为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
使用ticdc 同步生产数据到mysql,但是延时太大
【概述】 场景 + 问题概述
线上24个tikv节点,使用ticdc 同步生产数据到mysql,但是resolved ts lag 越来越大
【背景】 做过哪些操作
worker-num = 96
sink 端:
worker-count=48
【现象】 业务和数据库现象
延时加大,快超过24小时,需要重做
【TiDB 版本】
V4.0.13
【应用软件及版本】
mysql 5.7
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
日志:
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
麻烦提供一下完整的 ticdc 监控,定位一下延迟高原因.
xfworld
(魔幻之翼)
3
感觉是下游的处理性能跟不上
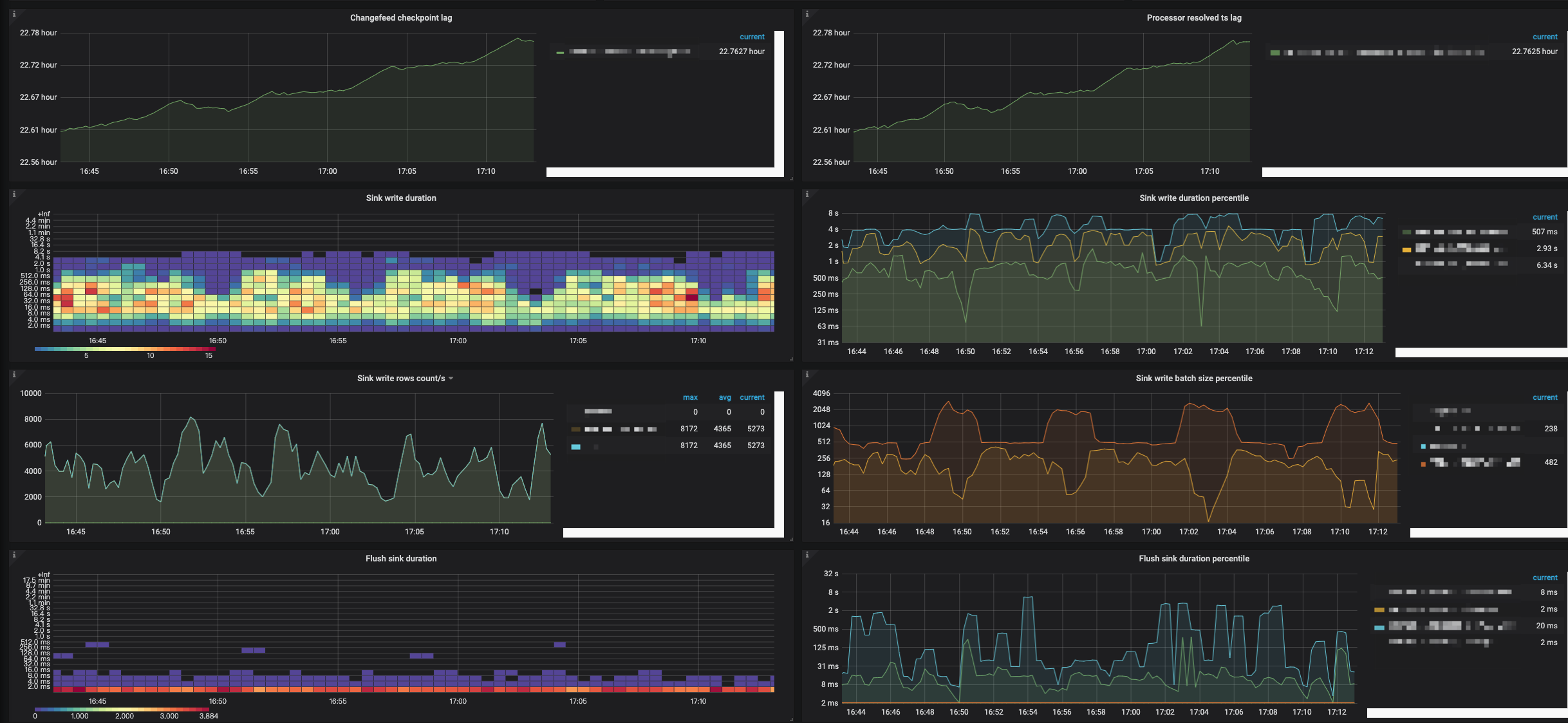
- Flush sink duration:TiCDC 异步刷写数据入下游的耗时直方图。
- Flush sink duration percentile:每秒钟中 95%、99% 和 99.9% 的情况下,TiCDC 异步刷写数据入下游所花费的时间。
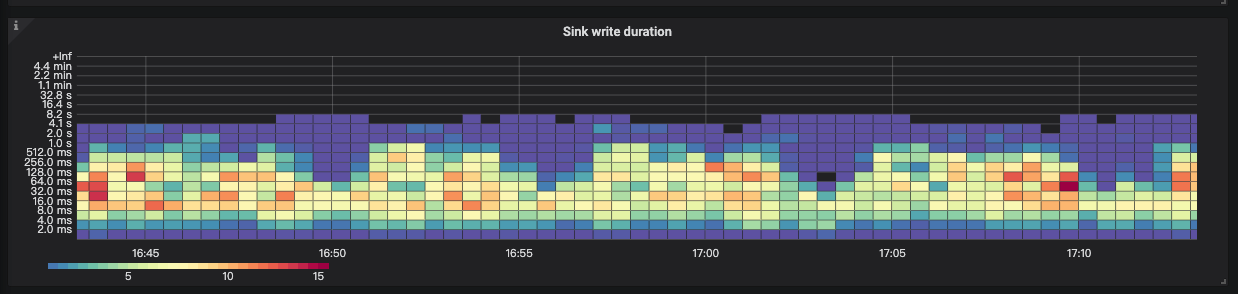
- Sink write duration:TiCDC 将一个事务的更改写到下游的耗时直方图。
- Sink write duration percentile:每秒钟中 95%、99% 和 99.9% 的情况下,TiCDC 将一个事务的更改写到下游所花费的时间。
按照参数的说明,基本上事务改写最大的处理有 8s 的
能说明一下场景和相关的数据规模么?
