为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:3.0.8
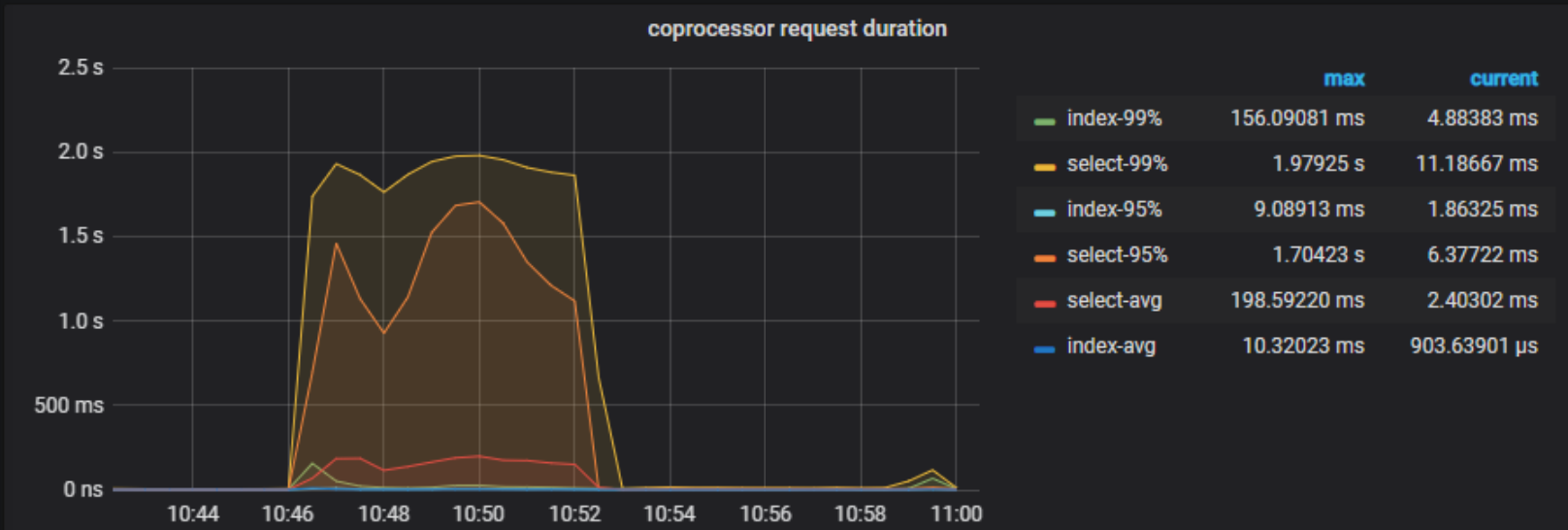
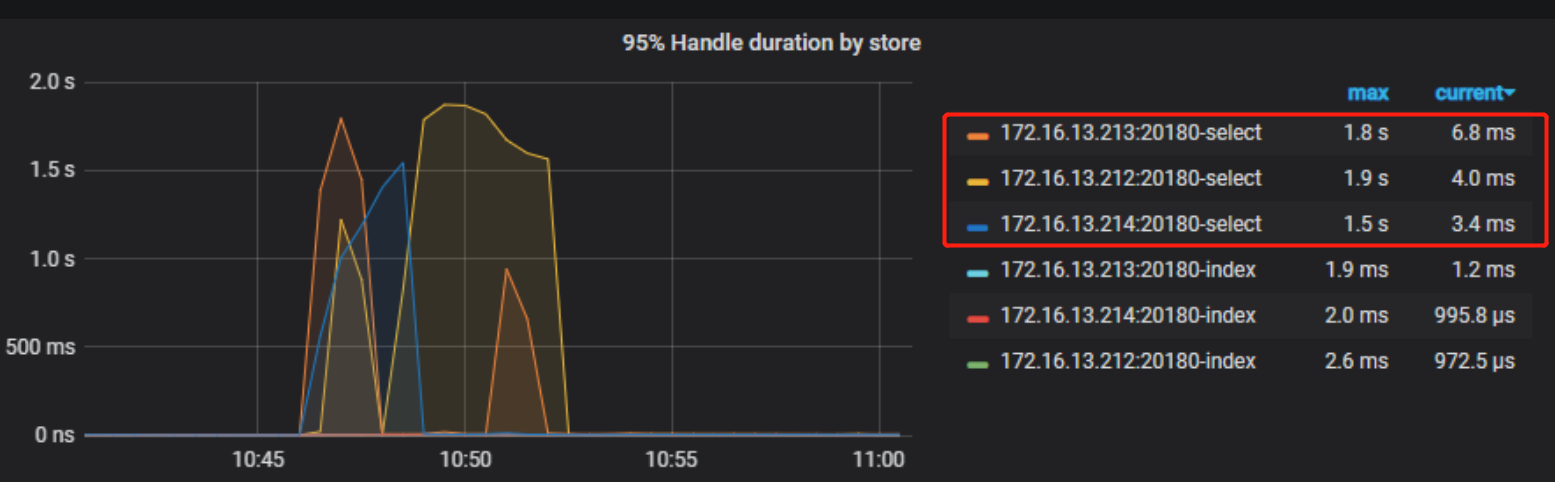
【问题描述】:在数据库中,平时一条SQL的响应时间最多几十毫秒,但是如果有慢SQL执行,会让整个系统的所有SQL执行响应时间上升到2秒中,拖垮整个集群,这个是什么原理导致的呢
SELECT log.result_code, count(*)
表merchant_log中数据1.3亿
