- 【TiDB 版本】:v4.0.0
- 【问题描述】:在利用dm迁移MySQL到TiDB过程中,出现如下问题,整体库表迁移,非分库分表:
1.“RawCause”: “Error 1062: Duplicate entry ’ com.tencent.tmgp.* ’ for key ‘PRIMARY’”
主键冲突,在目标库中查询,发现确实已经存在数据:

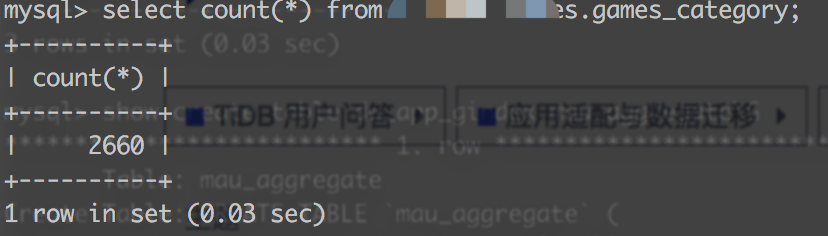
2.数据量比源库多,有数据在源库中查询不到
源库:
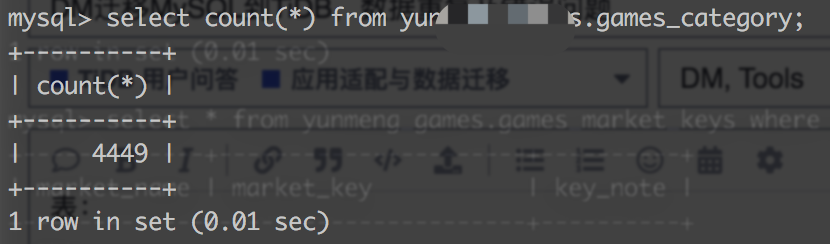
TiDB:
麻烦帮忙看看,谢谢
1.“RawCause”: “Error 1062: Duplicate entry ’ com.tencent.tmgp.* ’ for key ‘PRIMARY’”
主键冲突,在目标库中查询,发现确实已经存在数据:
按照原帖回复,建议升级到 v1.0.6 或者 v2.0.0 看看
你好,现在用的 DM 2.0.0-rc2 的版本,请问数据是重新进行同步的吗?
升级之后建议你这边清理数据后重新进行同步,数据已经通过 DM 老版本同步到下游了,如果是低版本的 bug 导致数据重复,数据已经写入到下游中,升级后数据也是存在在下游中的。所以升级到高版本之后需要清理数据后重新同步。
如果当前状态是高版本,并且数据是重新同步到下游的。辛苦提供下 task 配置,以及 dm-worker.log,感谢。
还需要提供一些信息,报错主键冲突的位置如下,Error 1062: Duplicate entry ’ com.tencent.tmgp.* ’ for key ‘PRIMARY’\
1.利用 [tidb API ](https://github.com/pingcap/tidb/blob/master/docs/tidb_ht
tp_api.md)查看主键冲突的行的 mvcc 版本,以此来确认该行数据插入数据库的时间
#主键为 int 类型,使用如下语法
#主键为非整数类型
select _tidb_rowid from xxx where market_key=‘com.tencent.tmgp.*’;
curl http://{TiDBIP}:10080/mvcc/key/{db}/{table}/{_tidb_rowid}
查看已存在的数据写入数据库的时间
另外看了下 task 配置,没有分库分表合并,只是简单的同步上游数据到下游数据库中,上游不存在主键冲突的情况下,怀疑数据之前就已经写入到 tidb 集群中了,可以先按照上述方式反馈下数据写入 tidb 集群的时间。
1.查询mvcc版本
select _tidb_rowid from table_schema.table_name where market_key=’ com.tencent.tmgp.* ';
1
[tidb@hzxs-tidb-4121 ~]$ curl http://172.18.41.17:10080/mvcc/key/table_schema/table_name/1
{
“key”: “7480000000000004475F728000000000000001”,
“region_id”: 4585,
“value”: {
“info”: {
“writes”: [
{
“start_ts”: 419380851732905992,
“commit_ts”: 419380851746013185,
“short_value”: “gAADAAAAAQIDBgAaABsA6IW+6K6vIGNvbS50ZW5jZW50LnRtZ3AuKiAB”
}
]
}
}
2.tso转换为时间:
[tidb@hzxs-tidb-4121 tidb]$ tiup ctl pd -u http://172.18.41.17:10080 tso 419380851746013185
Starting component ctl: /home/tidb/.tiup/components/ctl/v4.0.5/ctl pd -u http://172.18.41.17:10080 tso 419380851746013185
system: 2020-09-11 15:56:28.411 +0800 CST
