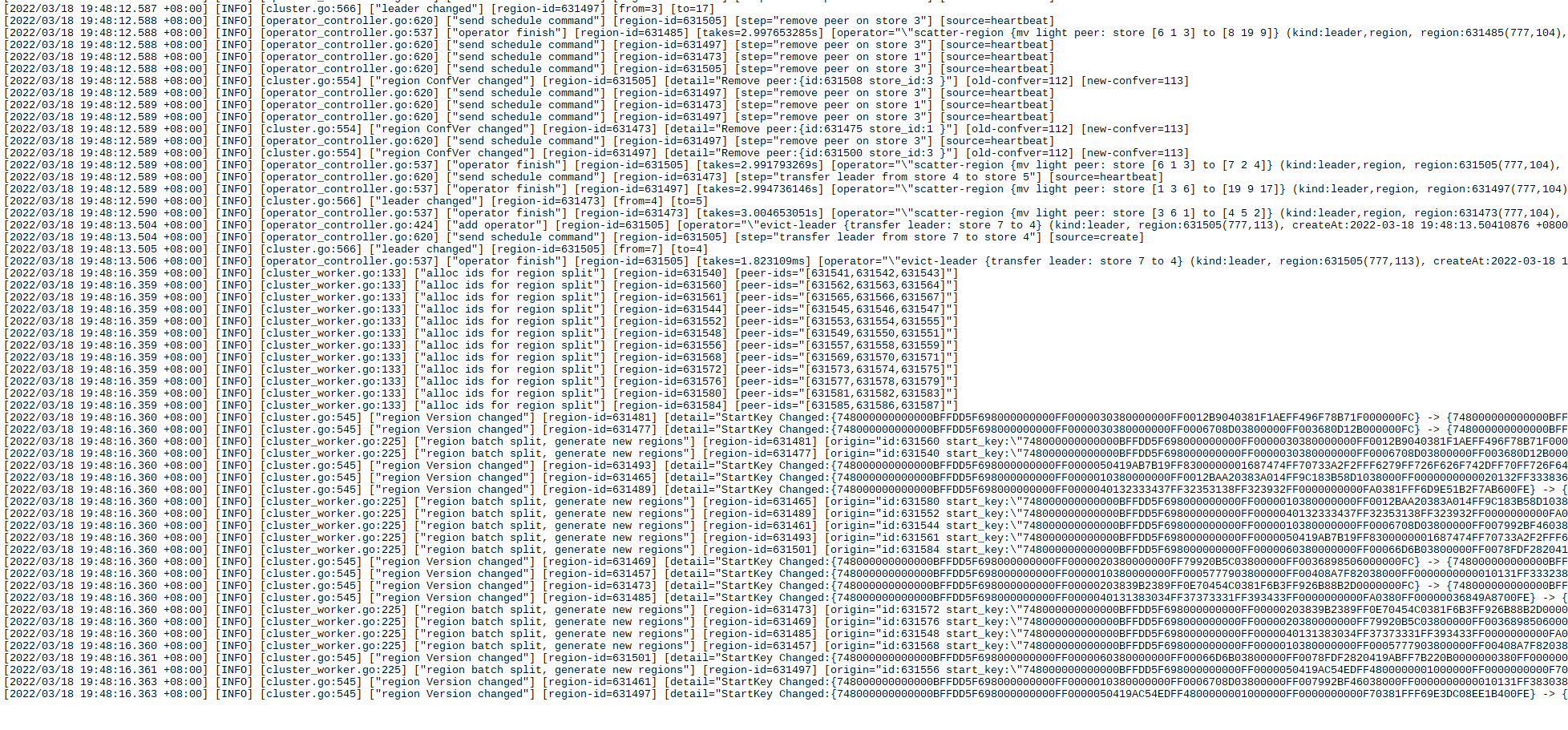
tidb-lightning导入数据,pd server挂了
附件有日志,pd.log为最后1千行数据
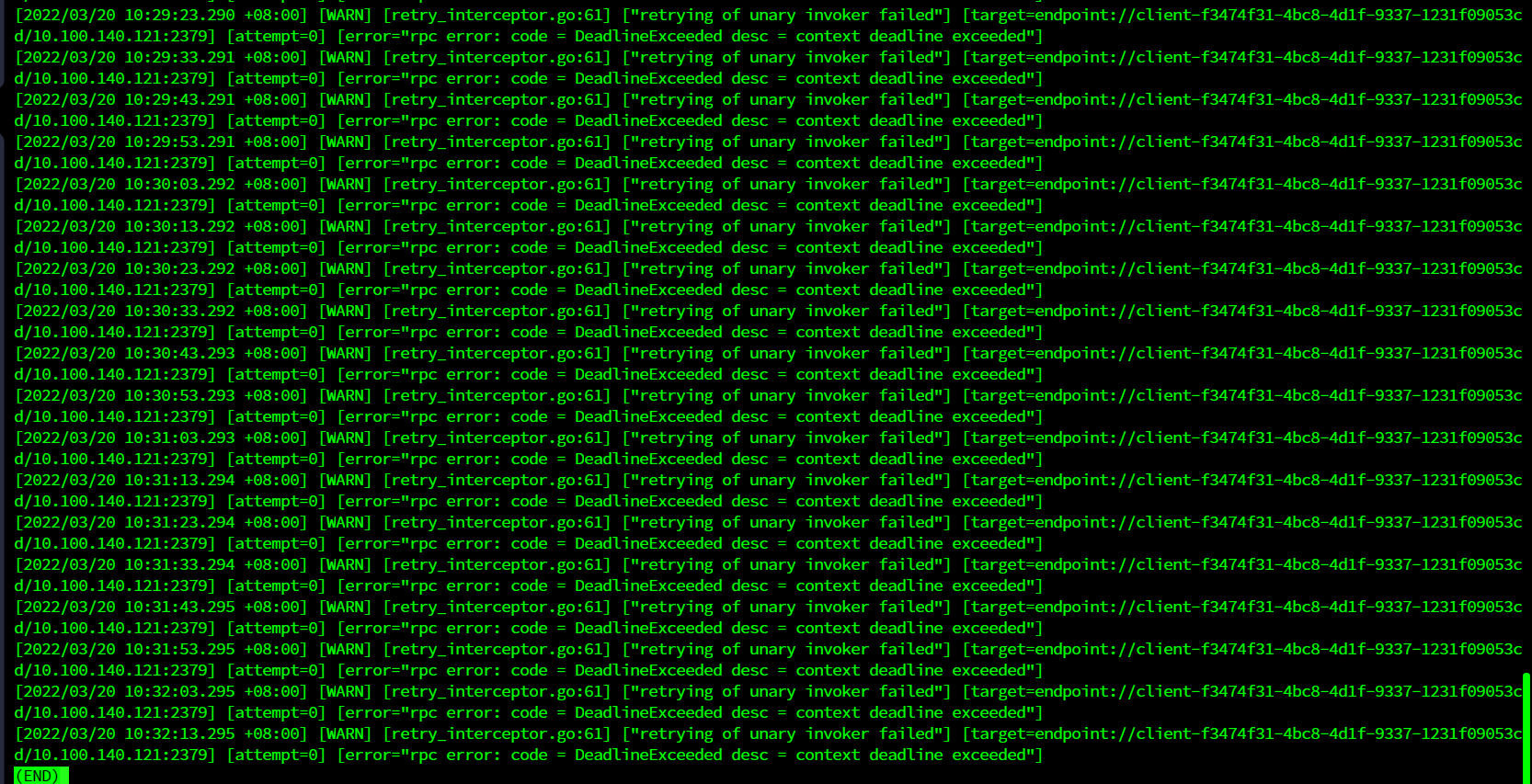
重启pd报错context deadline exceeded
【背景】做过哪些操作
tidb-lightning导入数据
【现象】业务和数据库现象
重启报错如下:
【业务影响】
【TiDB 版本】
【附件】
pd_stderr.log.gz (4.3 MB)
pd.log.gz (20.0 KB)
-
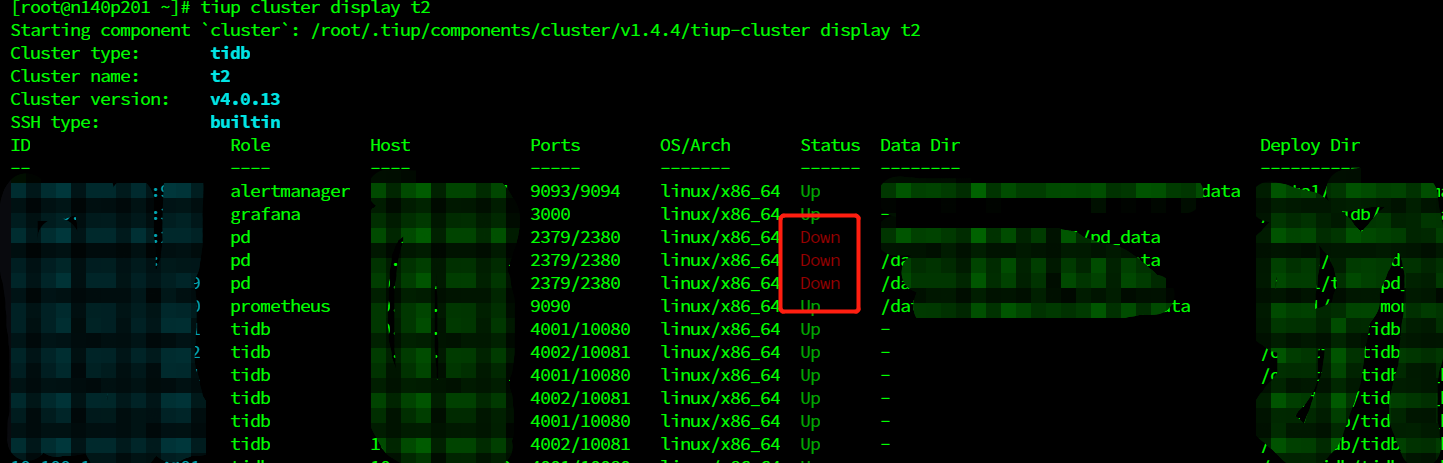
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
1 个赞
xfworld
(魔幻之翼)
2
这个日志描述的内容不太够,没法判断(日志给的是3月18号的)
能描述下你的操作场景和环境配置信息么?
1 个赞
server_configs:
tidb:
enable-telemetry: false
log.enable-slow-log: true
log.file.max-backups: 1000
log.file.max-days: 31
log.level: info
log.record-plan-in-slow-log: 1
log.slow-threshold: 200
max-server-connections: 100000
mem-quota-query: 5368709120
oom-action: cancel
oom-use-tmp-storage: true
performance.committer-concurrency: 32
performance.max-procs: 32
performance.max-txn-ttl: 600000
performance.run-auto-analyze: true
performance.stats-lease: “0”
performance.stmt-count-limit: 10000
performance.txn-total-size-limit: 10737418240
pessimistic-txn.enable: true
pessimistic-txn.max-retry-count: 128
prepared-plan-cache.enabled: true
split-table: false
stmt-summary.max-stmt-count: 1000
tikv-client.grpc-connection-count: 8
