背景
在维护TiDB时,专业DBA应该会经常翻翻各个集群的指标、看看各个集群的慢日志和给集群核心指标配置告警等操作。一个TiDB集群有上百个指标监控,当维护少数几个TiDB集群时,应该比较happy。当维护的集群达到十几个,甚至几十个集群时,是不是不那么happy了。
有时,我们被问到以下等问题:
-
老板问,马上国庆节了,线上集群有没有风险?
-
业务leader问,某某集群,过节会有风险吗?
-
。。。。
然后,一个个集群的去排查,累不说,可能效果也不怎么好。
每个数据库集群的核心指标、核心指标的告警阀值和容忍度、一段时间核心指标的历史平均值等,这些内容关乎底层服务的稳定性,dba必须每天多次关注,随时做到全局掌控,心中有数,而不是等线上服务出了问题或者数据库告警了才去了解。
但是,这么多集群,这么多指标,如何快速的做到?我们是这样思考的:
-
集群指标虽然很多,可否挑选出少数几个指标来反映集群性能
-
TiDB集群那么多,到每个集群浏览集群指标比较耗时,可否把这些关注的指标定制到一个页面,这样可以快速熟悉
基于上述需求,通常有以下几种做法:
-
搭建一套单独的grafana,数据源配置成各集群TiDB prometheus地址,再定制各指标dashboard
-
采用prometheus联邦机制
-
单独采集,定制dashboard
我们采用了第一种方案,简单高效,下面介绍下如何定制TiDB性能大盘。
大盘定制过程
1、安装grafana
2、定制你所需要的数据源,比如线上TiDB集群地址,如下图所示
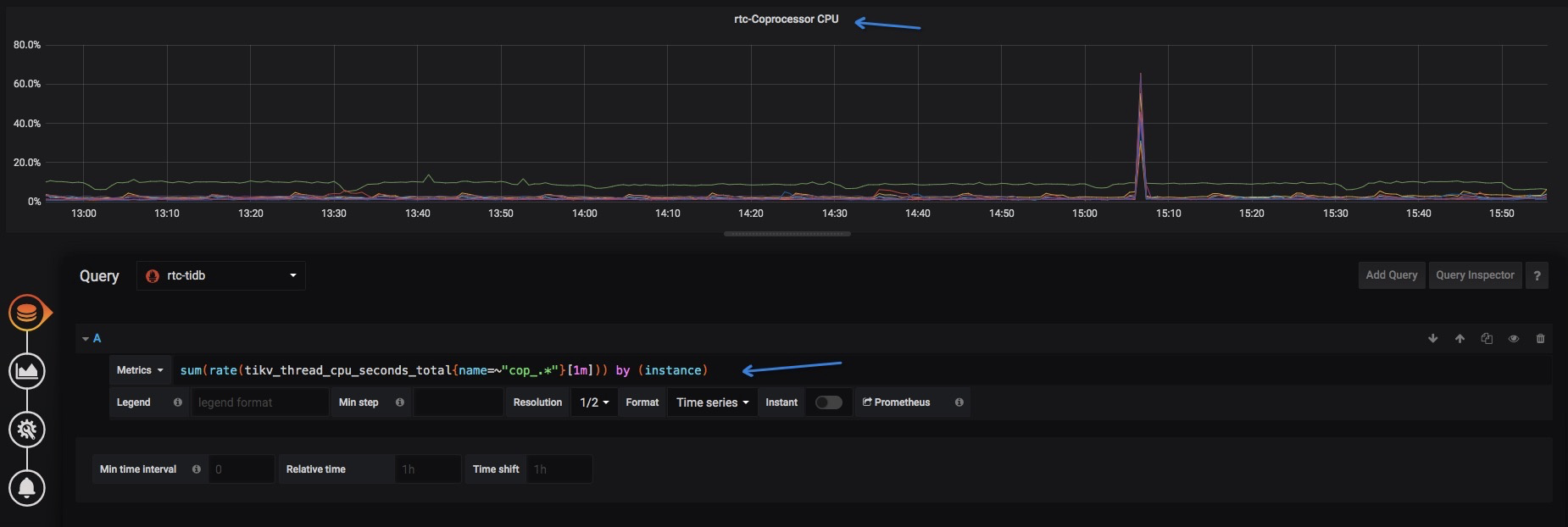
3、定制自己想要的监控指标和页面,对于一个TiDB集群,我们挑选了node cpu、raftstore cpu、comprocessor cpu和duration4个指标,日常问题,这几个指标很快能反映出问题,大家可以挑选自己关注的指标。定制过程如下所示。
- 参考源集群,拷贝对应的指标公式到定制的大盘
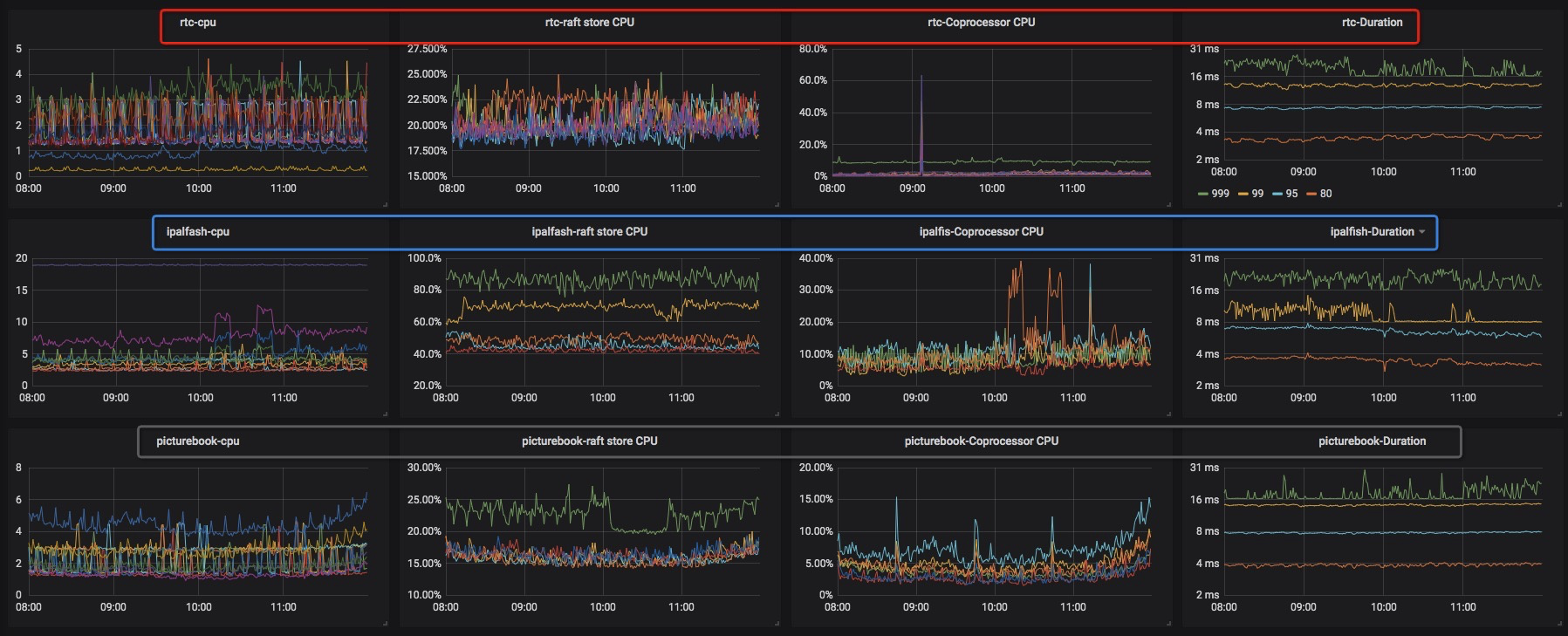
- 最终把我们需要关注的业务TiDB集群指标定制在一个页面上,我们配置的其中3个集群的指标,如下图所示
日常案例
