- 【TiDB 版本】:3.0.18
- 【问题描述】:
在使用mydumper备份,lightning导入,metadata的点位让drainer做增量同步的时候,发现了一些问题。
drainer status和日志里的point,都是在启动drainer时间范围的点位,并没有从提前编写好的–initial-commit-ts开始。
导致我不确定当前同步的真实进度,以及中间的数据是否已经丢失?
可以确认point的时间还在gc的有效范围内,720h。
在使用mydumper备份,lightning导入,metadata的点位让drainer做增量同步的时候,发现了一些问题。
drainer status和日志里的point,都是在启动drainer时间范围的点位,并没有从提前编写好的–initial-commit-ts开始。
导致我不确定当前同步的真实进度,以及中间的数据是否已经丢失?
可以确认point的时间还在gc的有效范围内,720h。
Hello ~ 根据你的描述,Drainer log 中如果一直有 write savepoint ts 记录,说明正常消费 binlog 日志。如果想确认同步的延迟情况,可以关注 Drainer 的监控,里面也会有详细的介绍。
https://docs.pingcap.com/zh/tidb/stable/monitor-tidb-binlog-cluster
可是那个drainer是我新部署的, 有点奇怪。
那请问对于这种情况,怎么使用mydumper中的ts点位继续增量同步呢?
给一下 drainer toml 文件看下,主要关注 commt-ts 的设置,并提供下如何获取的 mudumper 导出的 ts 信息。
提供下集群部署方式。
tidb binlog 版本信息
v3.0.11
Started dump at: 2020-09-01 14:37:48
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 419153121987791863
GTID:
Finished dump at: 2020-09-06 03:06:58
detect-interval = 10
[syncer]
ignore-schemas = "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql"
txn-batch = 512
worker-count = 1024
disable-dispatch = false
safe-mode = false
db-type = "tidb"
ignore-txn-commit-ts = []
[[syncer.replicate-do-table]]
db-name ="sds_data"
tbl-name = "fvp_scan_gun"
[[syncer.replicate-do-table]]
db-name ="sds_data"
tbl-name = "oms_waybill_tidb"
[[syncer.replicate-do-table]]
db-name ="sds_data"
tbl-name = "sgs_waybill_tidb"
[syncer.to]
host = "10.189.200.15"
user = "tidb_test"
password = "xxx"
port = 4000
#!/bin/bash
set -e
ulimit -n 1000000
DEPLOY_DIR=/home/tidb/tidb_sds-v3
cd "${DEPLOY_DIR}" || exit 1
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
exec bin/drainer \
--addr="10.189.200.13:8249" \
--pd-urls="http://10.188.36.2:4250,http://10.188.36.3:4250,http://10.188.36.4:4250" \
--data-dir="/home/tidb/tidb_sds-v3/data.drainer" \
--log-file="/home/tidb/tidb_sds-v3/log/drainer.log" \
