为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
4.0.9
【概述】 场景 + 问题概述
tidb 4.0.9 版本,先简单描述下问题,下面再详细列出现象。
对于一个非常大的聚合查询,如果使用内存很大,会导致tidb-server OOM,但是慢日志里记录的这条慢sql使用的内存却很小。这样会导致两个问题
第一个问题:不方便排查问题,因为实际使用内存很多的sql在慢日志显示使用内存很小
第二个问题:无法使用mem-quota-query限制sql,和第一个问题类似,既然慢日志无法获取到sql真实使用的内存,那这个参数可能也无法限制sql
详细现象和分析过程如下
-
内存监控如下所示
服务器256G内存,被一个SQL搞的OOM了
-
系统日志如下,在 14:12 分发生了 OOM,系统将 tidb 杀掉。
Jan 29 14:12:11 p-l27-5-232 kernel: Out of memory: Kill process 33885 (tidb-server) score 973 or sacrifice child
Jan 29 14:12:11 p-l27-5-232 kernel: Killed process 33885 (tidb-server) total-vm:265102100kB, anon-rss:256661104kB, file-rss:0kB, shmem-rss:0kB
Jan 29 14:12:11 p-l27-5-232 systemd[1]: tidb-4000.service: main process exited, code=killed, status=9/KILL -
慢日志
为了缩小范围,只截取OOM前1个小时的慢日志文件到 s1.log 文件
grep -n “2022-01-29T13:15:” tidb_slow_query.log | head -1
grep -n “2022-01-29T14:15:” tidb_slow_query.log | head -1
sed -n ‘70980,324937p’ tidb_slow_query.log > s1.log
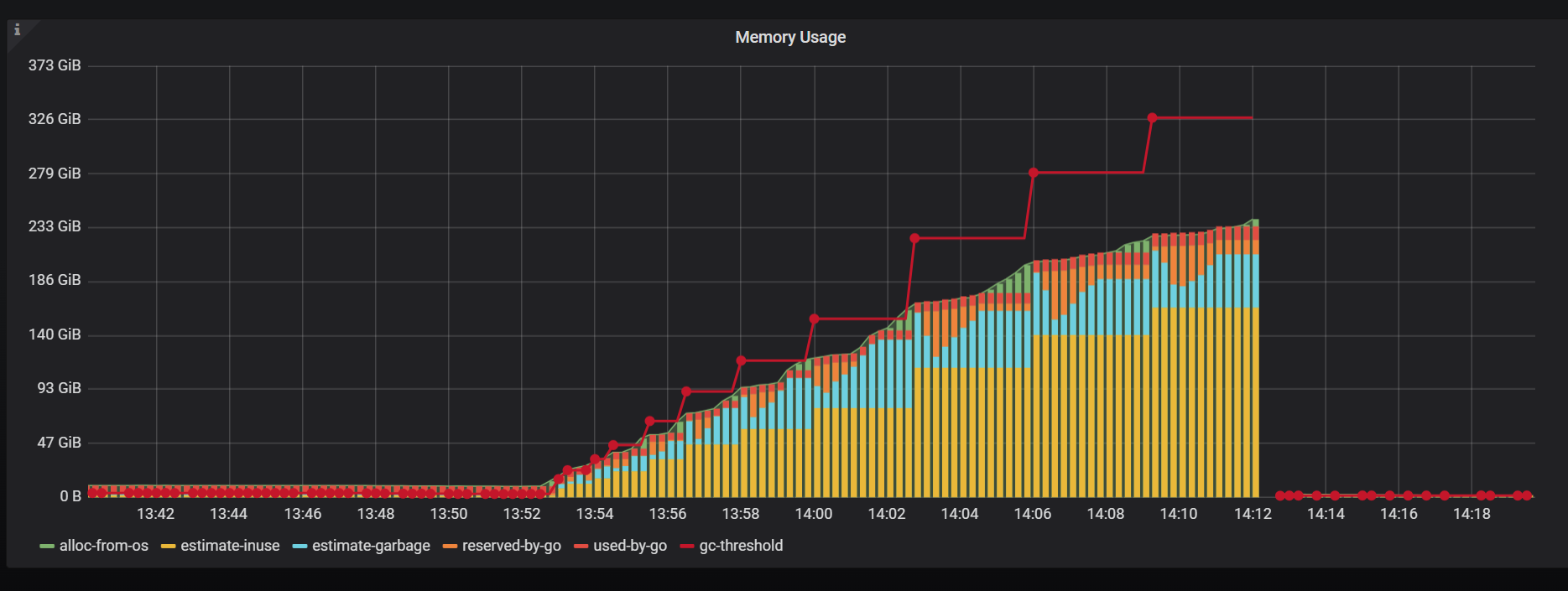
在s1.log 文件中查找超过10G内存的慢日志,很遗憾,没查到
grep “# Mem_max:” s1.log|awk ‘{if($3>10737418240) print $0}’
既然超过10G内存的sql没找到,那这个大sql肯定执行时间应该超过10秒了,在s1.log 文件中查找执行时间超过10秒的sql
grep “# Query_time” s1.log|awk ‘{if($3>100) print $0}’
找到一条,如下
慢日志
Time: 2022-01-29T13:20:53.690686772+08:00
Txn_start_ts: 430816158139547709
User@Host: user_r[user_r] @ 192.168.2.71 [192.168.2.71]
Conn_ID: 76282172
Query_time: 433.125794554
Parse_time: 0.000247011
Compile_time: 0.08934059
Rewrite_time: 0.000715712
Cop_time: 1710.378766644 Process_time: 22641.494 Wait_time: 15.51 Request_count: 15694 Total_keys: 1385482455 Process_keys: 1377115940
DB: db_club
Is_internal: false
Digest: e86be1e0634f317222e494b2484b1695c1d2531424d65c5808006cb80b1edc74
Stats: ClubReply:430813099836309510
Num_cop_tasks: 15694
Cop_proc_avg: 1.44268472 Cop_proc_p90: 2.643 Cop_proc_max: 10.597 Cop_proc_addr: 192.168.5.148:20173
Cop_wait_avg: 0.000988275 Cop_wait_p90: 0.001 Cop_wait_max: 0.443 Cop_wait_addr: 192.168.5.148:20171
Mem_max: 371902
Prepared: false
Plan_from_cache: false
Has_more_results: false
KV_total: 22701.058920333
PD_total: 0.000032638
Backoff_total: 0
Write_sql_response_total: 0.000008407
Succ: true
Plan: tidb_decode_plan(
Plan_digest: 890ea4c1d4ea76066eb70015d818b9ff85627e30976e7aa16a0f9918d3c8d5f2
/* ApplicationName=DBeaver 7.3.1 - SQLEditor <Script-22.sql> */ SELECT count(DISTINCT (rMemberId)) FROM db_club.tb_club where rBbsId = 66 and rReplyDate > ‘2000-1-1’ LIMIT 0, 200;