tikv-client.max-batch-wait-time: 2000000
tikv-client.region-cache-ttl: 300
tmp-storage-path: /opt/tidb/tmp
tmp-storage-quota: 107374182400
token-limit: 20000
1 个赞
tikv:
batch-split-limit: 24
log-level: info
pessimistic-txn.enable: true
pessimistic-txn.pipelined: true
raftdb.allow-concurrent-memtable-write: true
raftdb.defaultcf.level0-slowdown-writes-trigger: 100
raftdb.defaultcf.level0-stop-writes-trigger: 200
raftdb.defaultcf.max-write-buffer-number: 10
raftdb.defaultcf.write-buffer-size: 512MiB
raftdb.max-background-flushes: 4
raftdb.max-background-jobs: 16
raftdb.max-sub-compactions: 12
raftstore.apply-pool-size: 8
raftstore.hibernate-regions: true
raftstore.store-pool-size: 8
raftstore.sync-log: true
readpool.coprocessor.high-concurrency: 32
readpool.coprocessor.low-concurrency: 24
readpool.coprocessor.normal-concurrency: 24
readpool.storage.high-concurrency: 24
readpool.storage.low-concurrency: 8
readpool.storage.normal-concurrency: 16
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 24
readpool.unified.min-thread-count: 12
rocksdb.defaultcf.hard-pending-compaction-bytes-limit: 256GiB
rocksdb.defaultcf.level0-slowdown-writes-trigger: 100
rocksdb.defaultcf.level0-stop-writes-trigger: 200
