gzp1
(g)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
已阅读pd的调度文档,修改了默认参数:
» config set leader-schedule-limit 16
Success!
» config set region-schedule-limit 100
Success!
» config set max-pending-peer-count 50
Success!
» config set max-snapshot-count 12
Success!
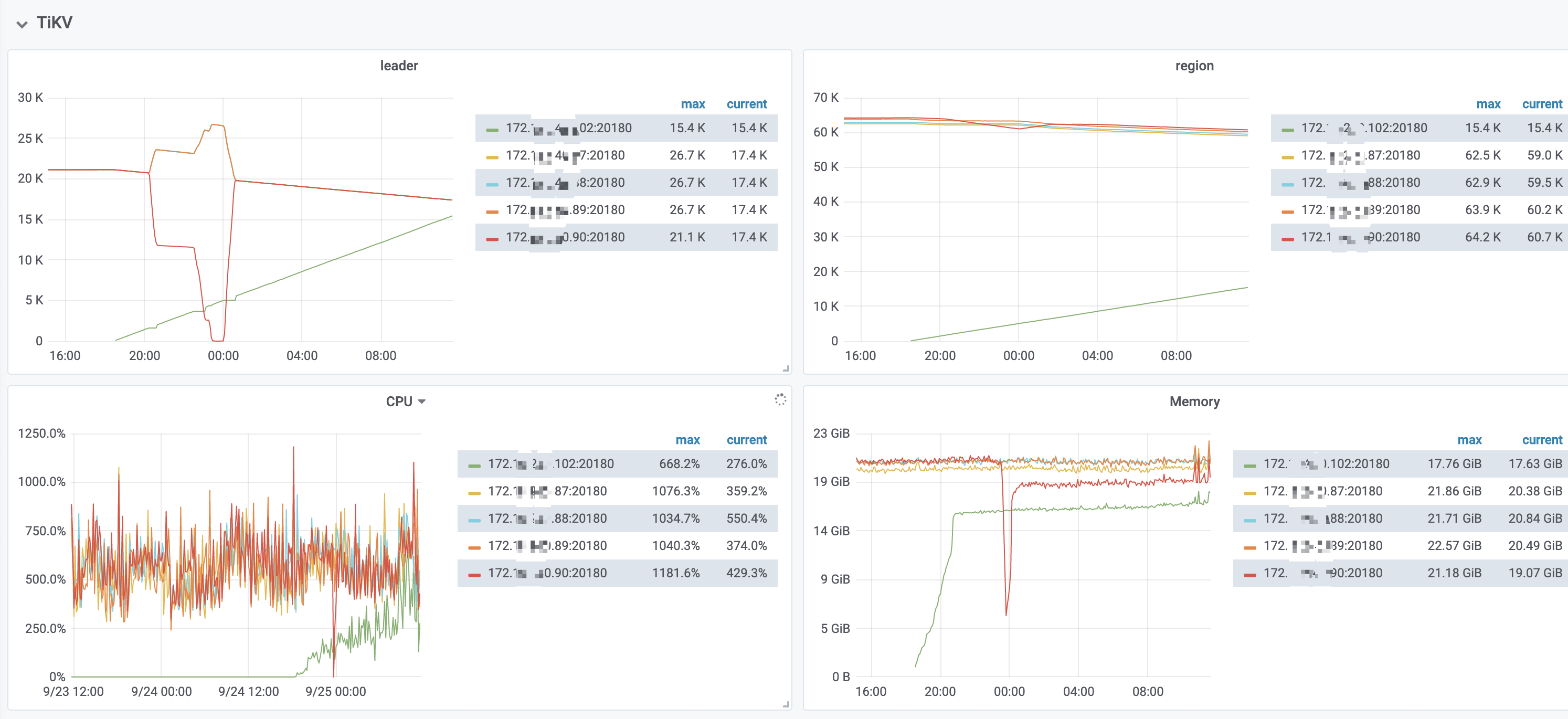
速度上看,每秒 就2个region,可以做到每秒500个region嘛?
可以导出一下 PD 的监控看下吗?看下调度的 operator 运行情况
导出监控步骤:
- 打开 PD 面板,监控时间选举最近 1 小时
- 打开 Grafana 监控面板(先按
d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
-
https://metricstool.pingcap.com/ 使用工具导出 Grafana 数据为快照
具体可以参考文档:[FAQ] Grafana Metrics 页面的导出和导入
gzp1
(g)
3
现在还没有完成,这个数据量级,已经用了快18小时了。弹性扩容 好慢
pd面板,我私信一下
region 调度的时候涉及到补副本以及 compaction ,会对磁盘影响有一定要求,看你们的集群节点磁盘 IO util 都到 100% 了,所以限制了 region 调度的速度
gzp1
(g)
7
我们的磁盘iops 是10w,写入性能约391 mb/s
这个还低?
那个图呢,一直是这样,持续快1年了,我们觉得性能没问题。基本上没有严重的报警。
主要原因是:
- 阿里云机器是c5,实例iops上限是20w
- 磁盘是essd,pl-2标准,iops上限是10w
两者不匹配,io util监控虽然不好看,但是性能没啥问题
gzp1
(g)
9
感谢!
已处理,设置了store limit 100
比原来快了8个小时,应该可以做到15min内扩容完成
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。