为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
4.0.9
【概述】 场景 + 问题概述
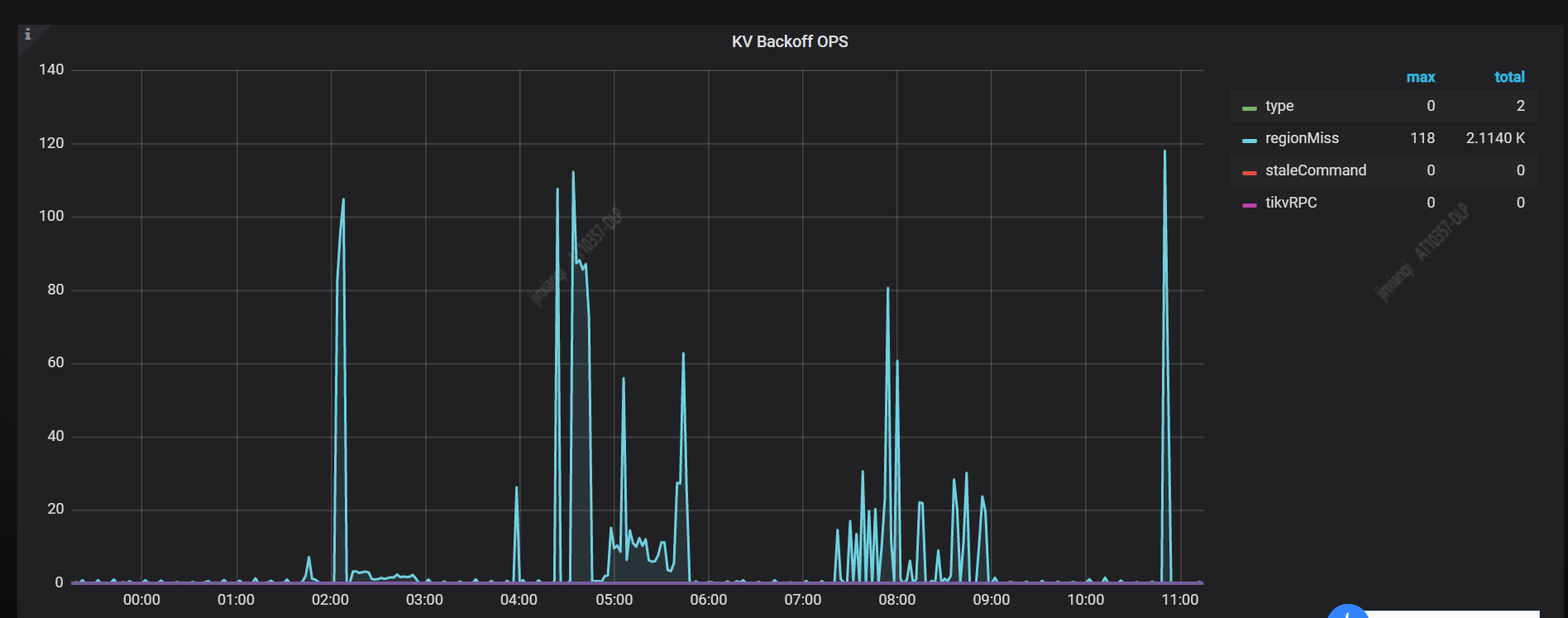
监控中显示每整点时有大量 regionmiss ,分析慢日志发现有如下 SQL
load data local infile xxx
这个 SQL 执行时间 228 秒(也有个别 load 语句执行了几千秒),这个 SQL 在慢日志中显示了大量 regionMiss 关键字,统计后,共计 21817 个 regionMiss 关键字,仅仅这一个load语句,就这么多个 regionMiss 关键字。
集群状态算是正常,没有节点下线和OOM之类的,通过监控看到,各个节点leader的数量在同个时间段没有抖动现象,很平稳。duration有一点尖刺,说明load操作对集群应该有点影响。
同时发现相应时间段内,网卡流量,tcp retrans,IO util出现一个尖刺,峰值。
我的问题是:
(1)像这种大量 regionMiss 会导致集群什么问题?需要关注吗?
(2)像这种 load 操作需要拆分成小文件导入吗?需要优化吗?
(3)大的事务在tidb上最大的问题是什么?类上面load操作
请帮忙解答一下,谢谢
【背景】 做过哪些操作
慢 SQL 如下所示,省略了部分 regionMiss 关键字,因为太多了。
Time: 2022-01-29T13:57:32.276797564+08:00
Txn_start_ts: 0
User@Host: ad_w[ad_w] @ 10.30.1.106 [10.30.1.106]
Conn_ID: 124758945
Query_time: 228.417722959
Parse_time: 0.000151069
Compile_time: 0.00012463
Rewrite_time: 0.000095709
Prewrite_time: 57.333421602 Commit_time: 2.097102984 Get_commit_ts_time: 0.021664947 Commit_backoff_time: 47.004 Backoff_types: [regionMiss regionMiss regionMiss regionMiss regionMiss regionMiss regionMiss regionMiss
… 这里省略了大量 regionMiss 关键字,共计 21817 个。
] Write_keys: 4293582 Write_size: 2214438986 Prewrite_region: 22413
DB: ad
Is_internal: false
Digest: dfd48deeb71f43343f731bc2572fbd31c539267e8ad7dde7d9f04bfb4cacbdb1
Num_cop_tasks: 0
Prepared: false
Plan_from_cache: false
Has_more_results: false
KV_total: 907.205072586
PD_total: 0.032086503
Backoff_total: 47.01
Write_sql_response_total: 0
Succ: true
Plan: tidb_decode_plan(
use ad;
load data local infile ‘/data/data1/tmp/part-00000’ into table ad.dim_ad_wise character set utf8 fields terminated by ‘\t’ lines terminated by ’ ’ (xx,xx,xx,xx);
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
4.0.9
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。