h5n1
2022 年2 月 20 日 11:00
1
【版本】v5.2.1
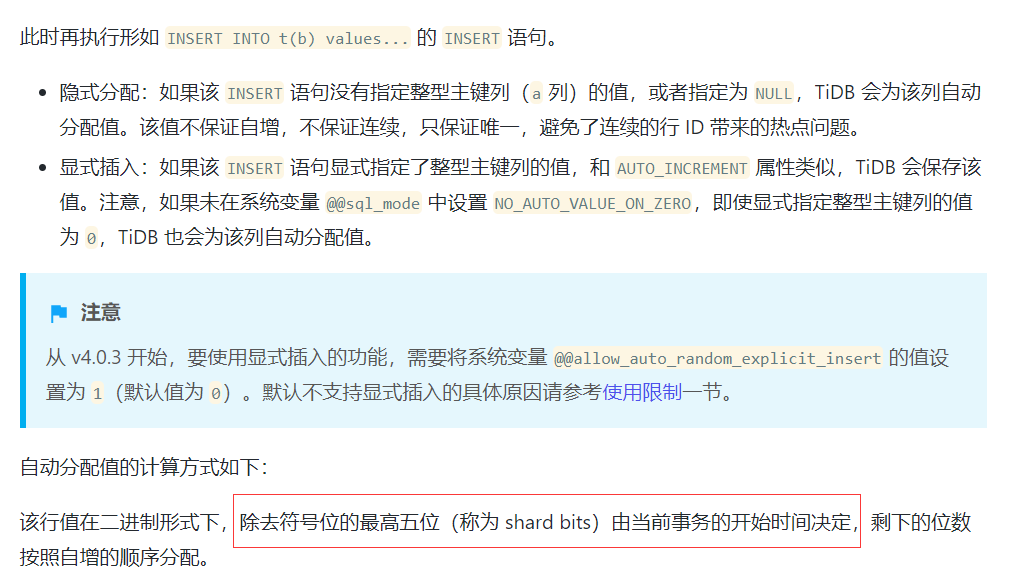
2、 在测试时auto_random分配的值出现个位数,原因是什么? 如果是凑巧除了低3位是1外其他位都是0的话自增部分的默认开始值好像也没从0开始?
3、 shard_row_id_bits的分配算法和auto_random是否相同?从描述和实际使用看两者的分配方式貌似一致,比如shard bits位数、insert多个values时分配的是连续递增的值。
// ShardIDLayout is used to calculate the bits length of different segments in auto id.
// Generally, an auto id is consist of 3 segments: sign bit, shard bits and incremental bits.
// Take
a BIGINT AUTO_INCREMENT PRIMARY KEY as an example, assume that the
shard_row_id_bits = 5,
// the layout is like
// | [sign_bit] (1 bit) | [shard_bits] (5 bits) | [incremental_bits] (64-1-5=58 bits) |
小王同学Plus
2022 年2 月 21 日 03:13
2
1.auto_random 自动分配值的选取:对于高 shard_bits 位,使用 startTS 的 hash 值决定。对于不属于 shard_bits 的低位,使用现有的自增逻辑进行分配和 rebase。
auto_random key 的一个原理大概如下:
Sign bit - 固定为 0 的符号位,即 AutoRandom 的分配总是非负数,长度为 1。
Shard bits - 生成随机数对 ID 值域打散,该段长度 AutoRandom 后面的括号中指定,默认为 5。
Increment bits - 自增位,用于保证 ID 的唯一性以及单语句 Insert 时,分配的连续性。
三段的示意图如下:
2.对于 auto_random 的列必须可写,否则逻辑同步会有问题。在可写的情况下,为了避免主键冲突,用户插入的时候需要 rebase,具体做法是去掉高位的 shard_bits 之后的结果作为下一个自动分配的 ID。但是从用户视角来看,如果算上高位的 shard_bits,rebase 的行为可能不符合用户的预期。
3.可以理解为是类似的。
问题比较偏向于底层原理设计,感兴趣的话建议看下代码,获得更加准确的信息~~~
3 个赞
xfworld
2022 年2 月 21 日 05:36
4
我参考过 在这之前的一篇实现,关于 snowflake 算法的高位换算https://asktug.com/t/topic/69478
在tidb 之前,一般都是Mysql ,为了满足 Mysql 顺序写入的要求,snowflake 的算法生成的 ID 是天然有序的,没办法满足高位打散的要求,否则会变成热点问题,所有的 ID 都会写入到连续相同的region 中
这个帖子刚好说明了这个问题,另外 row_id 的打散,也和这个类似
看对你的问题是否有帮助
1 个赞
请问下,这是怎么实现的,SHARDROWID_BITS 来控制所生成的隐藏列的值分散到足以跳过一个 region 大小(96MB)---->怎么确保成的row id 就可以跳过一个 region 大小(96MB)?
h5n1
2022 年10 月 31 日 19:04
6
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。