注意回复里的这句话,前提是region打散。如果region没有打散,增加tikv,写入还是写入之前的tikv,对写性能确实没什么提升。
我这边没有实操过,可以继续追问上面的回复。
题主可以描述一下数据特征、数据表结构,大家一起分析下
2 个赞
这种insert 快不了 ,本身写路径长,还有读路径
取消了part表原来的primary key 设置了shard_row_id_bits 和pre_split_regions 就是确保region被打散
我测试了一下如果把数据在不同的会话中拆分开,并行insert效率会线性增加 说明不是硬件性能的问题。而且增加batch_size也不会增加效率,这个问题是tidb本身机制的导致的吗?

batch 主要是为了防止大事务造成tidb server oom,因为写入的数据先写入到tidb 内存然后提交时才会写入tikv。 tidb本身就是为了处理高并发、扩展性,把一堆数据拆掉越小越多 ,只要没到资源瓶颈就能加快写入速度
1 个赞
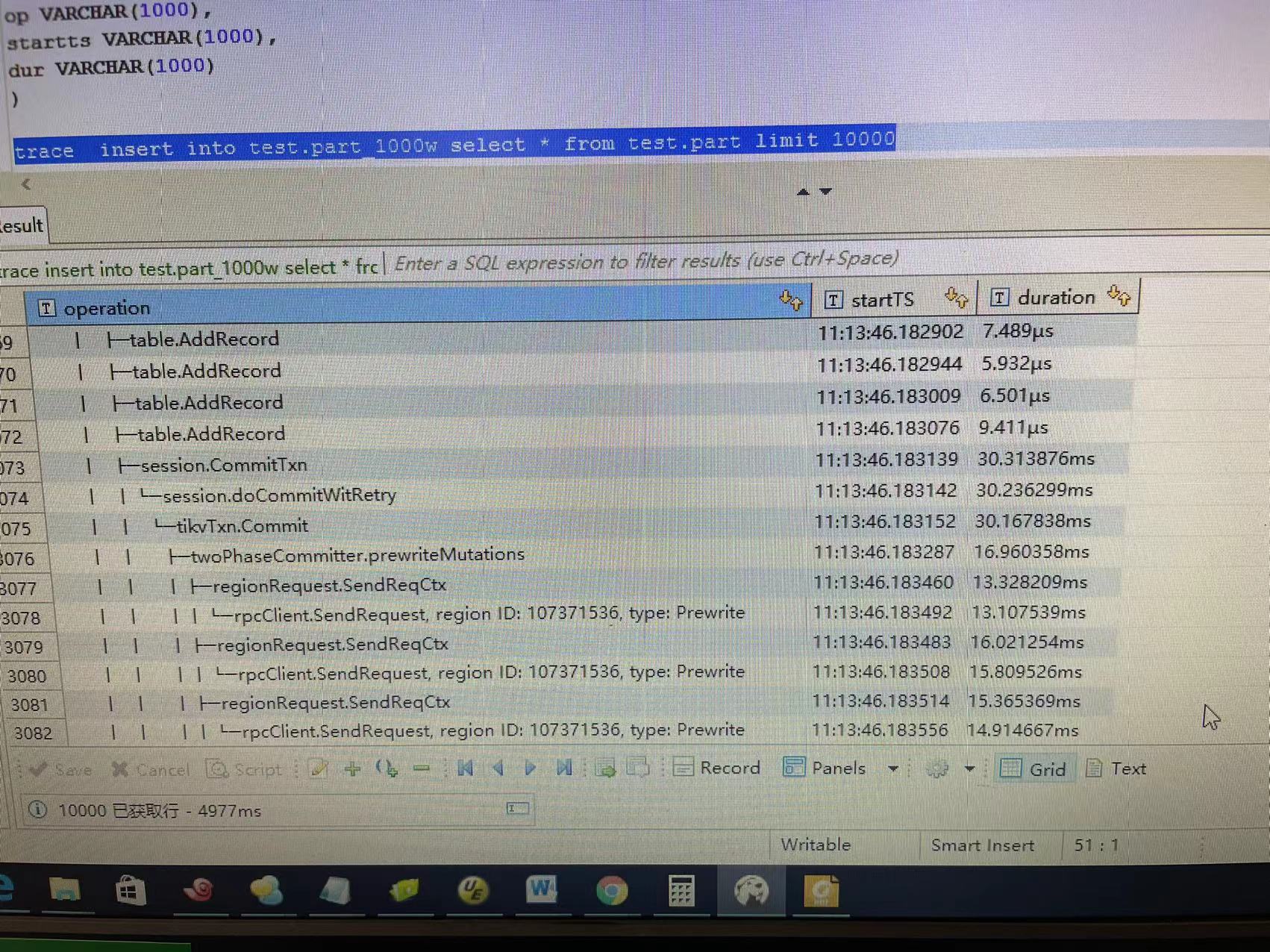
通过trace insert 语句发现在设置了batch_size后,insert 会先准备好一批数据 就是图中的table.addrecode 在达到batchsize后开始commit 但是我发现这一批数据的region都是一样的。因此无论什么时候都只有一个region在写 ,所以增加tikv的数量无法提高insert into。。。。 select的速度
后来我又建立了一个分区表测试了一下 在分区表的模式下同一批次内region 不同 但是效率不增反降 也许是增加了一个分区字段的原因吧?
写到同一个Region中效率肯定不高
2 个赞
补充一下 在不同的batch之间的region是不同的 可是问题是执行是顺序的那么每次还是只写一个region啊
shard_row_id_bits 由符号位+shard bits(5)+自增部分组成,shard_bits是随机的,但是一次Insert多个值时会使用相同的shard_bits+自增部分分配一段连续的记录。猜测使用batch的时候也是这样,可以少数据量测一下,比如5条、10条的1个batch,看看是不是连续的。
一个batch内果然是连续的所以insert into select 果然是单kv写入
无解了吗?
按条件分多个SQL insert
我如果自己散列rowid 那么如何才能预切分region 呢 pre_split_regions 只有和shard_row_id_bits 配合才起作用 持续困惑中
业务逻辑不允许啊!
设置bigint 主键,可以使用自己的值作为rowid, 或设置一个auto_random列+pre_split_regions
自己创建rowid的时候如何预切分region 呢?
手动 split table xx between() and () regions xx,
https://docs.pingcap.com/zh/tidb/v5.2/sql-statement-split-region#语法图
多谢!
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num