zhanglei
(Zhanglei)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
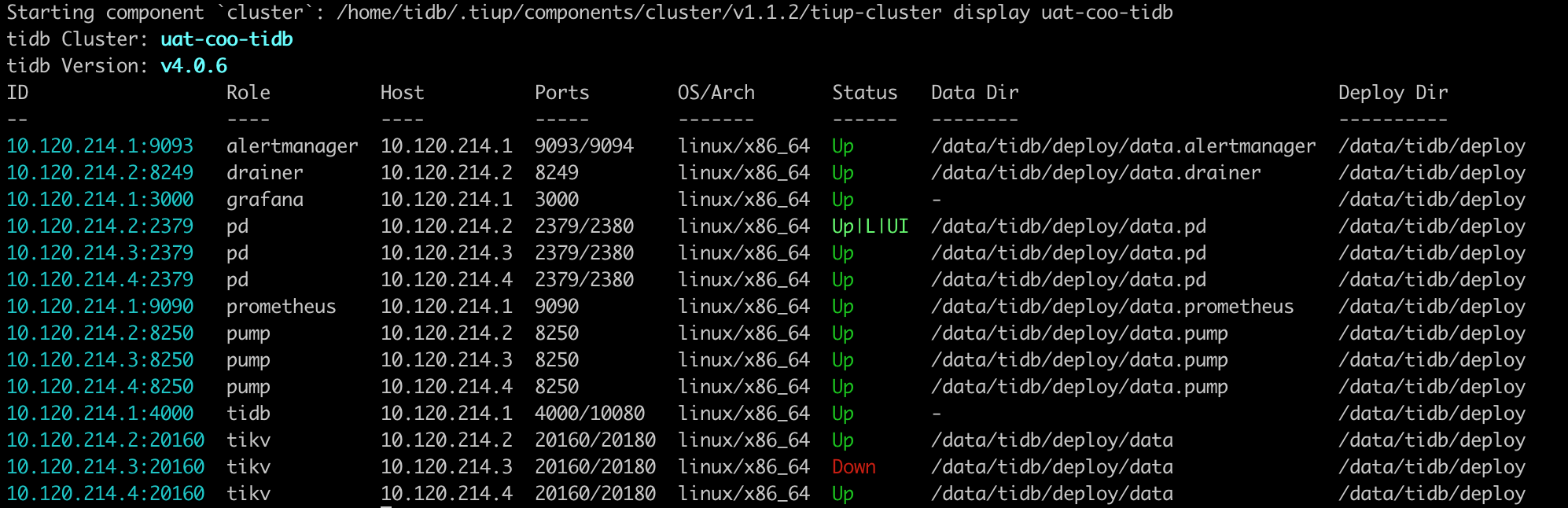
在测试环境执行tiup cluster reload --force,有一个tikv无法启动,报错信息:
[2020/09/16 20:11:12.266 +08:00] [FATAL] [server.rs:357] [“failed to create kv engine: RocksDb Corruption: Blob file 123646 has been deleted twice”]
该环境tikv为单副本
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
zhanglei
(Zhanglei)
4
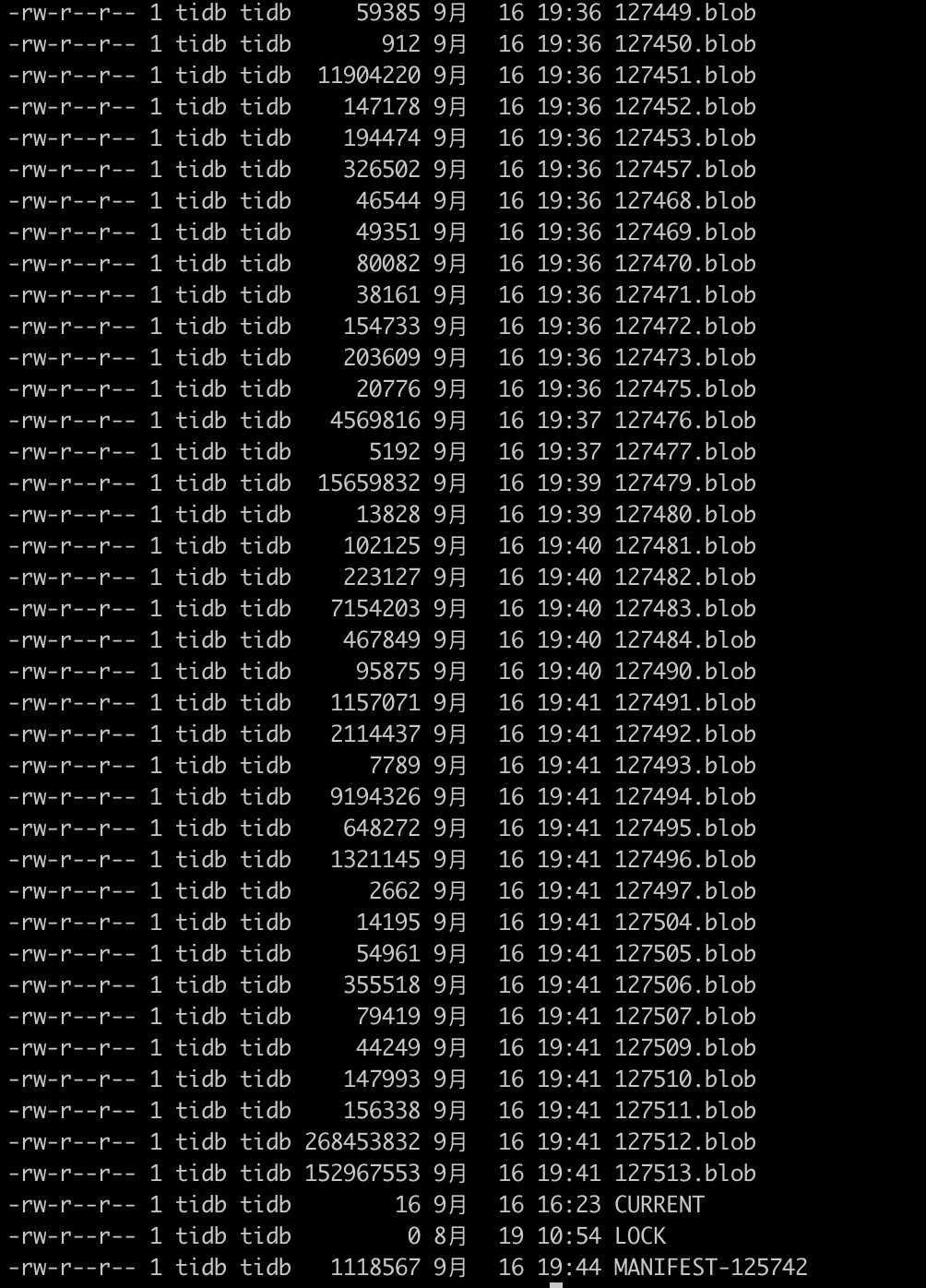
/data/tidb/deploy/data/db/titandb目前找不到123646.blob文件,有办法修改元数据信息不?
zhanglei
(Zhanglei)
5
tikv.toml
WARNING: This file is auto-generated. Do not edit! All your modification will be overwritten!
You can use ‘tiup cluster edit-config’ and ‘tiup cluster reload’ to update the configuration
All configuration items you want to change can be added to:
server_configs:
tikv:
aa.b1.c3: value
aa.b2.c4: value
