为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:tidb 4.0.6
- 【问题描述】:tidb和pd部署在一起 3个tikv
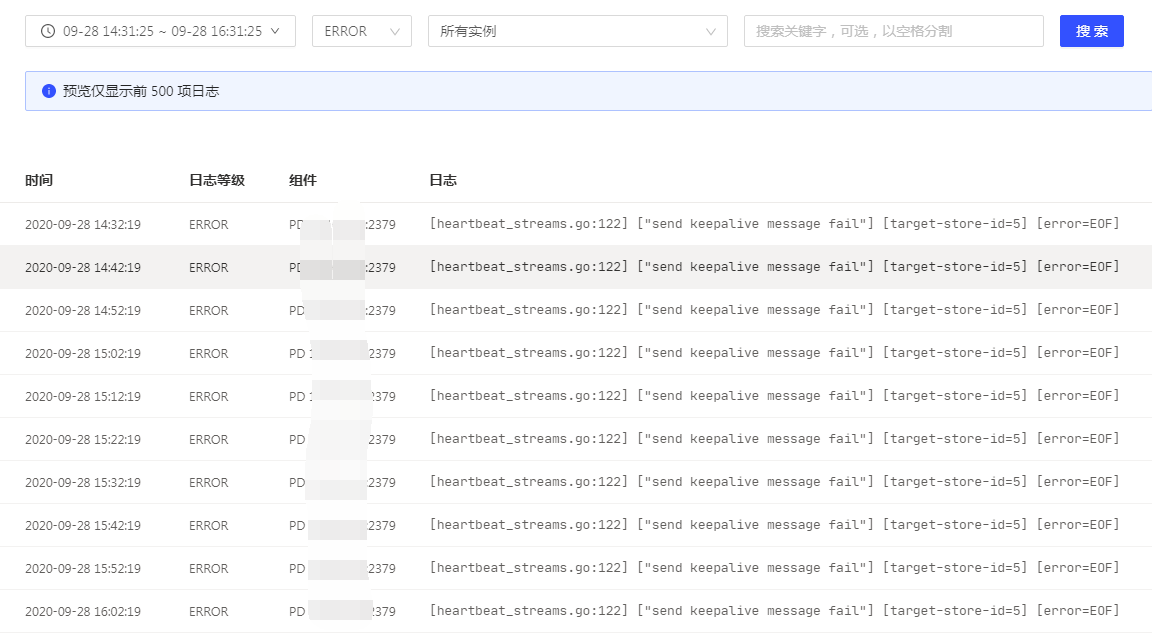
最近PD频繁报错
[heartbeat_streams.go:122] [“send keepalive message fail”] [target-store-id=5] [error=EOF]
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
最近PD频繁报错
[heartbeat_streams.go:122] [“send keepalive message fail”] [target-store-id=5] [error=EOF]
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
1、这个报错可能是 tikv 失连或者重连的时候会出现,有个 issues:
https://github.com/tikv/pd/issues/2920
2、请确认下当前 store 5 的状态,是否出现过失连、重连的情况,另外,请确认下 store 5 到 pd 的网络情况。
3、这个报错看起来时间比较规律大概 10 分钟一次,请将上述截图同时间段的 store 5 的 tikv 日志上传下~~
报错时store 5 的 tikv 日志.TXT (106.9 KB)
store 5 到 pd leader 的网络质量是怎样的,也可以检查下 store 5 和 pd leader 相互间的网络延时或者带宽占用情况:
1、store 5 和 pd leader 间的网络延时,如果部署了整套的监控可以使用 blackbox 来查看
2、store 5 以及 pd leader 的网络带宽情况,在 node-exporter 可以看到
3、store 5 到 pd 间的网络丢包情况
tikv-detail 监控:
1、整体 tikv-details 的监控,导出问题时间段对应的数据
2、单独的 store 5 的 tikv-details 的监控,导出问题时间段对应的数据
监控导出工具:
如果方便可以把相关的监控信息上传下~