
把文档中的例子改了一下将一个43亿的hive表和tidb中的一个1亿的表jioin 结果集回写tidb
在执行到foreachPartition at TiBatchWrite.scala:291 的时候tikv的监控显示开始写入最初的写入速度是90MB每秒左右这个后来持续下降1。7个小时后只有30M左右 什么原因导致的
表上没有索引有一个tiflash的副本
1 个赞
TiBatchWrite.scala:291这个一行是干了这个事:

在两阶段提交中,secondaryKeys的加锁和写入操作,理论上这时候的慢跟几个因素可能有关:
1.spark某种原因并行的task减少
2.spark的executors因为长时间运行,shullfer压力过大
3.有没有读操作在干扰,产生了较多的锁冲突
4.其他磁盘干扰
建议几个方面的检查:
1.检查executors页面中的gc情况和disk溢出情况
2.检查导数期间有没有相关表的慢sql,或者查询明显变长
3.如果是虚机,跟虚机的运维沟通一下,宿主机的IO压力趋势是不是跟你的一样
另外,跟pd有没有关系,目前没想到直接的联系,因为在这个步骤之前就获取了tso和创建了region,也可能是没想到,参考一下pd的cpu和磁盘压力看看有没有关联
1 个赞
今天重新做了一下测试 新建了表 pre_split_region 设为8 开启spark加载数据
开始的时候写入速度一直很稳定在100M左右当空region没有之后写入速度开始下降同时磁盘的读突然开始上升,是不是这时候开始region的分裂导致写入速度下降。另外我们看到region的数量有一个下降和上升的过程这是一个测试环境没有别的复杂,是不是大量的空region倍merge了?请指教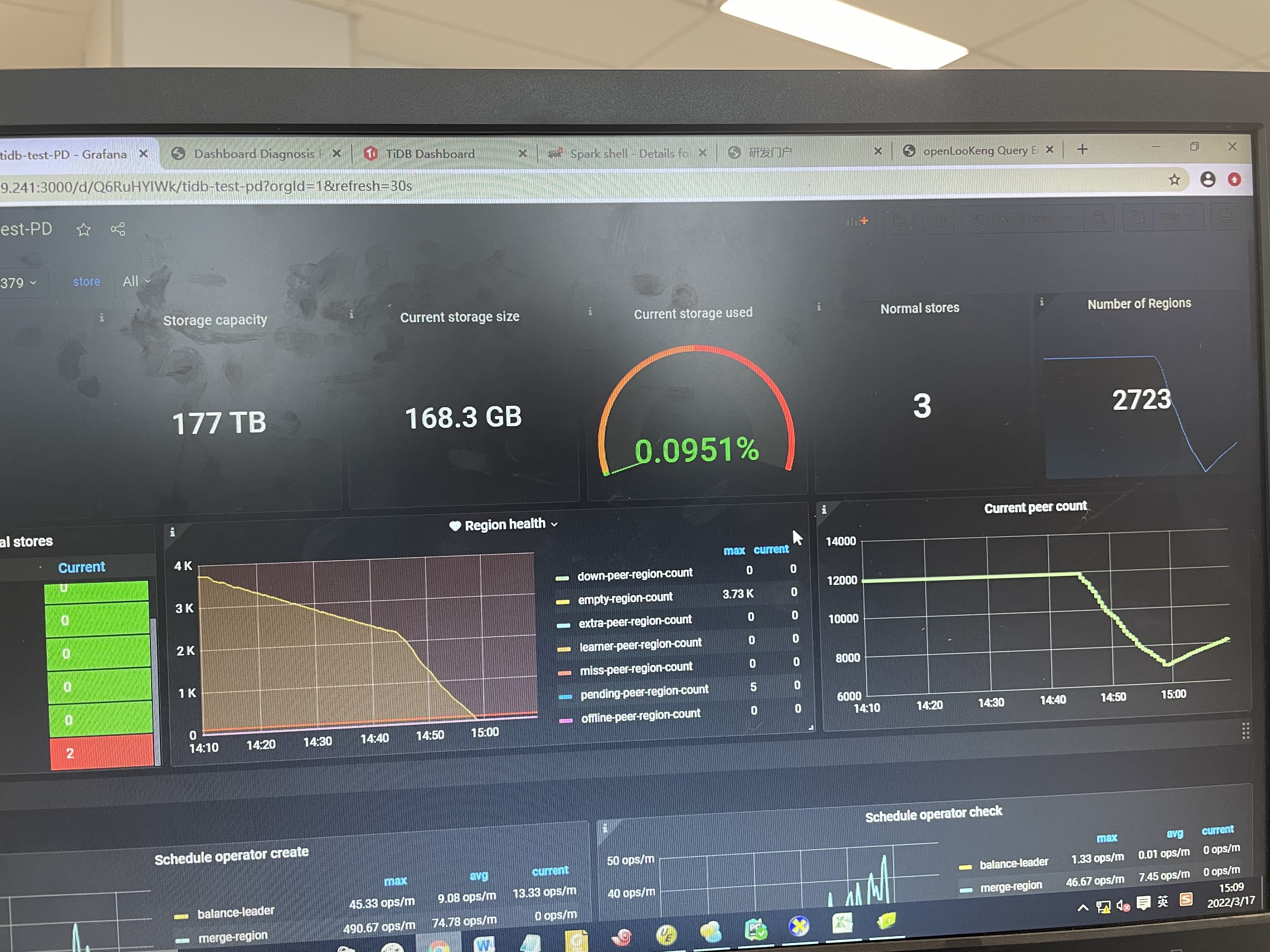

