各位大佬好,有没有人遇见或者能知道是为什么的?业务刚上线,线上集群基本没有多少用户在使用,但是计算节点的带宽总是占满了,我有三个存储节点,这三个存储节点一直在向计算节点发送数据,每个节点2~3Gbps每秒,正好占满万兆网……
按理说也没几个人用,为什么网络资源占用这么多?业务上也没有查询什么,除了测试人员点点点,用户基本就只剩下领导检查系统好用不好用,在这样的情况下为什么存储节点一直在向计算节点发数据,更神奇的是计算节点收到这些数据没有任何动作,没有发送给客户端什么,向存储节点返回的数据也从未超过几十Mbps这个量级。
你好,麻烦反馈一下如下信息:
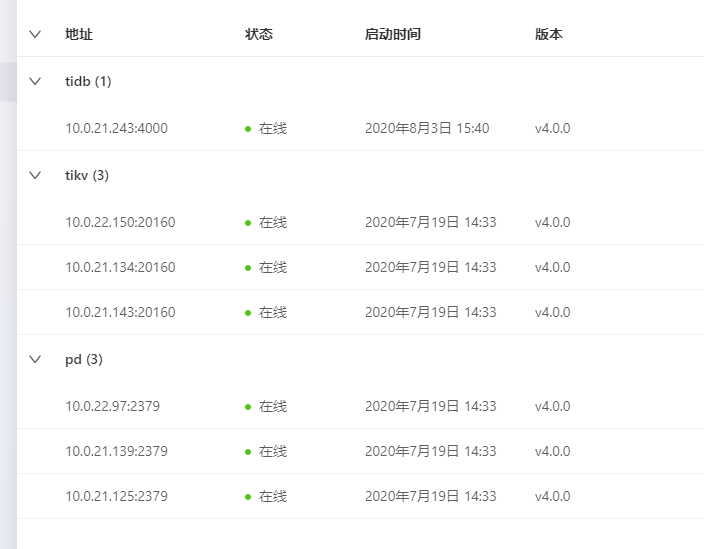
1.集群的版本信息和当前的拓扑结构;
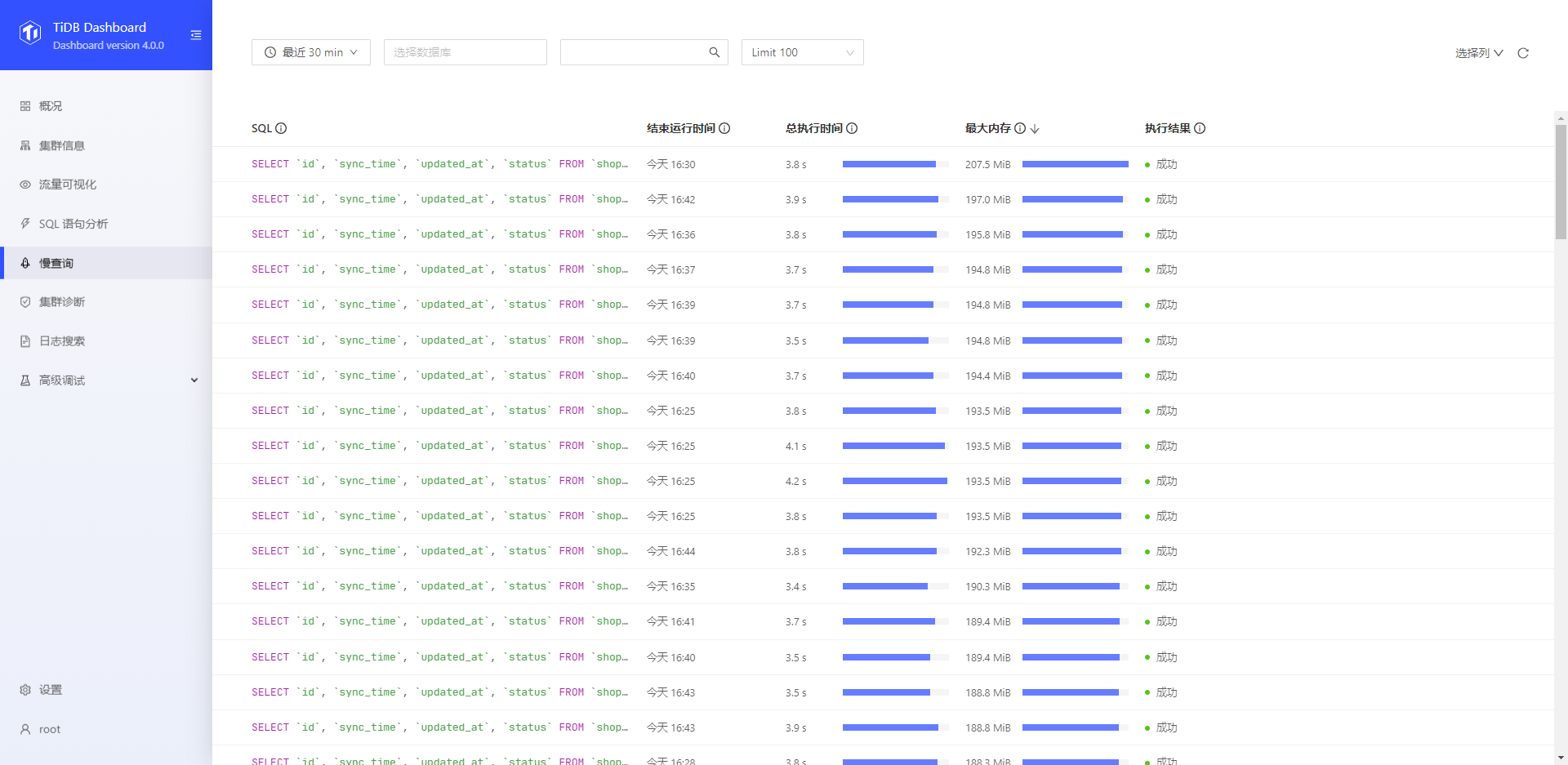
2. dashborad 中慢 SQL 情况,可以按照内存使用情况排序;
2.tidb 节点带宽满的时间段内集群 Grafana 中 overview 面板的监控,可以参考下面方式导出面板:
3.tidb 节点带宽满的时间段内 tidb 和 tikv 节点的日志
你好,集群信息如下图所示:
dashborad 中慢 SQL 情况:
tidb 节点带宽满的时间段内集群 Grafana 中 overview 面板的监控:
tidb-tudui-Overview_2020-10-09T08_52_32.082Z.json (973.8 KB)
带宽满的时间段是今天一整天,所以我就把今天白天tidb 和 tikv 节点的日志全部下载了,但是文件太大,所以用百度网盘的形式:
链接:百度网盘-链接不存在
提取码:2222
看看pd的监控,是否有相关的调度任务在执行
你好,您不是说看看慢查询嘛,我看到很多语句占用内存都很高,虽然动作少,但是每个动作需要的数据都很多,可能就是因为执行这些语句导致存储节点向计算节点发送了大量数据的原因。这是不是意味着:一定要尽量禁止像取第1000万之后的100条数据这种偏移过大的语句,哪怕是TiDB这种分布式数据库也不例外。
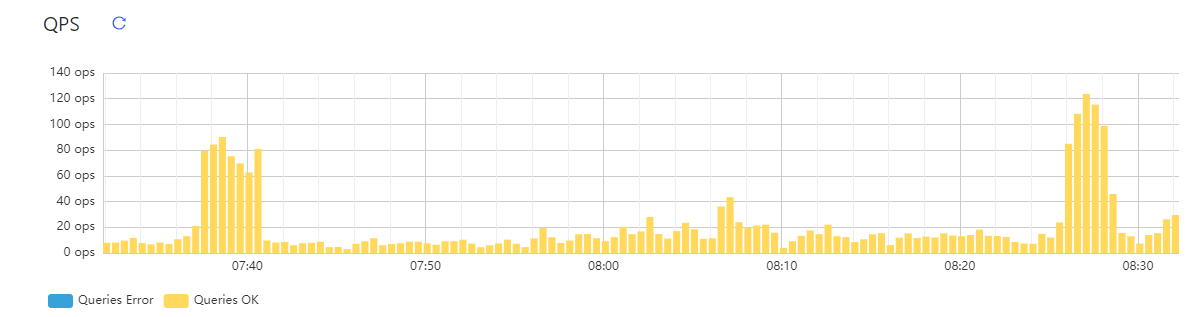
如上图所示,数据库的动作确实是很少,拢共也没执行几条语句。
好的,谢谢
对了,我的计算节点只有一个,假如说有两个计算节点,会不会分担压力,会好一些,如果会好的话,我就有理由要求领导加计算节点了。
(1)如果慢SQL 都是取 1000 万之后的 100 条数据这种类似分页的查询语句,对于集群的性能开销确实比较大;
(2)从监控上看你这个集群当前数据量仅 100G,但三个 tikv 的 CPU 使用率已经有 56%,每个 tikv 节点出口流量有 280 Mib,统一汇总到一个 tidb 节点时入口流量已经有 856 Mib,但由于 tidb 集群会将计算下推至 tikv 节点 ,单纯增加 tidb 节点只能缓解问题,随着数据量增加,tikv 节点也会达到瓶颈;
(3)建议从业务角度优化下 SQL 逻辑,对于这类分页查询的优化,可以参考下面这篇文章:
https://book.tidb.io/session4/chapter6/page-inaction.html
好的,明白了,谢谢。
不客气,有问题可随时开贴提问。