由于对集群指标进行了精简,DBA每天都会在业务早高峰、午高峰和晚高峰对大盘进行巡检,几秒内线上十几个集群的性能尽收眼底。同时由于每天例行做这个事情,每个集群的指标历史平均值,DBA都能熟记于心了。一个业务集群,请求量大+业务快速迭代,对于服务的稳定性,挑战还是非常大的,所以只要指标有个小波动,DBA都会及时处理掉。这样做带来几个好处:
-
性能问题扼杀在萌芽阶段。事前把这些事给做好,代价较小,事后做可能花的代价很大
-
无形中,研发同学对数据库性能问题更重视了
-
DBA越来越轻松
我们通过巡检,发现和解决了很多萌芽的性能问题,所以我们数据库(除一次优化器bug,导致大表走错索引,短暂影响线上外)性能还是比较优秀的,下面讲讲,我们发现并处理的几个性能问题。
第一个例子:
我们最核心的直播集群,巡检发现,某天延迟出现小幅抖动,如下图。
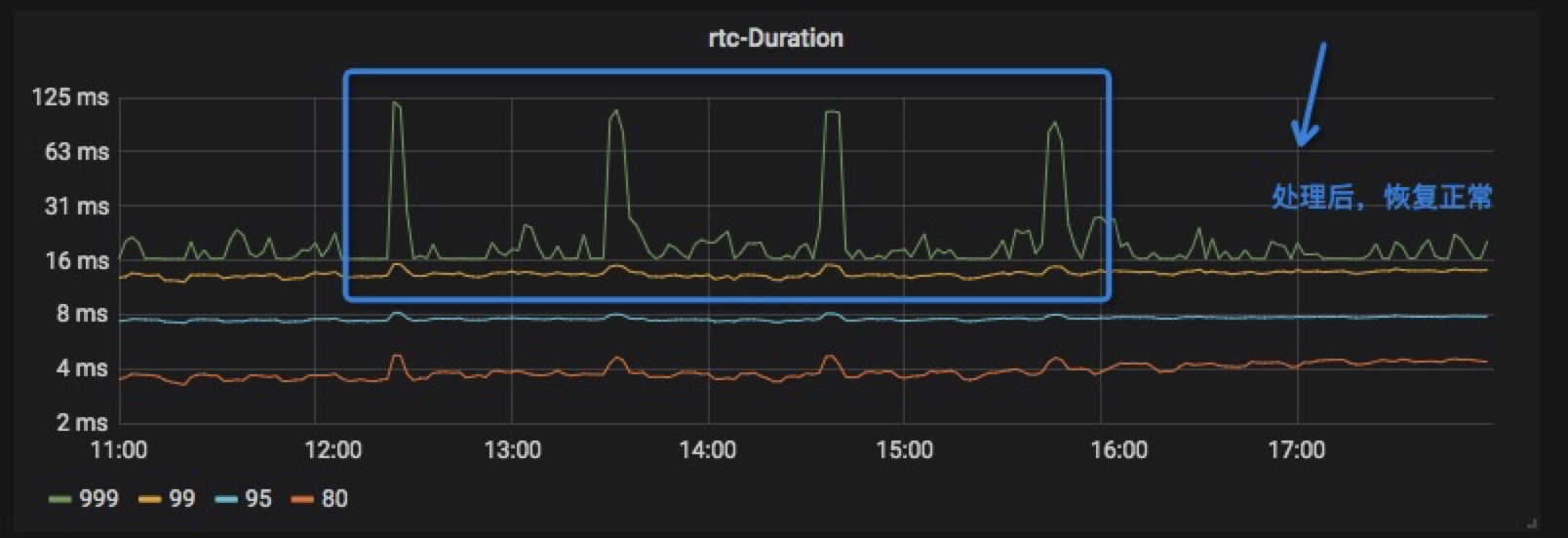
我们的时延告警阀值是125ms,此时这种波动,监控是无法告警出来的。这种小幅度的波动,基本不会影响线上其它请求。从其它2个指标可以看出来,如下图。

