- 【TiDB 版本】:tidb4.0.5(tidb3.0.11使用tiup升级到4.0.0后滚动升级到4.0.5)
- 【问题描述】:
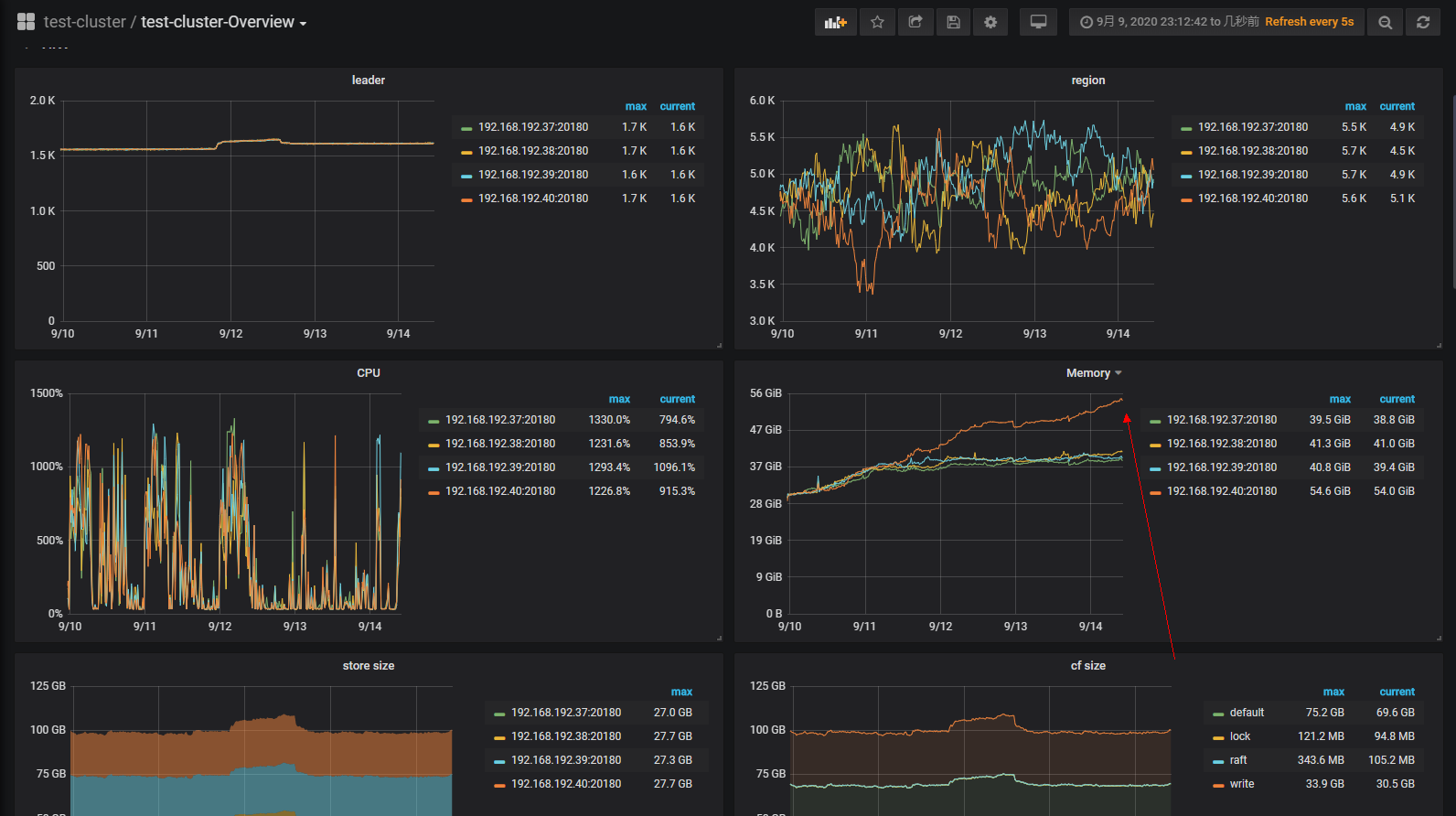
1、查看监控面板发下有一台kv的内存使用居高不下,一直在增长没有释放。请问该如何定位这种情况?这种情况是如何产生的?如何解决这种情况?
