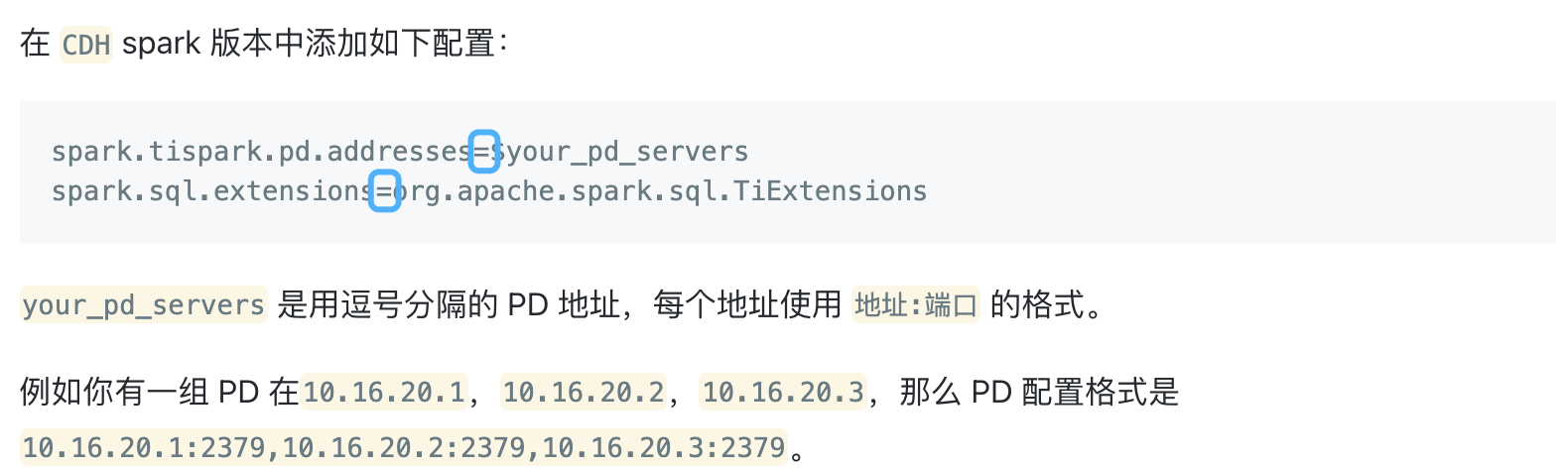
已有TiDB和CDH集群跑在生产上,现在希望CDH的spark直接读取TiDB的数据做分析,根据TiSpark用户指南说的在/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/spark-2.4.5/conf/spark-defaults.conf 文件配置了以下选项:
spark.tispark.pd.addresses 172.16.5.225:2379
spark.sql.extensions org.apache.spark.sql.TiExtensions
并使用tispark-assembly-2.4.3-scala_2.11.jar进行连接,进去后没发现有tidb的相关库名,如下:
[root@ds-cm-centric-cluster4 ~]# sudo -u spark spark-shell --jars /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/spark/jars/tispark-assembly-2.4.3-scala_2.11.jar
22/02/15 10:19:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ds-cm-centric-cluster4:4040
Spark context available as 'sc' (master = local[*], app id = local-1644891561738).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("use dba")
22/02/15 10:19:30 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
22/02/15 10:19:30 WARN ObjectStore: Failed to get database dba, returning NoSuchObjectException
org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'dba' not found;
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.org$apache$spark$sql$catalyst$catalog$SessionCatalog$$requireDbExists(SessionCatalog.scala:178)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.setCurrentDatabase(SessionCatalog.scala:265)
at org.apache.spark.sql.execution.command.SetDatabaseCommand.run(databases.scala:59)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:194)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
... 49 elided
scala> spark.sql("show databases").show
+------------+
|databaseName|
+------------+
| default|
+------------+
scala>