--config=conf/drainer.toml \
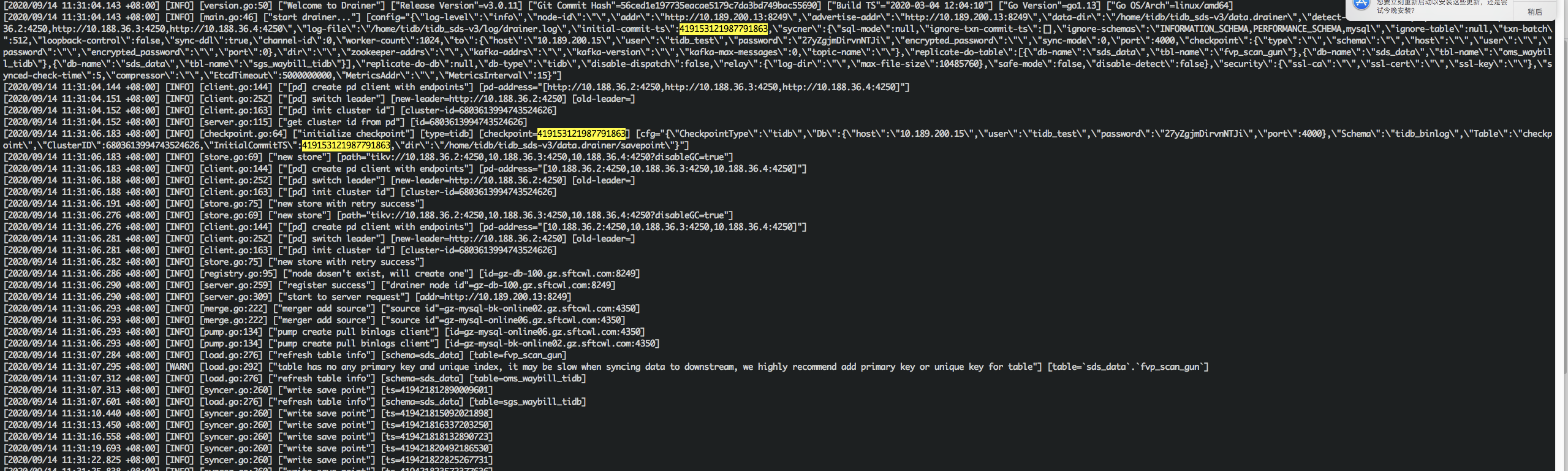
--initial-commit-ts="419153121987791863" 2>> "/home/tidb/tidb_sds-v3/log/drainer_stderr.log"
先确认下 tidb binlog 版本和 tidb 集群版本是否相符哈,从提供的信息目前无法判断。
initial-commit-ts 加载 drainer toml 试下。run-drainer.sh 不需要手动修改。
Release Version: v3.0.11
Git Commit Hash: 56ced1e197735eacae5179c7da3bd749bac55690
Build TS: 2020-03-04 12:03:46
Go Version: go1.13
Go OS/Arch: linux/amd64
Release Version: v3.0.11
Git Commit Hash: 56ced1e197735eacae5179c7da3bd749bac55690
Build TS: 2020-03-04 12:04:10
Go Version: go1.13
Go OS/Arch: linux/amd64
部署方式是ansible, run-drainer.sh是自动下发的,点位也正确。我理解跟写conf里没什么区别??
drainer_tidb ansible_host=10.189.200.13 initial_commit_ts=“419153121987791863”
你好,那个集群版本是 3.0.18 ?如果是请先统一下版本在进行测试
源端是3.0.11, 下游新集群是3.0.18
之前我从2.x用这种方式升级到了3.0.11,都没这个问题!
除了initial_commit_ts,还有其他参数可以强制点位吗?
期待回复, 这是否是一个bug?
那版本这是没问题的。
那你的 initial-commit-ts 在哪里设置的呢,在 drainer toml 也没看到。。
与此参数平级,设置下:
initial-commit-ts: 419153121987791863
ansible部署后,自动打到shell脚本里的。
我发的日志里你可也可以看到,读取到了正确的initial_commit_ts。 但是后面就跳到其他点位了。
当前的问题是什么,辛苦在讲下,有点搞蒙了
这个值得是什么?initial_commit_ts 一次使用就没效了。 drainer 会刷新当前的 commit ts 预期的,如果 drainer log 中没有 error 等明显报错可以通过 sync-diff-inspector 工具验证数据的准确性
日志截图里,很清楚的可以看到,正确读取到了initial_commit_ts,随后在write save point和show drainer status里面看到的,都是非常新的点位, 中间6天的数据就直接忽略了。
是我描述的有问题吗????
上游 binlog 拉取应该是顺序拉取,消费会保证按顺序消费,但是读取 binlog 不一定是连续的。所以不用担心这个 position 位置差异问题,我们那会保证同步到下游数据是有序的。
感谢回复,show drainer status里面看到的是消费顺序吗?
我看到也是最新的ts位置,并且查询了一下没有期望的增量数据写入进来,写入的都是最新的数据。
不过source端的集群原来有过其他drainer,或许没有正常下线,本次是新增的drainer,跟这有关系吗?
通过 drainer.log 更加清晰一些
期望的增量数据指的是什么,如果是 initial_commit_ts 之后的数据新增没有同步到下游不符合预期的(请查看是否增加了其他的过滤条件)。
show drainer status; 展示内容如下,可以通过 State 字段看下状态是否为 online。
https://docs.pingcap.com/zh/tidb/stable/sql-statement-show-drainer-status#show-drainer-status
感谢反馈解决方案,如果你有其他问题,麻烦提交新的问题帖子。