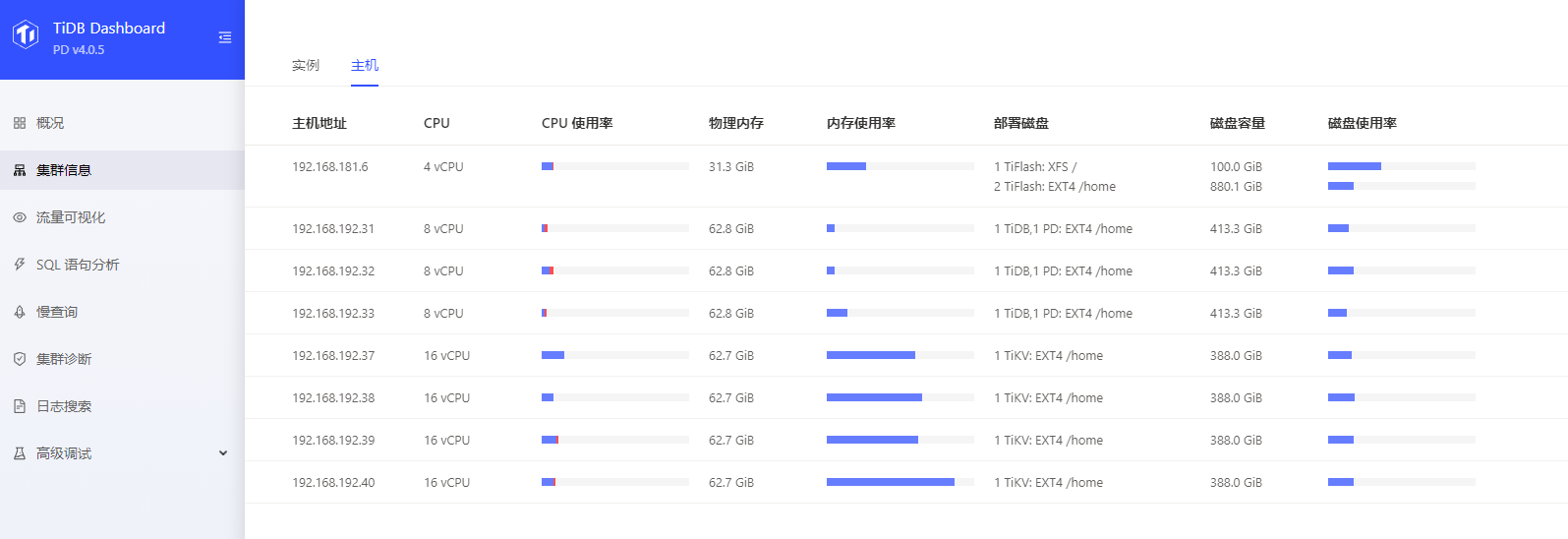
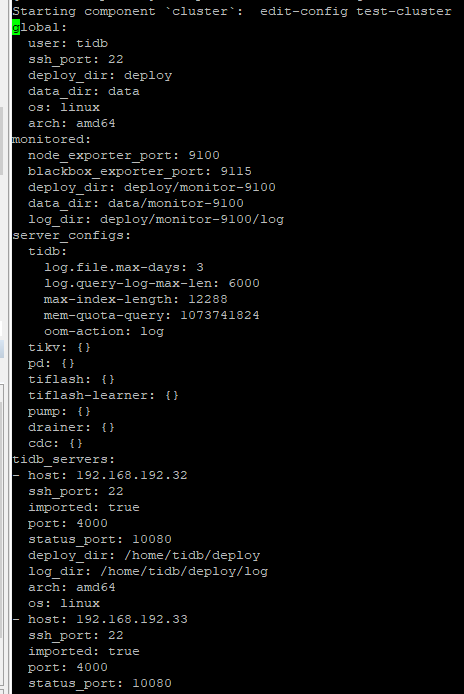
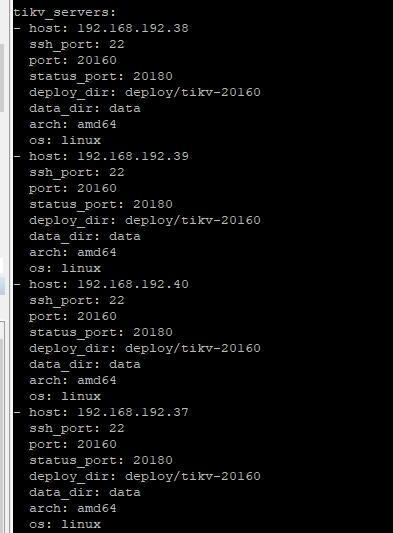
各个node配置如下:
1 个赞
- 麻烦确认一下各个 TiKV 的参数设置都是一致的
- 9-11 开始内存出现差距的情况,9-11 是做了升级操作还是有别的操作?

