什么是 TiDB 社区版主?
TiDB 社区版主:由TiDB社区中的用户、开发者、Contributor 以及合作伙伴共同组成,并拥有参与对 AskTUG 论坛管理及运营的权限。
关于话题讨论的内容来源?
版主交流群,是由一群热爱 TiDB 的版主、版主候选人及社区活跃小伙伴们组成的一个微信群,我们经常会在群里面交流 TiDB 技术问题,以便于更好地掌握 TiDB 的运维能力,更快速地帮助自己和他人处理 TiDB 问题,获得技术上的提升和成长。
本期话题
关于Numa 的探讨
TiDB 社区版主:由TiDB社区中的用户、开发者、Contributor 以及合作伙伴共同组成,并拥有参与对 AskTUG 论坛管理及运营的权限。
版主交流群,是由一群热爱 TiDB 的版主、版主候选人及社区活跃小伙伴们组成的一个微信群,我们经常会在群里面交流 TiDB 技术问题,以便于更好地掌握 TiDB 的运维能力,更快速地帮助自己和他人处理 TiDB 问题,获得技术上的提升和成长。
关于Numa 的探讨
来自 @jiawei 发起的讨论:
你们有没有测试过numa ?
我们一般都是关闭numa。但是官方课程有提到 numa绑定。可以提升性能
来自:@Gin_ 的回复:
numa 是硬件架构,关闭 numa 只是禁用了 numactl 而已
属于 bios 的自欺欺人
来自:@h5n1 的回复:
我是物理机混合部署
numa对于tps提升还是很有效果
来自 @jiawei 的回复:
numa绑定 看了一段时间 还是没有看明白 ,看官方讲避免了总线竞争消耗,但是没有具体的绑定方案
来自:@Gin_ 的回复:
numa 关不关,都不影响 cpu 访问远端的内存的低效率,硬件架构决定的
来自:@h5n1 的回复:
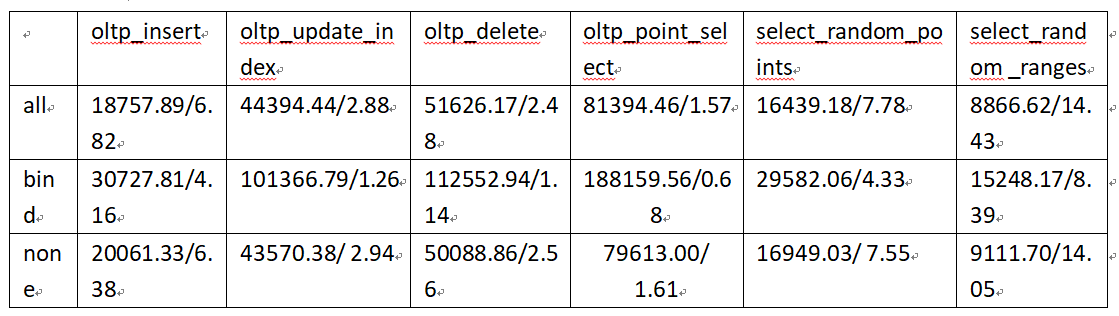
之前的测试结果
来自 @jiawei 的回复:
你压测的时候使用的默认的表结构吗 ?
我觉得如果表结构修改了 指定聚集表或者非聚集表应该性能会不一样
来自:@h5n1 的回复:
cpu访问远端node上的内存延迟比访问local要高
这是当时刚研究tidb时测的 还不懂啥auto_random shard_id
来自 @jiawei 的回复:
@彬彬 有技术文档分享下吗?
来自:@Gin_ 的回复:
每个 TiDB 服务器,有几个 numa node 就部署几个 tidb 实例,各自绑到 1 个 numa node 上,tikv 一般不需要绑,手册在这里 https://docs.pingcap.com/zh/tidb/stable/hybrid-deployment-topology#混合部署的关键参数介绍
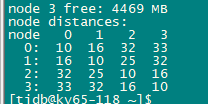
来自:@h5n1 的回复:
最简单的理解,一个socket就是一个numa node,每个node有就近分配的内存,叫local, 相对的另一个node分配的内存叫remote,CPU访问local比remote快,就是distance. CPU 内存资源充足情况下尽量访问local内存,所以用numa绑定进程只使用这些CPU和内存。 numa是硬件架构,操作系统或bios里关闭numa只是个假象,不能改变访问remote内存延迟高的问题
来自 @jiawei 的回复:
get到了。我也试试 看看压测结果如何 这次改一下表结构 再试试numa
来自:@Gin_ 的回复:
tiup 会使用 cpunodebind membind 绑定,想要精细控制需要修改 deploy_dir/scripts/ 目录下的启动脚本,比如不用 membind,改用 preferred
来自:@h5n1 的回复:
我记得好像直接改脚本后一reload又变回去了
来自:@Gin_ 的回复:
是的
numa一直没搞的太懂,最近有些cggroup的实践,想要控制cpu和内存,结果妥妥的把tidb夯住。
概念理解,但是还没有实际操作过,难过![]()