下游是mysql 5.7 隔离级别已经改为RC了,减少锁的时间了,就是批量的DML语句,enable-old-value = true 这个参数为true,insert和update变成replace
下游是有多个源端同时写入吗?如果只有TiDB往里写,RC与RR应该差不多吧
1 个赞
有差别因为enable-old-value, RR 有gap 锁,延时会更大,而且容易出现死锁
resolved ts lag 这个越来越大,不是抽取TIKV 时间太长导致的下游应用慢吗?
xfworld
(魔幻之翼)
9
建议你观测下,下游 Mysql 对于数据落盘的速度,以及相关的错误…
1 个赞
db_user
(Db User)
10
可以截取下cdc向下游传的sql,我遇到过因为上游delete多行出现的这种情况,如果下游没有其他操作,仅仅备份的话,可以考虑更改刷盘策略,暂时关闭二进制日志,关闭自动commit操作试试
打算这么做,事物大小有没有影响,现在是max-txn-row=5000
xfworld
(魔幻之翼)
12
max-txn-row=5000 向下游执行 SQL 的 batch 大小(可选,默认值为 256 )
设置5000是否太大了
xfworld
(魔幻之翼)
14
这些参数都是参考值,每个场景和环境都不一样,你自己判断下了
好的,谢谢,现在超过24小时了,明天我重做,再看看
db_user
(Db User)
16
事务大小貌似没啥影响,主要是cdc这头一个delete拆成了多行,一行一行提交,别的操作因为这个也堵塞住了
好的,明天我关注一下mysql 这边,之前一直以为是抽取数据那边的延时导致的,就是这个值resolved ts 很大
好的,谢谢,这两天在忙tiflash的事情,这个过两天再重做了,感谢关注
1 个赞
system
(system)
关闭
20
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。