tidb -5.0.3
这种store怎么处理?
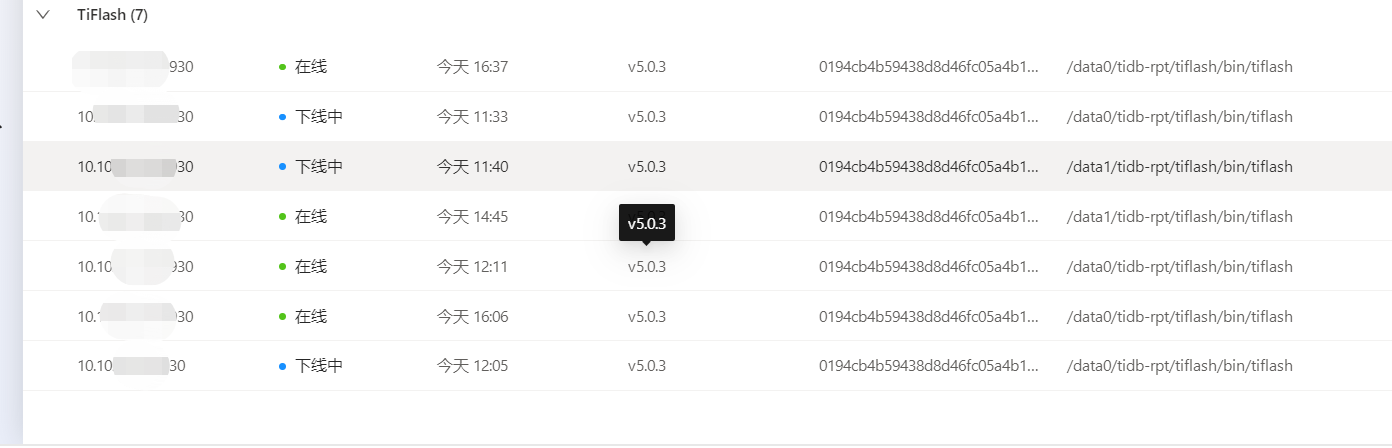
过程是这样: 集群特别满、卡。 我整个重启了一下 reload 集群。 跑到一半的时候 失败了,自动退出了。只重启了部分节点。 此时发现所有的tiflash节点(5个) 起不来了,反复重启状态。 没办法就新买一台机器,scale-out 扩容了一台节点。 然后我把线上启动失败的节点,其中的3台–force 剔除了。 然后就一直显示下线中。
中午的时候 没人使用, 我把流量关闭掉, 然后又reload重启了一下集群,这次重启集群是成功的。然后线上没下线的两台和我扩容的一台正常了。
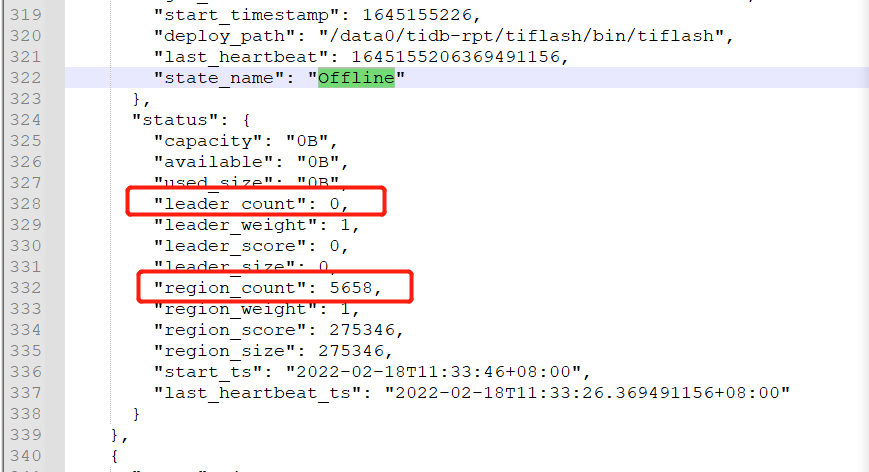
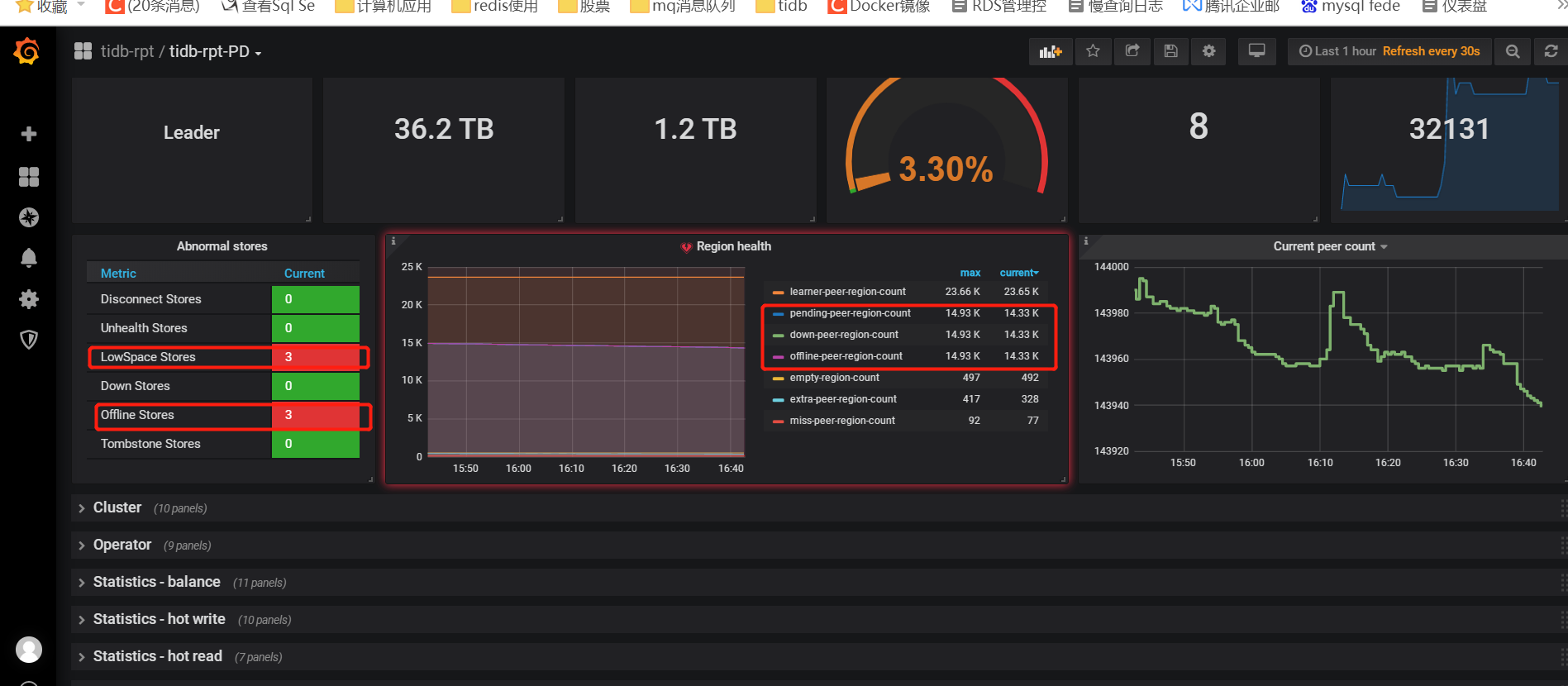
目前这3台节点上 没有数据,–force的。 是否可以在store 里 把offline的这3台删除掉。 好像pd-ctl 交互模式 不能直接删除offline状态的store。只能删除这 tombstone 这种。 offline 什么时候会变成tombstone? 是不是要等到监控中 offline-store-peer-count 变成0,或者down-store-peer-count 变成0?
tidb-rpt-TiKV-Summary_2022-02-18T08_52_25.303Z.json (5.2 MB)
tidb-rpt-TiFlash-Summary_2022-02-18T08_51_51.545Z.json (5.5 MB)
tidb-rpt-PD_2022-02-18T08_50_42.762Z.json (9.8 MB)