为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
Cluster type: tidb
Cluster name: tidb-report
Cluster version: v5.0.3
Deploy user: tidb
SSH type: builtin
【概述】 场景 + 问题概述
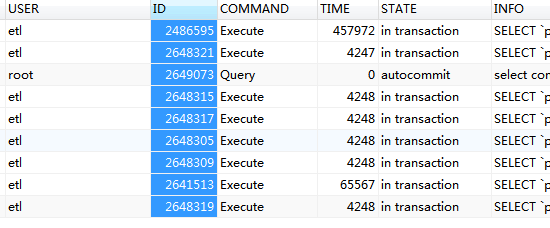
etl 抽数据发现疑似卡死SESSION,ETL任务停掉和执行kill tidb ID 命令均无法KILL掉session
执行 kill tidb id 命令的host,必须是sql所有在的host
比如在tidb-1上开始的事务,就要去tidb-1上kill,如果在tidb-2上,是kill不了tidb-1上的事务的
因此节点资源不足,tidb经常重启,不知道是不是有影响,又该如何解决
如果真的是资源不足那只能扩容, 如果是 expansive sql 导致的那需要优化, 不过都建议 memory_qouta
怎么解决眼前的问题呢,为啥这几个session kill不掉,只是个“残影”?还是实实在在的占用大量资源的SESSION?
啦啦啦啦啦
9
你用navicat连接tidb的IP是负载均衡的还是tidb server的实际IP
qizheng
(qizheng)
12
从日志看这些连接都 kill 掉了,show processlist 还能看到这些 connID 吗
show processlist;
select * from INFORMATION_SCHEMA.PROCESSLIST a where a.info<>’’;
都能看到
QBin
(Bin)
14
已知问题。5.0 的版本在 kill 了之后在原来的 session show processlist 会有残留显示,实际上是 kill 了。v5.4.0 以及 master 已经带上了这个 fix .
https://github.com/pingcap/tidb/pull/29212
有法子临时搞掉没,老是显示在那里,挺唬人的!升级又是个大工程。。。
QBin
(Bin)
16
断掉这个 kill 的 session 开一个新的 session 应该就能正确显示。
QBin
(Bin)
18
可以观察一下新开的 session 查询出来正在执行的 session id 和原来 kill 掉的是否一致。
1 个赞
我把这个TIDB结点重启了,没了。之前因为资源紧张,多次自动从DOWN 状态 变化成UP,好像并没有完全重启,还以为重启也没有用。用TIUP 直接把这个TIDB节点重启了一下,就彻底没有了。