这种问题,短时间不处理,也不会出现什么大的问题。但如果发展到事后做,可能付出的代价会很大。
第二个例子:
某集群巡检发现,comprocessor cpu较历史值,有小幅增长(历史值维持在10%以下,我们的机器是64核,理论承载能力可以达到5000%-6000%),如下图所示。
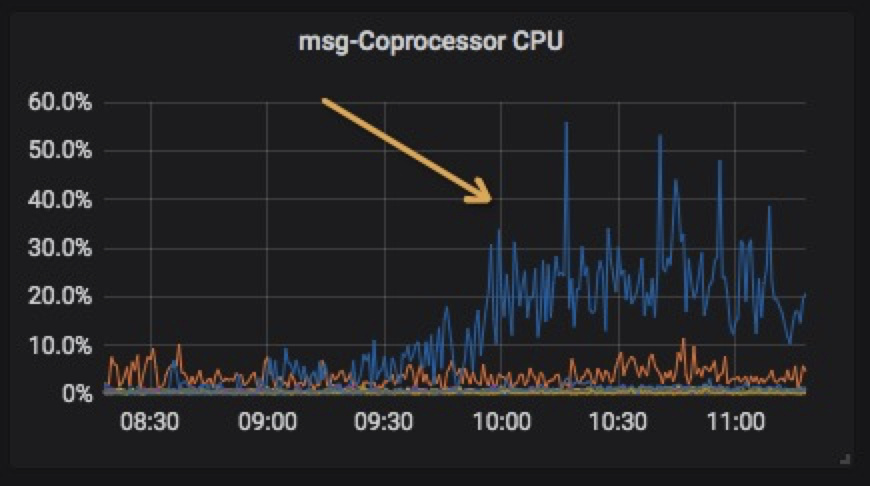
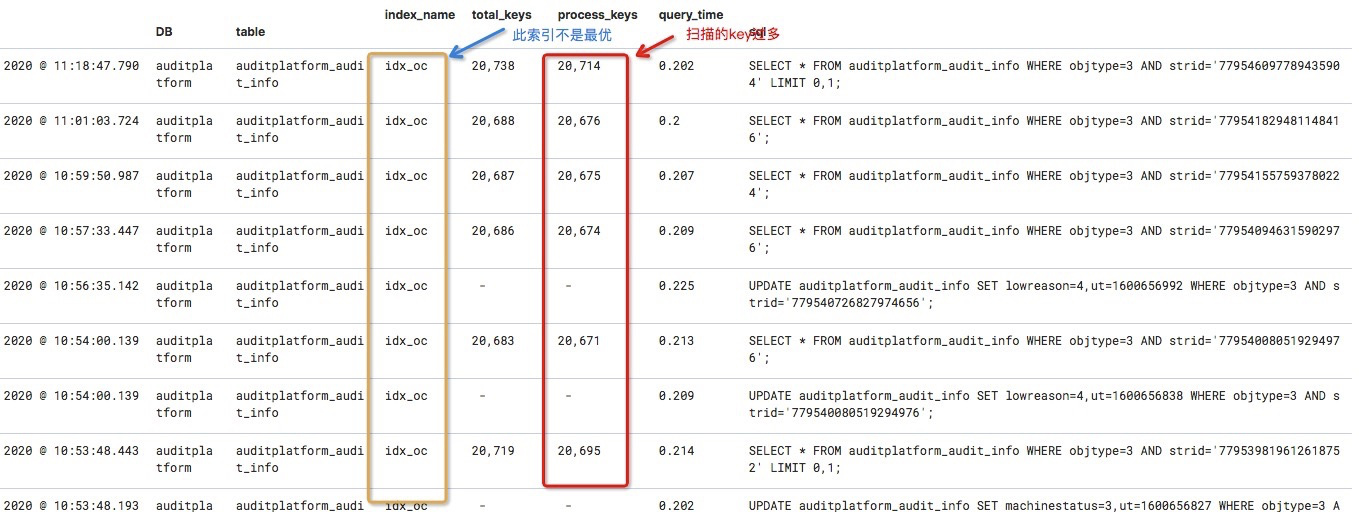
通过慢日志系统发现,查询只走了部分索引,导致性能变差,我们通过修改索引,迅速解决。
在业务高速发展的背景下,数据库服务,要做到一个季度、半年、甚至一年不出故障,还是有挑战的。最好的方式,是在事前,把很多事情做好,做到数据库运维精细化,比如SQL审核,慢日志、规范等等。
最后
上述技巧没有什么技术含量,但是方便实用。比如:
1、DBA可以快速熟悉各业务集群的性能,预测风险
2、业务研发做什么操作时,比如跑批等,可以随时关注操作对线上性能有无影响
3、等等
小技巧希望能帮到大家。每天花几秒钟看看,再也不担心老板问了 ![]()