先按照 《Tidb in Action》排查下常见的 OOM 场景,尤其是确认内存使用是否超过了正常的阈值,如果没有那应该属于正常行为 https://book.tidb.io/session4/chapter7/tidb-oom.html#1-如何快速确认-tidb-server-出现了-oom
另外需要这段时间的完整监控数据才能进一步分析问题
这个该如何定位解决啊。
https://github.com/pingcap/tidb-map/blob/master/maps/diagnose-map.png 可以尝试参考这里,如果是 bug 引起的,那就需要具体问题具体分析了
多谢,我看了下您让我参考的主要是关于报错的问题的定位。
1、我这边的问题是,四台kv都是同样的配置,没有对kv单独做过配置修改,为什么其中一台kv内存使用偏高其他三台正常,该如何定位是什么原因能对kv造成这样的影响。
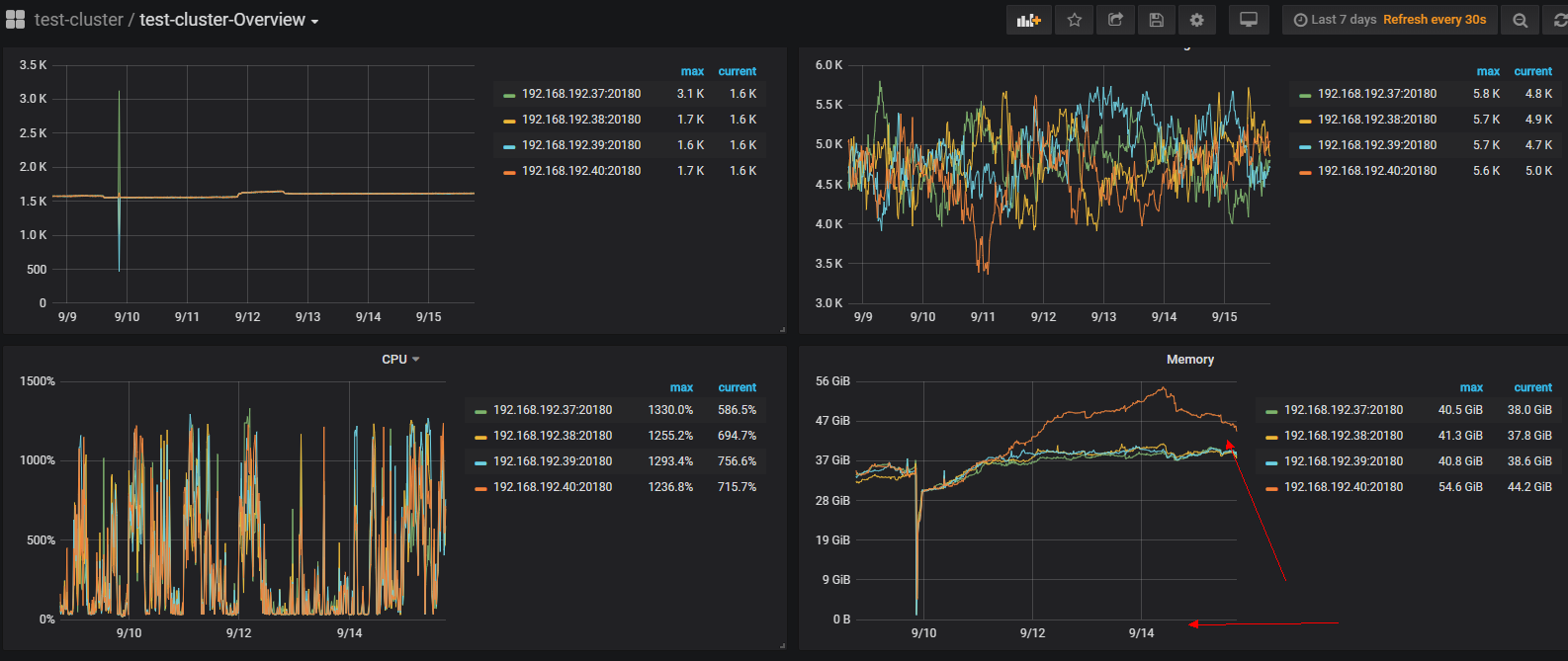
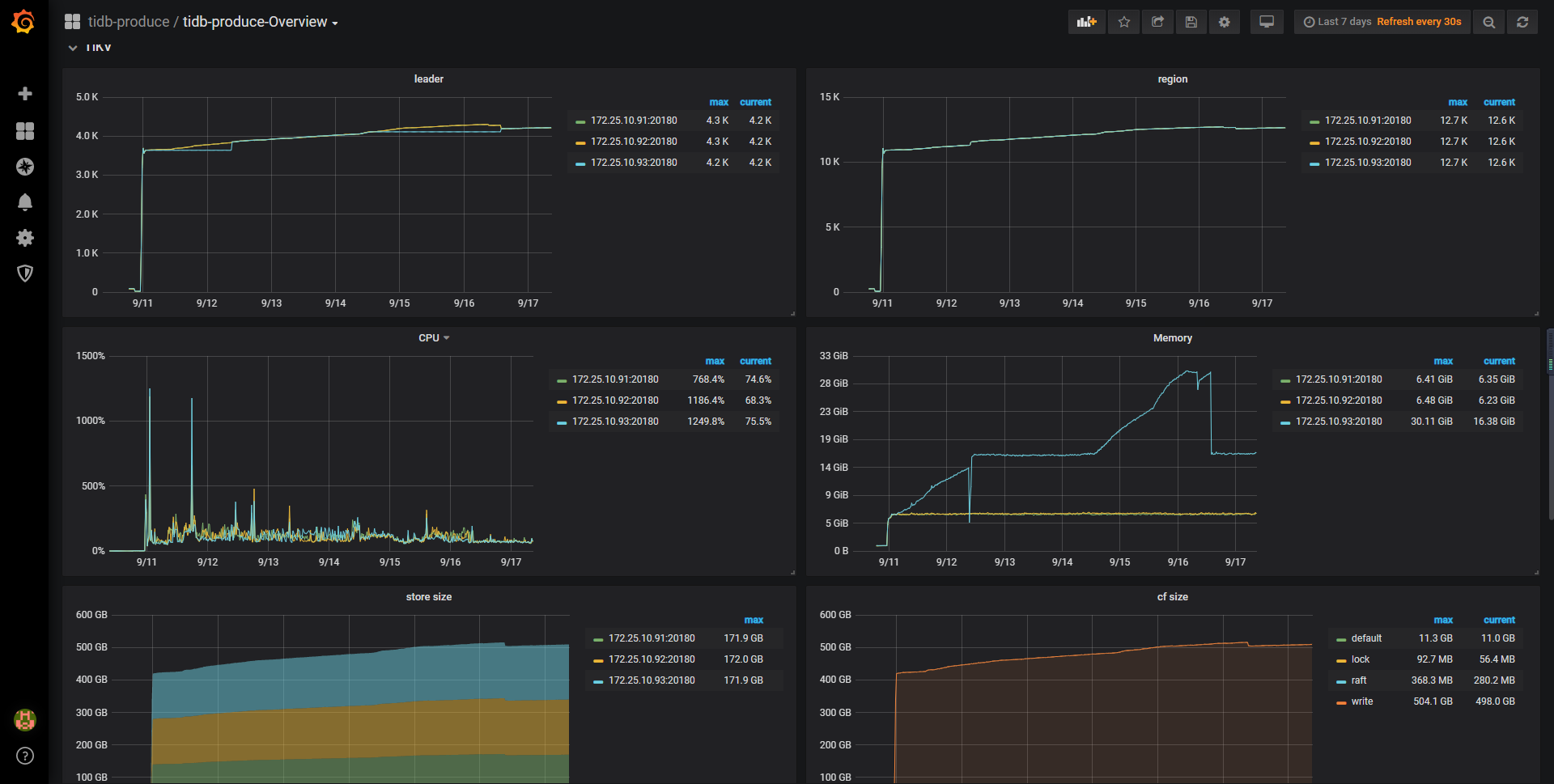
以下截图可以看出是连续三天其中一台kv内存使用增大,没有跟其他三台kv一样均匀使用。