logic: 1
这里看到是 9.11号就入库了,是第一次启动任务时导入的,第一次启动任务时也报主键冲突,然后当时重启了任务,报了上面这个新的主键冲突,刚看了下官方文档,每次重启不记录checkpoint,这个冲突似乎存在的
但是dm一直用的是新版本DM 2.0.0-rc2,在第一次启动任务之前,数据都是没有的,也报主键冲突,这是比较困惑的地方。
你好,上面报错主键冲突的原因是因为数据已经存在下游中了。
至于你这边说,第一次启动任务,数据不存在时,也报错主键冲突,这个可以复现么 ? 你这边可以清空下游数据以及 checkpoint 信息后,重新进行增量和全量的同步。如果能复现问题,可以再提供日志给我们看下。
另外上面提到 dump 时即从上游 dump 数据时,是不会记录 checkpoint 信息的,但是 load 到下游时,会有 checkpoint 信息记录的。
了解了解,这样的话就好理解了,这边正在重试,看看能否复现,还有个小疑问,如果重启task的话都会做一次全量吗?如果是全量已经完成,在增量实时同步的任务,应该是checkpoint机制保障增量断点同步的吧
DM 是有三个阶段的,dump 阶段导出上游数据,load 阶段将全量数据导入到下游中。sync 阶段增量同步下游数据。
其中 dump 阶段是不记录 checkpoint 信息,load 和 sync 阶段都是记录 checkpoint 位点的。
也就是说,如果是在 dump 阶段重启了 task,那么会重新进行 dump 操作;如果是在 load 或者 sync 阶段,重启 task 的话,再次启动时会根据 checkpoint 中的断点信息,继续同步。
当然如果因为误操作或者是其他原因导致 checkpoint 信息被删除的话,那是会重新同步数据的。是由 checkpoint 机制来保障断点续传的。
checkpoint 位点可以在下游 dm_meta(默认库名)中查看到。
![]() 清晰明了,感谢感谢
清晰明了,感谢感谢
这边在load阶段,数据量有点大,需要点时间,目前没有报错,继续观察
好的,如果再发现有主键冲突的情况,辛苦提供下 dm-worker.log 日志,以及按照上面方式拿一下写入数据的 mvcc 版本。我们进一步排查一下,辛苦。![]()
好的,没问题,感谢如此及时帮忙查看解决,后续有问题还要向你们请教~
![]()
由于同一个项目,借此旧贴继续请教
1.速度偏慢
导出数据:2小时 600G
导入速度:600G数据9.15 11点至今3天多进度320G,50%
看了官方优化,DM配置优化,导入主要为 pool-size参数,当前设置为1,如果加大参数,会对服务器造成很大压力
2.报错
{ "result": true, "msg": "", "sources": [ { "result": true, "msg": "", "sourceStatus": { "source": "4303-replica-01", "worker": "dm-172.18.41.14-8262", "result": null, "relayStatus": null }, "subTaskStatus": [ { "name": "dm-bi-4303", "stage": "Running", "unit": "Load", "result": null, "unresolvedDDLLockID": "", "load": { "finishedBytes": "326922452194", "totalBytes": "300626473511", "progress": "108.75 %", "metaBinlog": "(mysql4303-bin.003539, 923417931)" } } ] } ] }
状态中 totalBytes原来是 619337004993,导致progress>100%,查看日志:
发现有报错,自动close,并重启任务。
麻烦帮忙看看,thx
看起来是被取消了,麻烦确认一下操作步骤,数据量是否太大了。我建议你重新开帖,我们在新的问题帖子里面反馈你吧。感谢啦~
好的,多谢
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。