1 个赞
我对这个过程的推断:
1.空region确实是被merge了
2.tisaprk中对region的分割值是10万数据,或者96M,在这里96M的估算是在spark中估算的,我不太确定数据落地之后,会不会是一致的,如果region数据过大,会引起region分裂。
select AVG_ROW_LENGTH from information_schema.TABLES t where TABLE_NAME = ‘table_name’;
查一下这个,可以估算一下数据大小。
几个跟splite有关的默认值:
minRegionSplitNum:8 – 最小分割数量
maxRegionSplitNum:4096 – 最大分割数量
regionSplitThreshold:100000 – 分割步长
是spark中把空region merge了吗?分割步长是一个全局的设定而每个数据加载业务中的平均行长是不一致的无法找到一个普世的数值。
另外那几个默认值在哪里改 找不到相关的文档啊
是TiDB把空region merge了,spark没有那么大权利,![]() ,
,
判断region数据量,大体流程是这样的:
基础值基于RDD的partitions数量作为初始region数量
1.如果总体数据量小于10万,直接返回
2.判断partitions数量在不在最大和最小之间,调整到最大或者最小值
3.获取样本数据(后续计算数据大小用)
4.基于样本数据衡量partitions中数据存储大小,如果单partition数据存储过大,则调整rgion数量
5.判断partitions数量在不在最大和最小之间,调整到最大或者最小值
6.返回
解决问题的最好办法是读源码,![]()
1 个赞
观察了一下spakr入库时候的日志发现TwoPhaseCommitter阶段 prewrite secondary key row=27 size约为16K 如果将row 增大会不会增加入库效率 ,从主机测观察io占用率很高但是读写的速度毕竟并不是特别高最高只有100M左右。请教一下有哪些方法可以调整入库的批的大小看了一下源码 默认值是16K 由这个参数控制 TIDB_TXN_PREWITE_BATCH_SIZE
新的问题是这个参数是在哪设置的
val txnPrewriteBatchSize: Long = getOrDefault(TIDB_TXN_PREWITE_BATCH_SIZE, “16384”).toLong
// 16 * 1024 = 16K
val txnCommitBatchSize: Long = getOrDefault(TIDB_TXN_COMMIT_BATCH_SIZE, “16384”).toLong
// 32 * 1024
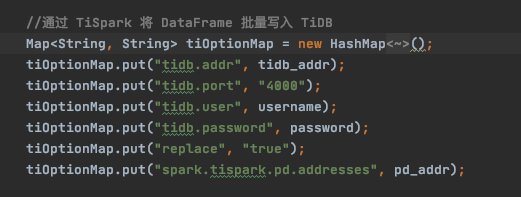
组织这个参数的时候传进去的,参数名应该是这个:txnCommitBatchSize
我这个参数名字,是从你的日志截图的位置的上一级方法里面找到的分割的参数,不是你找的那两个,我的是2.5.0版本

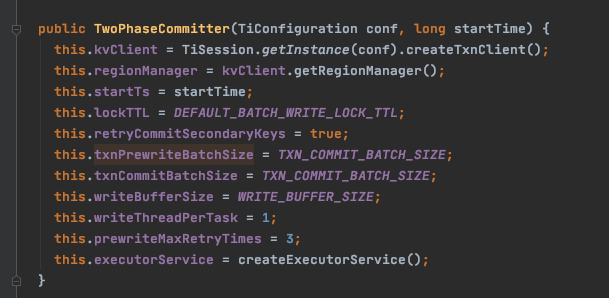
这个参数我看代码里面说明建议最大值是768*1024,所以调整时,建议不超过这个值,按照我的理解,不是批次越大越好,需要反复调整观察一下。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。