为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境
【概述】 场景 + 问题概述
未做配置调整,突然报错退出
【备份和数据迁移策略逻辑】
pump – drainer – kafka
【背景】 做过哪些操作
无运维操作(不排除有数据库脏数据因素)
【现象】 业务和数据库现象
同步中断
【问题】 当前遇到的问题
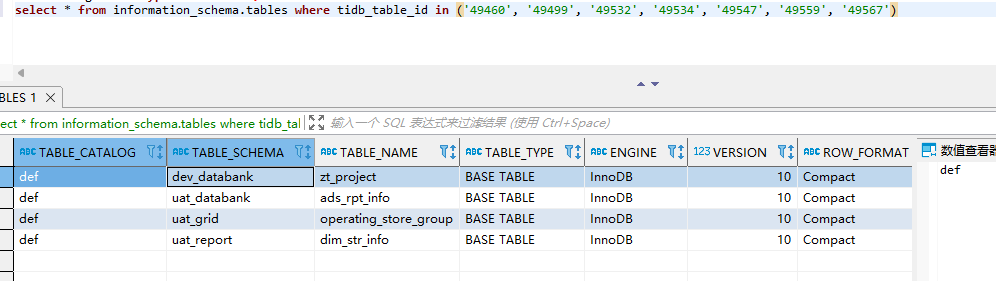
已经异常退出多次,报错是not found table id,但是根据table id有时找不到表,有时找能到表
找不到时:
curl http://tidb-server01:10080/schema?table_id=49499
[schema:1146]Table which ID = 49499 does not exist.
pump未发现ERROR级报错
【业务影响】
暂无
【TiDB 版本】
v4.0.4
【drainer日志】
[2022/03/15 15:06:49.261 +08:00] [INFO] [syncer.go:257] ["write save point"] [ts=431837150463918090]
[2022/03/15 15:07:15.314 +08:00] [INFO] [syncer.go:257] ["write save point"] [ts=431837158328238094]
[2022/03/15 15:07:44.544 +08:00] [INFO] [syncer.go:257] ["write save point"] [ts=431837166205665281]
[2022/03/15 15:14:59.591 +08:00] [INFO] [client.go:772] ["[sarama] client/metadata fetching metadata for [tidb-binlog-pre] from broker kafka01:9092\
"]
[2022/03/15 15:15:08.412 +08:00] [INFO] [syncer.go:257] ["write save point"] [ts=431837284236001287]
[2022/03/15 15:15:08.537 +08:00] [INFO] [async_producer.go:1015] ["[sarama] Producer shutting down."]
[2022/03/15 15:15:08.537 +08:00] [INFO] [client.go:227] ["[sarama] Closing Client"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [syncer.go:249] ["handleSuccess quit"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [broker.go:253] ["[sarama] Closed connection to broker kafka02:9092\
"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [async_producer.go:717] ["[sarama] producer/broker/1 input chan closed\
"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [broker.go:253] ["[sarama] Closed connection to broker kafka01:9092\
"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [async_producer.go:801] ["[sarama] producer/broker/1 shut down\
"]
[2022/03/15 15:15:08.537 +08:00] [ERROR] [server.go:289] ["syncer exited abnormal"] [error="filterTable failed: not found table id: 49499"] [errorVerbose="not found table id: 49499\
github.com/pingcap/tidb-binlog/drainer.filterTable\
\t/Users/weizheng/go/src/github.com/letusgoing/tidb-binlog/drainer/syncer.go:514\
github.com/pingcap/tidb-binlog/drainer.(*Syncer).run\
\t/Users/weizheng/go/src/github.com/letusgoing/tidb-binlog/drainer/syncer.go:368\
github.com/pingcap/tidb-binlog/drainer.(*Syncer).Start\
\t/Users/weizheng/go/src/github.com/letusgoing/tidb-binlog/drainer/syncer.go:132\
github.com/pingcap/tidb-binlog/drainer.(*Server).Start.func4\
\t/Users/weizheng/go/src/github.com/letusgoing/tidb-binlog/drainer/server.go:288\
github.com/pingcap/tidb-binlog/drainer.(*taskGroup).start.func1\
\t/Users/weizheng/go/src/github.com/letusgoing/tidb-binlog/drainer/util.go:71\
runtime.goexit\
\t/usr/local/go/src/runtime/asm_amd64.s:1374\
filterTable failed"]
[2022/03/15 15:15:08.537 +08:00] [INFO] [util.go:68] [Exit] [name=syncer]
[2022/03/15 15:15:08.537 +08:00] [INFO] [server.go:451] ["begin to close drainer server"]
[2022/03/15 15:15:08.540 +08:00] [INFO] [server.go:416] ["has already update status"] [id=drainer:8249]
[2022/03/15 15:15:08.540 +08:00] [INFO] [server.go:455] ["commit status done"]
[2022/03/15 15:15:08.540 +08:00] [INFO] [pump.go:77] ["pump is closing"] [id=pump03:8250]
[2022/03/15 15:15:08.541 +08:00] [INFO] [pump.go:77] ["pump is closing"] [id=pump02:8250]
[2022/03/15 15:15:08.540 +08:00] [INFO] [util.go:68] [Exit] [name=heartbeat]
[2022/03/15 15:15:08.541 +08:00] [INFO] [pump.go:77] ["pump is closing"] [id=pump01:8250]
[2022/03/15 15:15:08.541 +08:00] [INFO] [collector.go:135] ["publishBinlogs quit"]
[2022/03/15 15:15:08.541 +08:00] [INFO] [util.go:68] [Exit] [name=collect]
[2022/03/15 15:15:08.546 +08:00] [INFO] [main.go:73] ["drainer exit"]
【两个tidb-server都已开启binlog】
[binlog]
enable = true
ignore-error = true
write-timeout = "15s"
【drainer配置】
# WARNING: This file is auto-generated. Do not edit! All your modification will be overwritten!
# You can use 'tiup cluster edit-config' and 'tiup cluster reload' to update the configuration
# All configuration items you want to change can be added to:
# server_configs:
# drainer:
# aa.b1.c3: value
# aa.b2.c4: value
[syncer]
db-type = "kafka"
ignore-schemas = "INFORMATION_SCHEMA,METRICS_SCHEMA,PERFORMANCE_SCHEMA,aaa,aliprod119,bak_marketing_0925,dusto_job,goinception,mysql,stress_testing,test,test33,test55,thisaliprod,thisisuat,tidb_loader,txmanager,uat_databank,uat_goods,uat_grid,uat_info,uat_integration,uat_job,uat_marketing,uat_member,uat_message,uat_nacos,uat_order,uat_pay,uat_product,uat_report,uat_saga,uat_security,uat_stock,uat_support,uat_zipkin,pre_databank,pre_info,pre_job,pre_message,pre_nacos,pre_nacos113,pre_product,pre_report,pre_security,pre_support,dev_member,dev_databank,dev_message,dev_info,dev_order,dev_pay,dev_marketing,dev_report,dev_stock,dev_grid,dev_support,dev_security,dev_goods"
[[syncer.ignore-table]]
db-name = "test"
tbl-name = "test"
[[syncer.ignore-table]]
db-name = "pre_member"
tbl-name = "member_info_temp_20190925"
[syncer.to]
kafka-addrs = "kafka01:9092,kafka02:9092,kafka03:9092"
kafka-max-message-size = 1610612736
kafka-max-messages = 1536
kafka-version = "1.0.2"
topic-name = "tidb-binlog-pre"