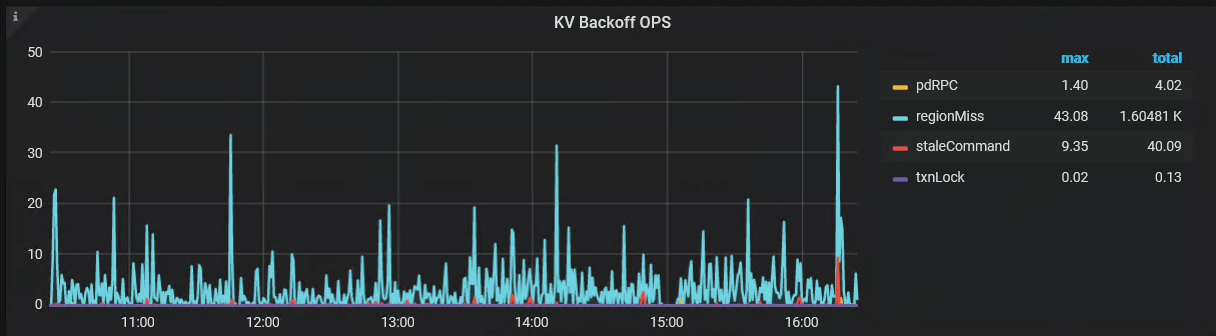
如图,kv backoff 中的regionMiss是什么意思?
有哪位大神有更详细的所有监控的详细介绍?
https://docs.pingcap.com/zh/tidb/v4.0/grafana-tidb-dashboard
1 个赞
region miss 表示访问的 region 在当前 kv 没有找到,可能从当前 store 迁走了。
这类访问 kv 失败的报错返回给 tidb 后,tidb 会发起 backoff 重试,如果重试超过最大重试时间,会将报错返回给客户端。
1 个赞
大佬有没有更详细的资料?包含这一个指标的介绍的资料
1 个赞
貌似官网也没有找到 regionMiss 这个指标的详细定义,只能先自己理解下了~
1 个赞
我给你转到文档优化建议里面去,帮你问问老师~
1 个赞
看看302课程
举个例子,某个 Region 发生了 MovePeer,例如因为调度从 TiKV-0 上移动到了 TiKV-1 上,而 TiDB 这边从本地的 Region 信息缓存使用旧的 Region 元信息发起了一次请求,认为该 Region 还在 TiKV-0 上,那么 TiKV-0 在处理这个请求时就会因为本地没有这个 Region 的信息而报错 Region is missing 从而触发 TiDB 更新 Region 信息后重试。regionMiss 这个指标反映的就是 TiDB 因为上述情况重试请求的次数。
4 个赞
谢谢老师的回复~
1 个赞
感谢大佬回复
1 个赞
region miss是tikv返回给tidb的错误还是tidb根据tikv返回的错误信息自己记录一次regio miss,.跟not leader的错误有什么关系
1 个赞
Region miss 是 TiKV 返回给 TiDB 的错误,TiDB 会根据这个记录一次 Region miss,也就是你在监控里看到的那个指标。Region miss 是因为 Region peer 被移走了 + Region 信息缓存没有及时更新导致的错误;not leader 也是类似,因为调度或某种原因 Region 的 leader 发生了转移但是 Region 信息缓存没有更新,导致 TiDB 请求到了曾经的 leader 现在的 follower,所以返回了这个错误,被 TiDB 记录了下来。
正常情况下这些错误都会在 TiDB 内部的重试机制下被正常处理掉,例如发生如上错误以后立马更新 Region 缓存信息,拿到最新的成员信息等。
4 个赞
感谢大佬! 这里的move peer是什么场景? region cache里应该包括每个region 的key范围、所有peer的store信息吧?默认是leader提供读写服务, 在没有使用follower read时,只访问leader 的tikv(大部分使用都是这样的),如果leader被转移了tikv应该返回not leader错误,为什么监控上会看到很多regiin miss?not leader也会在监控记录一次region miss吗?
1 个赞
会触发 MovePeer 的场景挺多,比较常见的:
- Balance Region 的过程中对 Region 进行 Store 间的搬迁,以达到存储上的均衡
- 根据 Isolation Label 或 Placement Rules 的配置对 Region 进行满足隔离/规则要求的 Store 间搬迁
- 热点调度的过程中对热点 Region 进行分散
Region Cache 里包括每个 Region 的 key 范围,所有 peer 的 store 信息,以及对应的 Raft 成员信息等。
是的,在没有使用 Follower Read/Stale Read 等 feature 的情况下默认只能由 Region leader 对外提供服务。
我检查了一下代码,对于 RegionMiss 或 not leader 这种 Region 访问相关的错误,在 TiDB 的这个 Backoff 监控里面统一都是使用 regionMiss 来作为标识,你可以理解为请求遇到类似 Region 状态不满足/信息对不上的错误的时候都会增加 regionMiss 这个指标,没有对每个错误都增加对应的标识。
2 个赞
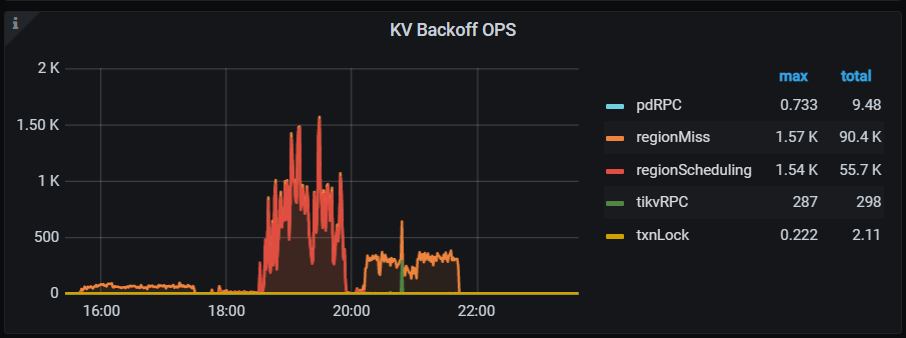
这个建议很好,希望能出个详细版的指标介绍。例如土豆大神对regionmiss的解释就挺好
regionScheduling 对应的主要是 Region 正在进行 split/merge 等操作,暂时无法提供服务而造成的重试
![]() 感谢大佬,学到很多内容
感谢大佬,学到很多内容
1 个赞
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。