rocksdb.defaultcf.max-write-buffer-number: 10
rocksdb.defaultcf.soft-pending-compaction-bytes-limit: 64GiB
rocksdb.defaultcf.write-buffer-size: 512MiB
rocksdb.lockcf.level0-slowdown-writes-trigger: 100
rocksdb.lockcf.level0-stop-writes-trigger: 200
rocksdb.lockcf.max-write-buffer-number: 10
rocksdb.lockcf.write-buffer-size: 64MiB
rocksdb.max-background-flushes: 4
rocksdb.max-background-jobs: 16
rocksdb.max-sub-compactions: 6
rocksdb.raftcf.level0-slowdown-writes-trigger: 200
rocksdb.raftcf.level0-stop-writes-trigger: 400
rocksdb.raftcf.max-write-buffer-number: 10
rocksdb.raftcf.write-buffer-size: 512MiB
rocksdb.writecf.hard-pending-compaction-bytes-limit: 256GiB
rocksdb.writecf.level0-slowdown-writes-trigger: 200
rocksdb.writecf.level0-stop-writes-trigger: 400
rocksdb.writecf.max-write-buffer-number: 10
rocksdb.writecf.soft-pending-compaction-bytes-limit: 64GiB
rocksdb.writecf.write-buffer-size: 512MiB
server.grpc-compression-type: gzip
server.grpc-concurrency: 12
server.grpc-memory-pool-quota: 12GiB
server.grpc-raft-conn-num: 2
server.request-batch-enable-cross-command: false
server.snap-max-write-bytes-per-sec: 1GB
storage.block-cache.capacity: 64GiB
storage.scheduler-concurrency: 524288