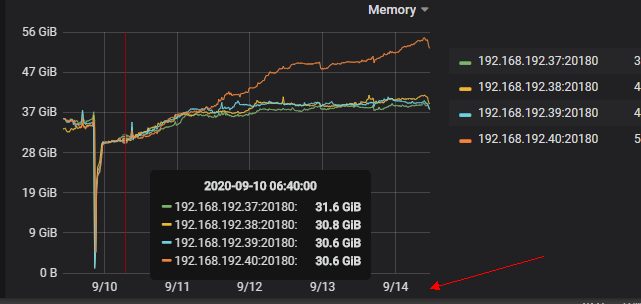
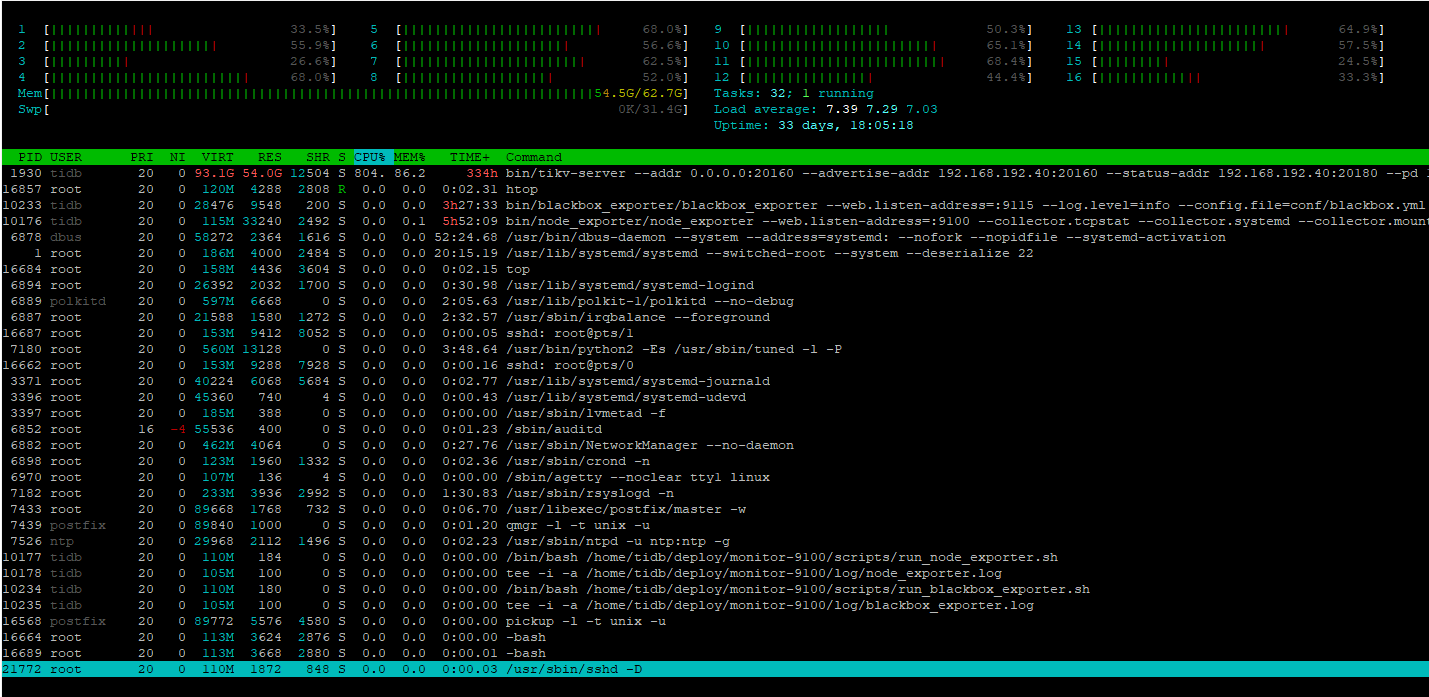
且查看kv所在的服务器并没有oom
哪个老师有时间可以帮忙看下么,生产环境出现的问题,比较着急查找产生此状况的原因,谢谢
- 可以查看 slow sql ,是否有占用内存很多的 sql,一直没有释放?
- 当前看起来占用的内存已经比较多,可以在业务低峰期,收集下profile文件,方便查看内存占用
curl -G “ip:port/debug/pprof/heap?seconds=30” > heap.profile
ip地址为tidb服务器的ip,端口为tidb_status_port的端口
1 个赞
可以提供下 rocksdb 面板下的同时间监控吗
{kind=link}
我这边看了下系统配置唯一不同的就是内核版本,这个会有影响么。
内存使用偏高的版本是
Linux prdtikv40 5.8.0-1.el7.elrepo.x86_64 #1 SMP Sun Aug 2 18:18:16 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux
其他三台kv服务器是
Linux prdtikv39 5.7.11-1.el7.elrepo.x86_64 #1 SMP Wed Jul 29 08:19:50 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux
比较着急,多谢帮忙分析
2020-09-18_095514.z01 (5 MB) 2020-09-18_095514.z02 (5 MB) 2020-09-18_095514.zip (1.5 MB)
可以在最上面的 instance 那里修改成出问题那个节点吗,不然 metric 混在一起不便于排查,时间范围不用设置太长,最好从出问题开始前几小时到后几小时的范围就好
Node_exporter 面板下的 TCP 分栏麻烦也看下
tiup ctl tikv --host 127.0.0.1:20160 metrics -t jemalloc > jemalloc.stat 再提供下这个统计文件吧,在出问题的时间段,还有对应时间段的 TiKV LOG