查找扫描超过1000万个keys的SQL
grep “Process_keys:” s1.log|awk -F’Process_keys:’ ‘{print $2}’|awk ‘{if($1>10000000) print $0}’
和上一步找到的相同
tidb.log 找到了这条sql
[2022/01/29 13:53:31.333 +08:00] [WARN] [expensivequery.go:178] [expensive_query] [cost_time=61.758348974s] [cop_time=40.293873673s] [process_time=833.76s] [wait_time=1.763s] [request_count=628] [total_keys=55611171] [process_keys=55580700] [num_cop_tasks=628] [process_avg_time=1.327643312s] [process_p90_time=2.269s] [process_max_time=5.455s] [process_max_addr=192.168.5.148:20173] [wait_avg_time=0.002807324s] [wait_p90_time=0.001s] [wait_max_time=0.317s] [wait_max_addr=192.168.5.146:20171] [stats=ClubReply:430813099836309510] [conn_id=76310253] [user=user_r] [database=db_club] [table_ids=“[4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687,4687]”] [txn_start_ts=430816768685768740] [mem_max=“114646015 Bytes (109.33495998382568 MB)”] [sql=“/* ApplicationName=DBeaver 7.3.1 - SQLEditor <Script-24.sql> */ SELECT rBbsId , count(DISTINCT (rMemberId))
FROM db_club.tb_club where rReplyDate > ‘2000-1-1’ group by rBbsId
LIMIT 0, 200”]
因为这个sql执行期间,使用内存超过了10G,有告警,因此在OOM之前,我看过这个sql,如下所示
db@192.168.5.232:4000 : (none) > select * from information_schema.processlist where id=76310253\G
*************************** 1. row ***************************
ID: 76310253
USER: user_r
HOST: 192.168.2.61
DB: db_club
COMMAND: Query
TIME: 1148
STATE: 2
INFO: /* ApplicationName=DBeaver 7.3.1 - SQLEditor <Script-24.sql> */ SELECT rBbsId , count(DISTINCT (rMemberId))
FROM db_club.tb_club where rReplyDate > ‘2000-1-1’ group by rBbsId LIMIT 0, 200
DIGEST: c8cecdf4f0d9e0506f541a18d55ff0aceee1df6fd7d7785a057922b8be8c975d
MEM: 30847222
TxnStart: 01-29 13:52:29.491(430816768685768740)
1 row in set (0.01 sec)
这有一个很诡异的问题
从show processlist看到这个sql执行时间是 13:52
tidb.log里看到这个sql的时间是13:53,和show processlist一致,因为执行时间超过60秒后才记录到tidb.log
但是慢日志里记录的时间是13:20
OOM的时间是14:12
看到这些信息,晕了
通过以上信息,可以推断出,导致OOM的sql就是上面show processlist显示的sql,即 begin ts 是 430816768685768740,而且在tidb.log里搜索关键字430816768685768740确实可以搜到,而且也能对上。
但是在慢日志里搜不到关键字 430816768685768740 。因此无法从时间吻合度上判断上面的慢日志是show processlist里看到的这个sql,但是从sql扫描的keys数量来看确实很像,扫描了13亿keys
为什么导致OOM的这个慢sql没记录到慢日志?
为什么耗费内存这么大的sql在慢日志里记录的适用内存和监控上使用内存不一致?
如果有兴趣,可以模拟一个使用内存很大的sql,执行一下,看看监控上上内存使用情况,然后看看慢日志里记录的内存值大小,是否对得上。
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。