这不显示3个吗 ,tiup cluster display
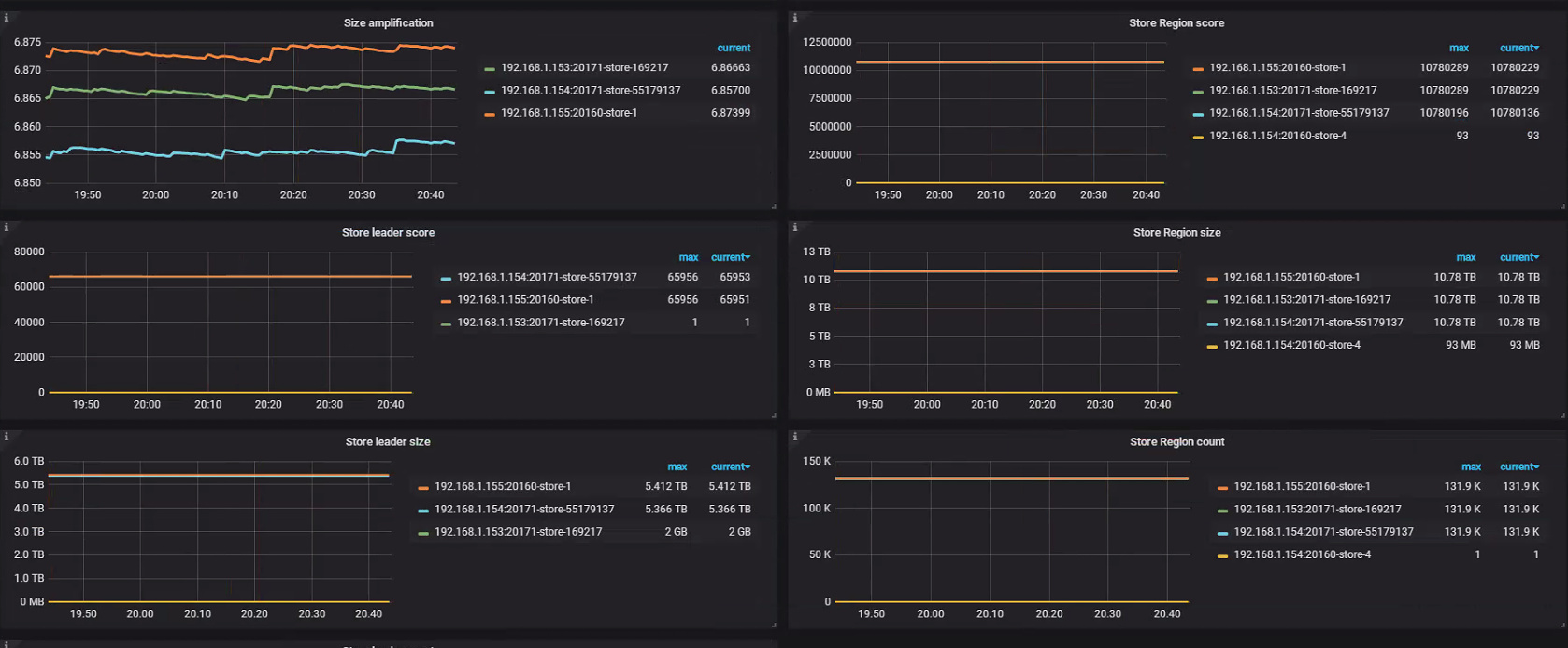
storeId=4的那个,现在那个region删不掉的是store4
就是显示offline的那个吗,是用pd-ctl delete store 缩容的吧?没有tiup吧?你看lowspace的是哪一个,然后试试
pd-ctl operator add transfer-peer <region_id> <from_store_id> <to_store_id> 把store 4上的71253 转移到55179137能否成功。
pd-ctl operator show和check看下状态

pd-ctl operator remove <region_id> 把这个操作取消掉,然后在用前面的remove-peer试试

下线过程是 转移store上的region peer到其他的store上,这过程会复制数据,这期间状态是offline的,等到peer都转移完后才会变成tombestone,才算完成下线,大多数是这种下线遇到问题后reomove peer 然后系统在自动的补副本,监控里虽然看不到store 4了 但是pd里还是有记录 。 下线时是怎么操作的
之前有其他同事操作过,不知道怎么搞的
这个是tiup管理的吗 有–force选项可以强制缩容tikv
是的,刚从ansible导入tiup中,发现tidb集群有点问题,感觉pd状态不对,现在store4已经不在了,就是pd里面没有更新
pd-ctl store delete <store_id> 试试能删除不,应该之前是用这个下线的,然后pd-ctl store remove-tombstone把那个转成墓碑的也清理下

store=4还能从pd中查出来,{
“store”: {
“id”: 4,
“address”: “192.168.1.154:20160”,
“state”: 1,
“version”: “4.0.0”,
“status_address”: “192.168.1.154:20180”,
“git_hash”: “198a2cea01734ce8f46d55a29708f123f9133944”,
“start_timestamp”: 1607689919,
“last_heartbeat”: 1607730906732970227,
“state_name”: “Offline”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 1,
“region_weight”: 1,
“region_score”: 93,
“region_size”: 93,
“start_ts”: “2020-12-11T20:31:59+08:00”,
“last_heartbeat_ts”: “2020-12-12T07:55:06.732970227+08:00”,
“uptime”: “11h23m7.732970227s”
}
pd-ctl operator add transfer-leader <region_id> <to_store_id> 试试把leader 转移到55179137 看看能触发点啥

在看下这个region状态 pd-ctl region check pending-peer ,转移到store 4上这个不存在的store,不知道会不会有问题,operator show 看下
等研发看看吧,弄不好最后的结果得用unsafe-recover 只把这个region和store 4处理掉,
tikv-ctl --db /path-to-tikv/db unsafe-recover remove-fail-stores -s -r
话说问题解决了没有?看上面的意思是 有一个 以前下线过的 store,上面的问题应该是 这个下线的 store 还有 peer(上面的无论是是 remove-peer 还是 其他 操作,应该都是 这个已下线的 store 还残留 peer 导致,remove-peer 这个store 上的 peer 试试)