
需要看一下具体的 SQL 和 schema 信息,详情看一下官方文档.https://docs.pingcap.com/zh/tidb/v4.0/explain-indexes#point_get-和-batch_point_get
TiDB 直接从主键或唯一键检索数据时会使用 Point_Get 或 Batch_Point_Get 算子。这两个算子比 IndexLookup 更有效率。
1 个赞
现在是tbl_shop_org orgid是主键,单独查询可以实现batch_point_get:
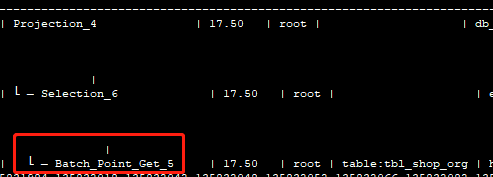
SELECT orgID FROM db_shop.aa WHERE groupID = 32sd and orgID in(…) 有500个值
这个SQL再一坨SQL里作为一个子查询处理,IN值多了 就没法BATCH_POINT,IN一个值或几十个还能够batch_point_get,这个不是有什么值控制个数?
可能分析器认为tablerangescan的效率和batchpointget的查询效率差不多。
表里一共多少条数据?
IN后面数据量大了,使用TableRangeScan效率更高,对表的扫描次数降低了
2 个赞
嗯……我看看……我把那一坨in的值单独查询走的是点差的……sql使用rang执行非常慢……
in值不是连续的……这个range不见的好
走哪个路径是优化器来决定的,优化器是会计算成本,对比起来点差的成本高那就不会走这个路径
2 个赞
mysql也一样,应该尽量避免in值过多的情况。
1 个赞
mysql in 多 有参数可以控制,能够解决它慢的问题,TIDB 不知道 有没有办法
in 值过多,tidb也是cbo吧
大多数据库都是CBO
2 个赞
340W
1 个赞
340W是指?
1 个赞
340W应该是指数据量吧
@啦啦啦啦啦 @Kongdom @Lucien-卢西恩 @Orange_sword @TiDBer_NtDbUm7p @TiDBer_L3dm6WTj
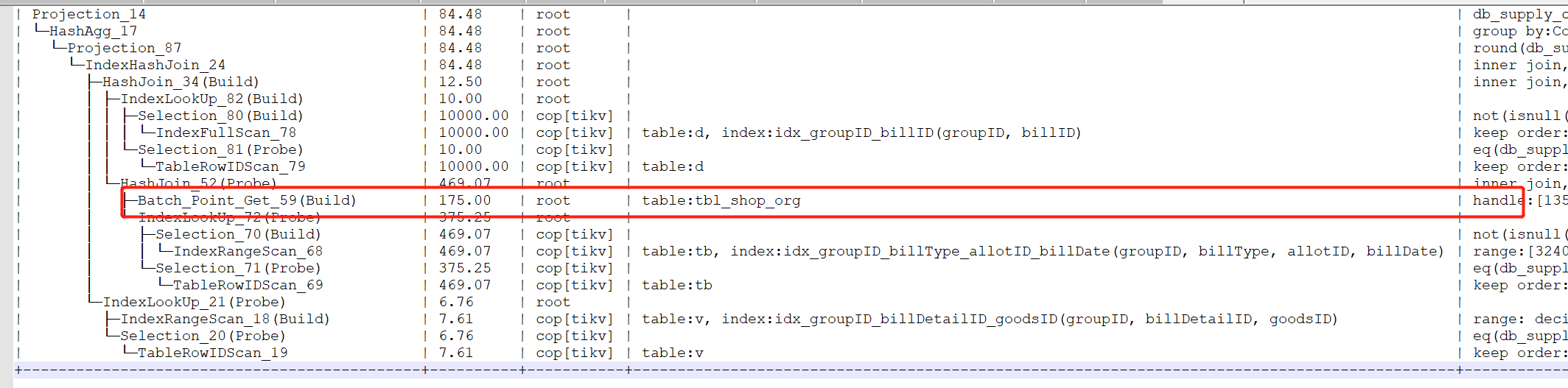
感谢各位,改写SQL逻辑 就用上batch_piont_get
1 个赞
方便告知下具体是如何改写 SQL 的吗?这样其他小伙伴遇到同类问题也可以借鉴下,谢谢。
业务逻辑使用子查询,把子查询改成left join方式 ,左表条件是主键就出现需要batch_point_get算子,执行结果就非常快了
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。