heming
2022 年1 月 17 日 04:11
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
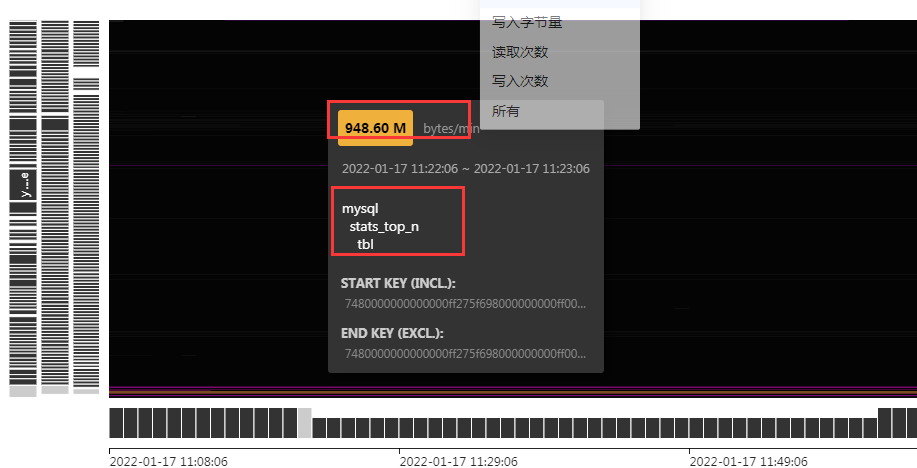
【概述】 场景 + 问题概述mysql.stats_top_n
SELECT COUNT(1) FROM mysql.stats_top_n
这个表也太疯狂了吧
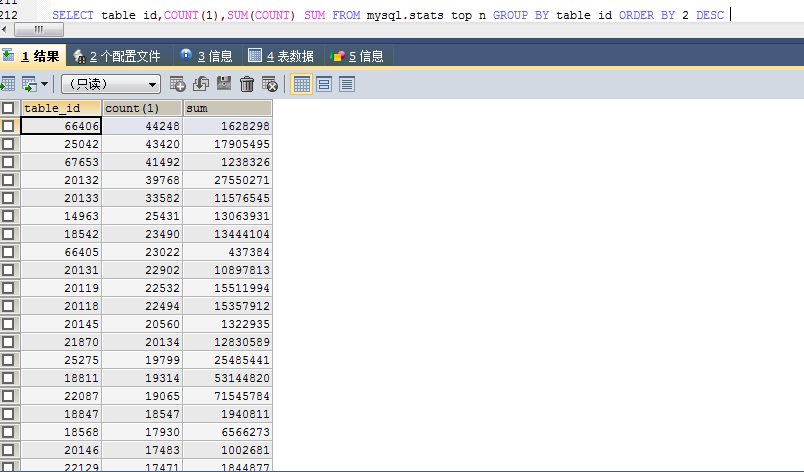
7615288 这么多条记录 # 5.0当时也是有大量的垃圾统计信息
这个表还有BLOB大字段 每个table_id 有大量的记录条数 是不是GC清理不及时 ?
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题,参考 AskTUG 的 Troubleshooting 读性能慢-慢语句
【统计信息是否最新】
【执行计划内容】
【 SQL 文本、schema 以及 数据分布】
【业务影响】
【TiDB 版本】https://metricstool.pingcap.com/ )
TiUP Cluster Display 信息
TiUP CLuster Edit config 信息
TiDB-Overview Grafana监控
TiDB Grafana 监控
TiKV Grafana 监控
PD Grafana 监控
对应模块日志(包含问题前后 1 小时日志)
1 个赞
北京大爷
2022 年1 月 18 日 02:51
2
此表为 相关 Table 的统计信息对外查询的一个内部系统表。
有关 top n 的统计信息知识详见。https://docs.pingcap.com/zh/tidb/stable/statistics/#top-n-信息
如果对热点在意可以通过 调整 load base split 来缓解这一问题
3 个赞
heming
2022 年1 月 18 日 03:16
3
一个表3-4万条统计信息 也太多了吧 是不是应该有一个清理机制
1 个赞
北京大爷
2022 年1 月 18 日 03:47
4
多不多 可以自己计算下
(行数+索引数量)* top_n* 分区数量
1 个赞
有清理机制的,不用的 TopN 会被清理掉;
1 个赞
heming
2022 年1 月 20 日 02:05
6
qw4990-PingCAP:
tidb_analyze_version
show variables like ‘tidb_analyze_version’;@top_N ;
heming
2022 年1 月 20 日 02:14
7
大量 的table_id 都是不存在 的
(user:tidbdba time: 10:10)[db: information_schema]select * from TABLES where TIDB_TABLE_ID=67653;
1 个赞
heming
2022 年1 月 20 日 02:19
8
gdt_account_daily_report_request_part 这个表也不是分区表 记录也只有4000多条 account_id,date) /*T![clustered_index] NONCLUSTERED */
1 个赞
如果 analyze_version = 2 的话,默认的 TopN 搜集个数就是 500 个;
目前在 v5.2 上的解决办法会比较 “手工” 一点;
在 v5.4 后解决这个问题会更方便,执行一次 analyze table with 50 topn 后,TiDB 则会把 analyze 配置记录下来,后续一直用这个配置:https://github.com/pingcap/docs-cn/blob/master/statistics.md#analyze-配置持久化
2 个赞
heming
2022 年1 月 21 日 06:11
10
好的 ,那就只能等5.4 ? 没有系统参数设置 topN 是吧
1 个赞
是的,目前是没有办法;
1 个赞
system
2022 年10 月 31 日 19:05
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。