[coprocessor]
split-region-on-table = false
[gc]
max-write-bytes-per-sec = “128K”
[import]
[metric]
[pd]
[pessimistic-txn]
pipelined = true
[raftdb]
[raftdb.defaultcf]
[raftstore]
apply-pool-size = 3
hibernate-regions = true
raft-base-tick-interval = “2s”
raft-max-inflight-msgs = 1024
raftdb-path = “”
store-pool-size = 3
sync-log = false
[readpool]
[readpool.coprocessor]
[readpool.storage]
use-unified-pool = true
[readpool.unified]
max-thread-count = 4
[rocksdb]
max-background-jobs = 3
max-sub-compactions = 1
rate-bytes-per-sec = “64M”
wal-dir = “”
[rocksdb.defaultcf]
compression-per-level = [“no”, “no”, “zstd”, “zstd”, “zstd”, “zstd”, “zstd”]
[rocksdb.defaultcf.titan]
level-merge = true
[rocksdb.lockcf]
[rocksdb.titan]
enabled = true
[rocksdb.writecf]
[security]
ca-path = “”
cert-path = “”
key-path = “”
[server]
grpc-concurrency = 2
[server.labels]
[storage]
scheduler-worker-pool-size = 2
[storage.block-cache]
shared = true
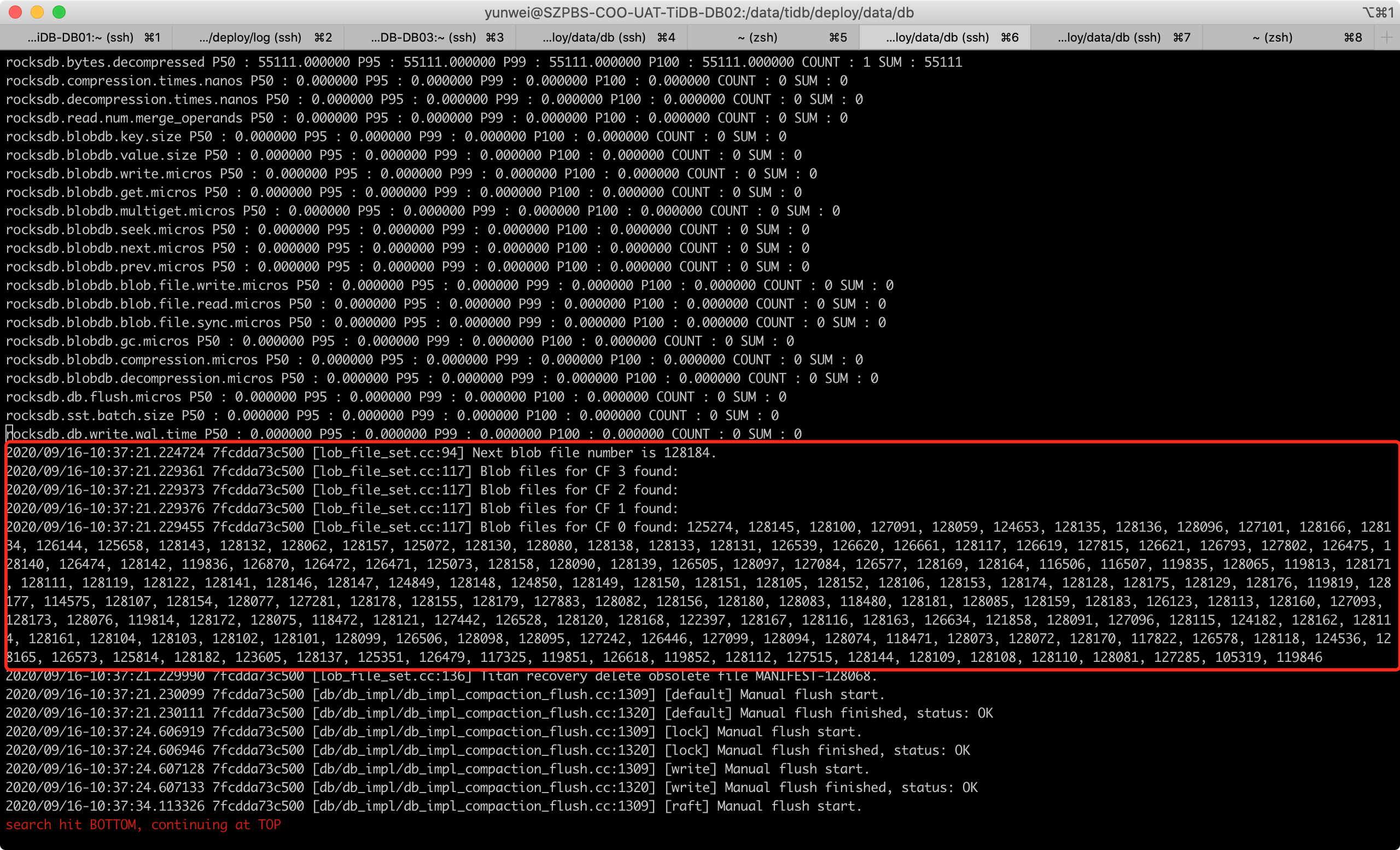
再麻烦拿一下这个故障 TiKV 节点的 rocksdb 日志,就是data/db 目录下的 rocksdb.info*
zhanglei
(Zhanglei)
9
zhanglei
(Zhanglei)
10
从另外2个正常tikv节点的日志上看,是在这一步214.3节点找123646.blob文件找不到引起下面无法进行
那麻烦将 LOG.old.* 的所有文件麻烦打包都拿一下。
zhanglei
(Zhanglei)
12
tikv_rockdbs_log_214.3.tar.gz (87.5 KB)
故障节点214.3 rockdbs日志
zhanglei
(Zhanglei)
14
感觉214.3节点LOG.old不太全,正常节点214.2最早的日志时间是09-15 11:54的
出故障无法启动有手动在214.3节点执行tikv-ctl --db /data/tidb/deploy/data/db compact,不知道是否会清除日志
嗯,日志因为重启已经被自动 rotate 掉了,你还有之前的日志么?123646.blob 没有是正常的,只是元信息里面记录了它被删除了两次所以导致启动不起来。
zhanglei
(Zhanglei)
16
214.3节点没有之前的日志了,这个目前有办法跳过不(比如改下元信息)?还有4.0.6之前版本也有经常执行reload -force(该环境从3.0.1版本追到4.0.5版本,使用1年),从未出现过类似情况,昨天上午刚升级4.0.6版本,下午就出现这个问题了
zhanglei
(Zhanglei)
18
pd加了一个dashboard.enable-experimental: true参数