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出打印结果,请务必全选 并复制粘贴上传。
2、这个服务器是阿里云内网,实例都是IO优化型,内网带宽为万兆网络
这个SQL存在优化空间,但是不太理解为什么一条SQL,会把整个集群拖垮,就算mysql执行一个慢查询,也不会把其他所有SQL都影响了呀,我这边查询中,只使用到了一张表
如果系统中存在大量慢查询,影响整个系统我还是能够理解到,但是一条慢查询导致整个系统都慢下来,这个原理方便介绍一下吗
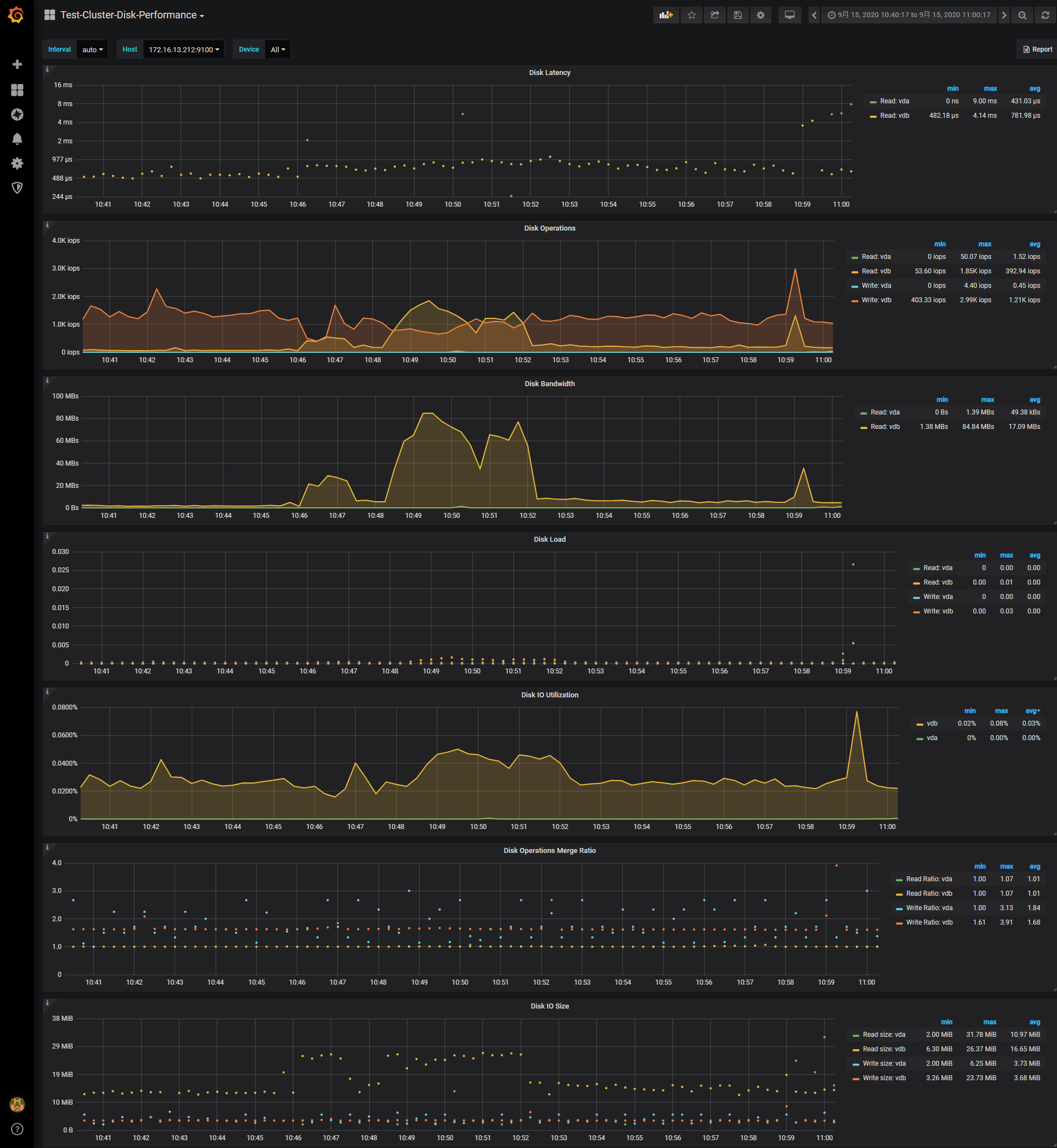
