【 TiDB 使用环境】
【概述】场景+问题概述
从4.0.10升级到5.2.3之后偶发性出现数据库无法访问的情况,这种情况要怎么排查呢
【背景】做过哪些操作
从4.0.10升级到5.2.3
【TiDB 版本】
5.2.3
【 TiDB 使用环境】
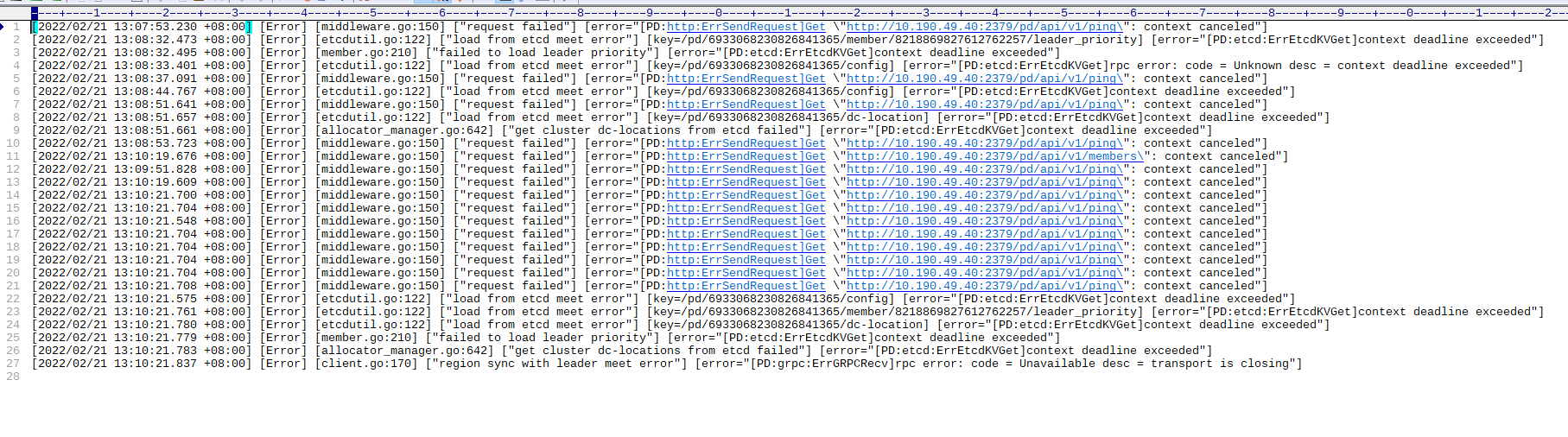
查阅下当前状态不正常的节点,收集一下日志信息,看看是什么情况
建议在服务器上执行tiup cluster display检查一下集群状态,顺便收集一下异常点的日志信息。
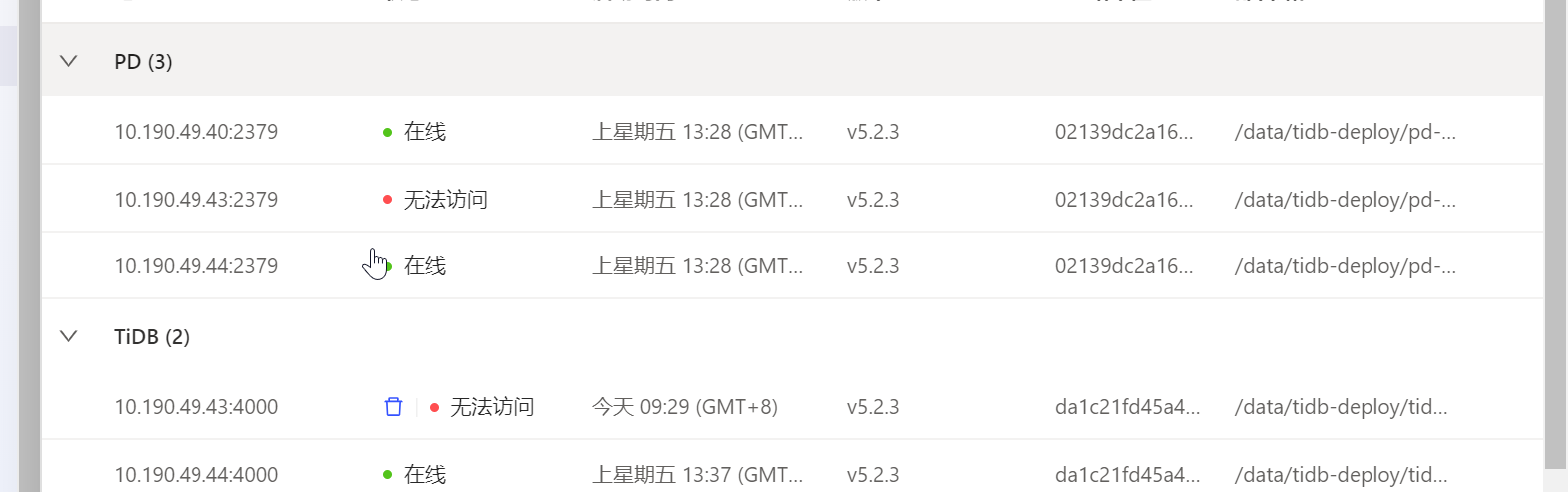
之前遇到过Dashboard中显示无法访问,但是tiup cluster display正常的情况
页面上显示无法方法,但是过段时间又正常了。我们运维的同事排查之后说是服务器上有僵尸进程较多占用了较大的资源,目前干掉了僵尸进程,释放了内存
pd_error.log (4.8 KB) tidb_error.log (601 字节)
10.190.49.40:2379 这个节点正常么? 43 这个节点是不是不能访问到 40?
[2022/02/21 13:07:11.264 +08:00] [Error] [client.go:346] ["tso request is canceled due to timeout"] [dc-location=global] [error="[PD:client:ErrClientGetTSOTimeout]get TSO timeout"]
[2022/02/21 13:07:13.971 +08:00] [Error] [client.go:599] ["[pd] getTS error"] [dc-location=global] [error="[PD:client:ErrClientGetTSO]rpc error: code = Canceled desc = context canceled: rpc error: code = Canceled desc = context canceled"]
[2022/02/21 13:07:47.079 +08:00] [Error] [client.go:346] ["tso request is canceled due to timeout"] [dc-location=global] [error="[PD:client:ErrClientGetTSOTimeout]get TSO timeout"]
直接就是 TSO 请求失败了…
还是 PD 无法连接的问题
目前已经正常了,之前出现这个问题的时候PD是无法访问的
估计没升级完成~ 这种情况,还是要多等待等待
偶尔不能访问应该是路由到状态未就绪的节点上了
对的,偶尔不能访问可能就是刚好访问到有问题的那个节点了,就像是应用中做了负载均衡一样,其中某个节点故障了,当访问这个节点时就会报错
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。