为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
我们是用Flink解析Kafka的数据,然后实时写入TiDB实时数仓。Flink不开窗口,每条来一条数据,立马通过jdbc写入TiDB。不能攒一批写入TiDB,因为这样会影响时效性。
但是通过jdbc写入TiDB,速度比较慢。而且我们不能采用批处理的方式来写入TiDB。请问有什么办法可以高速写入TiDB吗?
目前我是通过扩展Flink并行度来提高写入速度的,但是这样很消耗Flink的内核数等资源
hi,如果不按批写入的话速度确实是比较慢的。在之前的实践中,开启了 JDBC 的按批写入之后,即使设置窗口大小为 1s,速度也至少可以提升十倍以上。
请问现在每秒大约处理多少条,希望的条数是多少呢?
谢谢回答,这个问题解决了。我后来改成批处理了,1秒一批
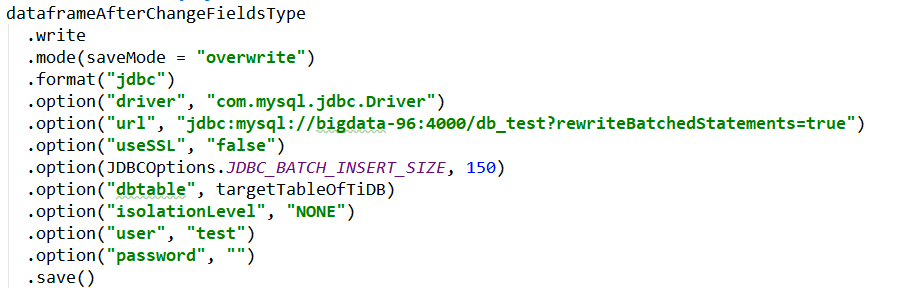
而且,需要在jdbc的url连接里面,加上rewriteBatchedStatements=true,否则jdbc不是真的按照批的方式写入数据的,速度会比较慢。
1 个赞
来了老弟
4
请问在Spark中通过JDBC将数据写入TiDB时,这两种方式,哪种速度比较快?
1、spark.write.format(jdbc)
2、常规的jdbc的批处理写入TiDB,先addBatch把数据保存在客户端,然后统一executeBatch,然后commit。
来了老弟
6
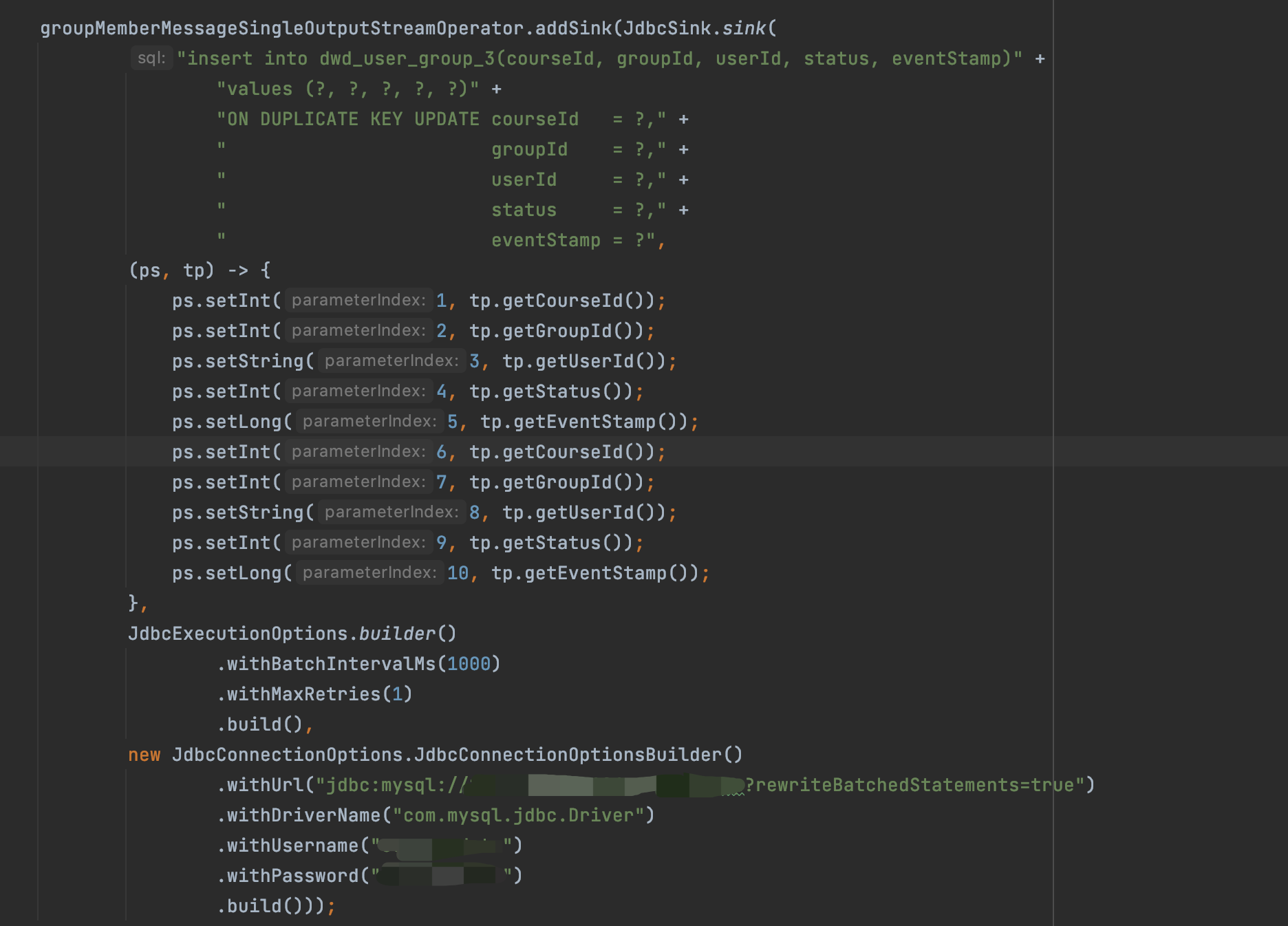
使用flink jdbc批量写入但是写入的速率和单条数据的写入速率差不多没有量级的提升,请问一下这个是什么原因。是我缺失什么设置了吗。
flink10个并发,写入tidb的速率:
JDBC批量写入:5000/min
单条写入:4300/min
Hi,麻烦您尝试找一个 mysql-server 写入看看效率呢?确定一下问题具体模块。
为什么需要找一个mysql写入测试呢,这个主要是为了对比什么?
尝试使用flink jdbc批量写入mysql-server
数据条数:14342124
总共耗时:1797s
速率:7981.14/s
之前写入tidb时没有使用ssd修改为ssd后
flink jdbc批量写入
数据条数:5583515
总共耗时:2025s
速率:2757.29/s
单条数据写入:
数据条数:5427123
总共耗时:2132s
速率:2545.55/s
目前的结果是写入tidb的速率只有写入mysql的速率地三分之一多一点
看起来 mysql/tidb 攒批增加的效率比都不是很多,调节一下攒批大小试试呢?
.withBatchSize(10000)
可参考:https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/datastream/jdbc/#full-example
另外,可以按 如何提升Flink写入tidb的速率 中描述的方法使用 tidb 专用的 tibigdata 连接器试一下。
今后我们直接在那个帖子下面回复吧
嗯嗯 好的。我在这个新的帖子中更新了一些新的线索,期待您新的回复