版本: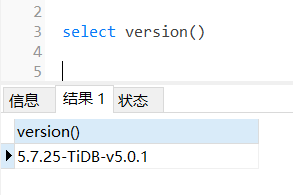
部署方式:docker-compose
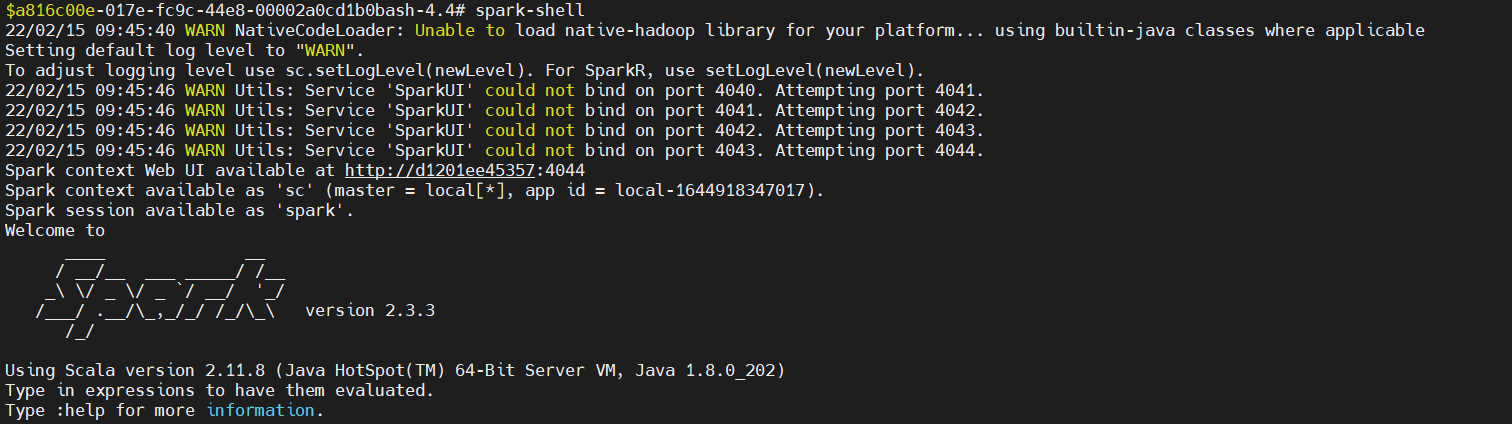
【概述】 tispark使用spark-sql,spark-shell等执行select 。。报错
【背景】mysql方式登录,查询正常
【问题】 tispark使用spark-sql,spark-shell等执行select 。。报错
【 TiDB 版本】
【附件】 spark-sql> select * from test;
22/02/15 09:02:19 INFO HiveMetaStore: 0: get_database: cn
22/02/15 09:02:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: cn
22/02/15 09:02:19 INFO HiveMetaStore: 0: get_database: cn
22/02/15 09:02:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: cn
22/02/15 09:02:20 WARN RegionStoreClient: Other error occurred, message: [components/tidb_query_expr/src/types/expr_builder.rs:295]: Invalid compare (sig = EqInt) signature: Evaluate error: [components/tidb_query_expr/src/types/function.rs:268]: Unsupported type: Unspecified
22/02/15 09:02:20 ERROR DAGIterator: Process region tasks failed, remain 0 tasks not executed due to
com.pingcap.tikv.exception.GrpcException: [components/tidb_query_expr/src/types/expr_builder.rs:295]: Invalid compare (sig = EqInt) signature: Evaluate error: [components/tidb_query_expr/src/types/function.rs:268]: Unsupported type: Unspecified
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:585)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:548)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:188)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
22/02/15 09:02:20 ERROR SparkSQLDriver: Failed in [select * from test]
com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:163)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:140)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.isEmpty(Iterator.scala:330)
at scala.collection.AbstractIterator.isEmpty(Iterator.scala:1336)
at com.pingcap.tispark.statistics.StatisticsManager$.loadMetaToTblStats(StatisticsManager.scala:205)
at com.pingcap.tispark.statistics.StatisticsManager$.loadStatsFromStorage(StatisticsManager.scala:153)
at com.pingcap.tispark.statistics.StatisticsManager$.loadStatisticsInfo(StatisticsManager.scala:141)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$1.apply(rules.scala:50)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$1.apply(rules.scala:42)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$resolveTiDBRelations$1.applyOrElse(rules.scala:73)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$resolveTiDBRelations$1.applyOrElse(rules.scala:63)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:288)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:286)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:286)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:306)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:304)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:286)
at org.apache.spark.sql.extensions.TiResolutionRule.apply(rules.scala:77)
at org.apache.spark.sql.extensions.TiResolutionRule.apply(rules.scala:28)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:124)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:118)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:103)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:364)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:272)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:158)
… 56 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:201)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.pingcap.tikv.exception.GrpcException: [components/tidb_query_expr/src/types/expr_builder.rs:295]: Invalid compare (sig = EqInt) signature: Evaluate error: [components/tidb_query_expr/src/types/function.rs:268]: Unsupported type: Unspecified
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:585)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:548)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:188)
… 7 more
com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:163)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:140)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42)
at scala.collection.Iterator$class.isEmpty(Iterator.scala:330)
at scala.collection.AbstractIterator.isEmpty(Iterator.scala:1336)
at com.pingcap.tispark.statistics.StatisticsManager$.loadMetaToTblStats(StatisticsManager.scala:205)
at com.pingcap.tispark.statistics.StatisticsManager$.loadStatsFromStorage(StatisticsManager.scala:153)
at com.pingcap.tispark.statistics.StatisticsManager$.loadStatisticsInfo(StatisticsManager.scala:141)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$1.apply(rules.scala:50)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$1.apply(rules.scala:42)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$resolveTiDBRelations$1.applyOrElse(rules.scala:73)
at org.apache.spark.sql.extensions.TiResolutionRule$$anonfun$resolveTiDBRelations$1.applyOrElse(rules.scala:63)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:288)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:286)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:286)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:306)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:304)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:286)
at org.apache.spark.sql.extensions.TiResolutionRule.apply(rules.scala:77)
at org.apache.spark.sql.extensions.TiResolutionRule.apply(rules.scala:28)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:124)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:118)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:103)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:364)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:272)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:158)
… 56 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:201)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.pingcap.tikv.exception.GrpcException: [components/tidb_query_expr/src/types/expr_builder.rs:295]: Invalid compare (sig = EqInt) signature: Evaluate error: [components/tidb_query_expr/src/types/function.rs:268]: Unsupported type: Unspecified
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:585)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:548)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:188)
… 7 more
官方和大佬们指点一下