为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 场景 + 问题概述
【应用框架及开发适配业务逻辑】
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
【附件】 相关日志及监控(https://metricstool.pingcap.com/ )
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
2 个赞
tidb_log.zip (77.8 MB)
可以先根据这个文档设置一下相关参数TiDB 内存控制文档 | PingCAP Docs
然后看看tidb_analyze_version设置的是多少,可以改成1试试
2 个赞
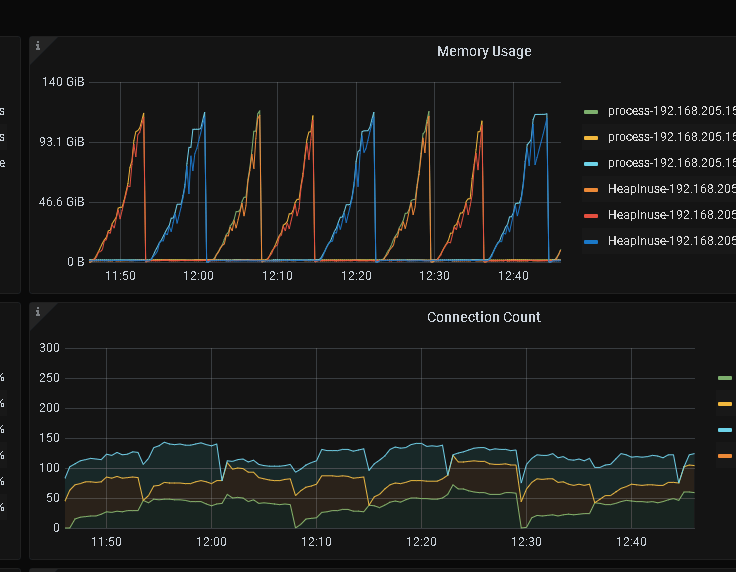
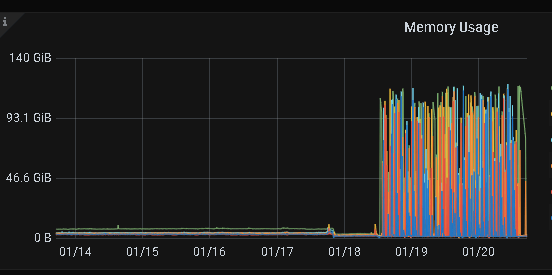
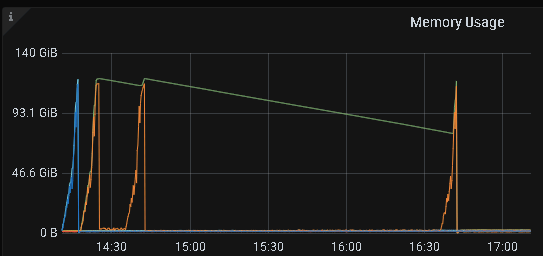
升级之后,故障持续了近2天,刚刚在没有做任何调整的情况下,貌似恢复正常了,截图如下:
看了下变量tidb_analyze_version的值,目前为2, 如果下次再出现这个问题,我们会根据您的建议调整为1.
内存控制的相关设置,我们会尽快实施调整,非常感谢您的回复。
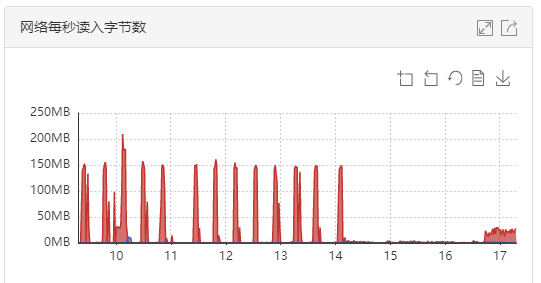
再补充一个信息,发现在tidb-server内存爆增的时间点,网络流量也同步放大,基本可以肯定是从网络(比如tikv)读入大量数据进入内存,但是我们没有看到有提取大量数据的sql存在。
记得回复你想追问的 TiDBer 哟~要不然他收不到你的回复哟~
1 个赞
caiyfc
2022 年1 月 20 日 09:29
12
可以从日志看看,可能是因为升级之后重新收集了统计信息,但是我不知道这个是否会造成OOM
caiyfc
2022 年1 月 20 日 09:36
13
用语句 SHOW ANALYZE status 来查看每个表的收集统计信息的开始时间,看看能不能对上。
您好,查了一下 SHOW ANALYZE status , 没有查到任何记录
caiyfc
2022 年1 月 20 日 09:56
16
用这个语句看看 show stats_histograms
日志里显示 CFG.WPD_MENUCONFIG张表分析的时候,因为事务太大失败
手动执行了一下 ANALYZE TABLE CFG.WPD_MENUCONFIG 能够复现上面的问题,tidb-server内存立马狂飙。
PS: CFG.WPD_MENUCONFIG这张表里面有个longtext,里面存了不少大文本。
caiyfc
2022 年1 月 20 日 10:34
18
可以把tidb_analyze_version设置成1试试
tidb_analyze_version 这个参数设置为1之后,我重新调用 ANALYZE TABLE CFG.WPD_MENUCONFIG 已经能够成功执行,且内存占用只有稍微的提升,看来是起作用了。
看来是V5.3.0引入的tidb_analyze_version=2的特征有一些问题
后续观察一下,有问题再反馈,非常感激!
1 个赞