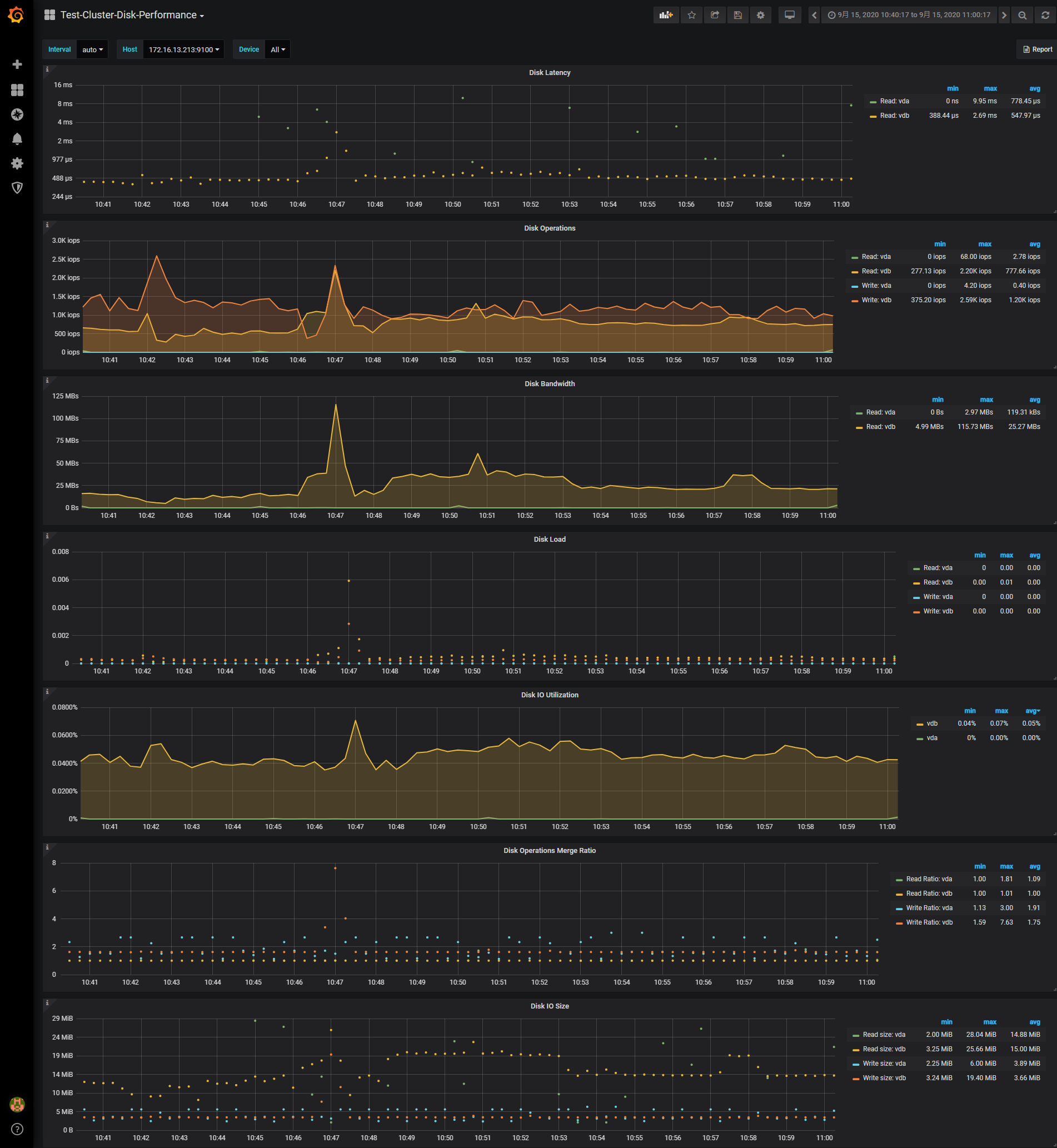
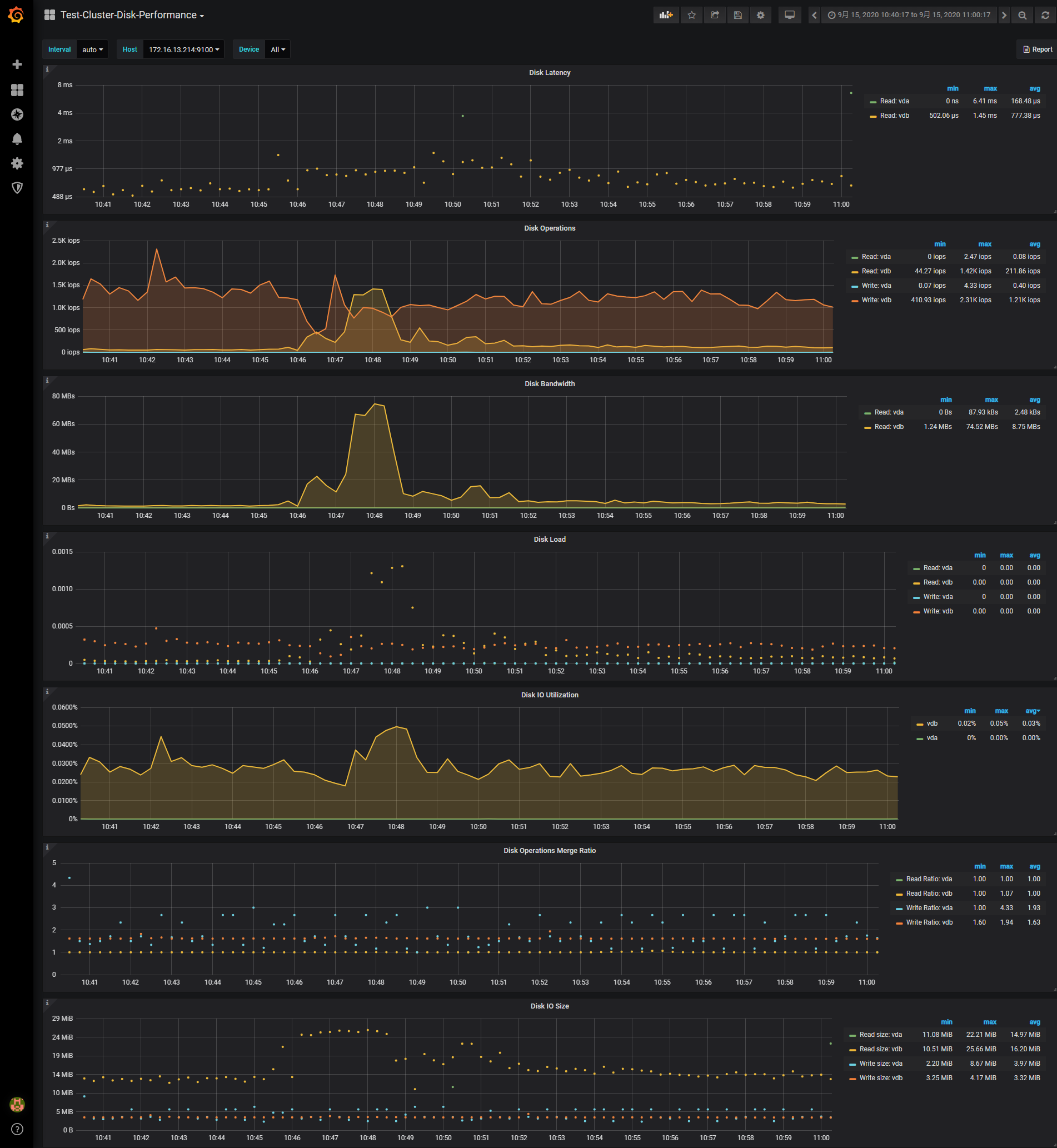
1、其他监控信息
2、从数据库角度出发,一条SQL导致整个数据库集群性能下降,不太能接受,有办法限制这种情况吗
yilong
2020 年9 月 16 日 11:43
8
一个sql和多个sql没有什么区别, coprocessor 查询耗时多,导致整体升高,可以先优化 sql,降低大量扫描.
这个算不算tidb的一个缺陷呢,Mysql中相同的慢查询,几乎不会对系统有较大的影响,tidb并没有做到较好的资源隔离吧。
yilong
2020 年9 月 17 日 03:10
10
MySQL 没有有资源隔离吧,MySQL 和 Oracle 也会有这种问题, 一个大 SQL 对整个库产生影响。 不过,TiDB 在这里也会持续优化,多谢。
在mysql中,有参数innodb_concurrency_tickets限制一次CPU时间获取5000条记录,然后执行其他SQL,这样就不会有一条SQL执行其他SQL都被拖慢的情况,请问tidb中有这个类似的参数吗
yilong
2020 年9 月 21 日 02:14
12