storage.scheduler-worker-pool-size: 8
pd:
dashboard.enable-telemetry: false
force-new-cluster: false
log-level: info
log.file.max-backups: 200
log.file.max-days: 31
log.file.max-size: 1024
quota-backend-bytes: 549755813888
replication.enable-placement-rules: true
replication.location-labels:
- zone
- rack
- host
replication.max-replicas: 3
schedule.hot-region-cache-hits-threshold: 2
schedule.hot-region-schedule-limit: 8
schedule.leader-schedule-limit: 8
schedule.max-merge-region-keys: 409600
schedule.max-merge-region-size: 48
schedule.max-pending-peer-count: 32
schedule.max-snapshot-count: 32
schedule.max-store-down-time: 15m
schedule.merge-schedule-limit: 16
schedule.patrol-region-interval: 20ms
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 128
schedule.split-merge-interval: 30min
schedule.tolerant-size-ratio: 20.0
新部署的环境,全都是物理机,6个tidb server,6个tikv,3个pd server,tikv和pd都是nvme ssd,在使用tidb-lightning导入之前做了sysbench压测,,之后导入大概3.1T的数据,有一些大表,导入挂后台了,第二天就发报错了
tidb集群版本4.0.13,tidb-lightning是5.4.0的
xfworld
(魔幻之翼)
10
这个版本跨度有点大,估计不太合适,建议你用低版本的 lightning 试试
推荐 5.0.X < version > 4.0.14
这个版本区间,4.0.13 有些bug别用,然后在 4.0.14 被修复了
system
(system)
关闭
12
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。