- 【TiDB 版本】:v4.0.1
- 【问题描述】: 使用dm同步mysql数据,消费较慢。binlog 延迟较多
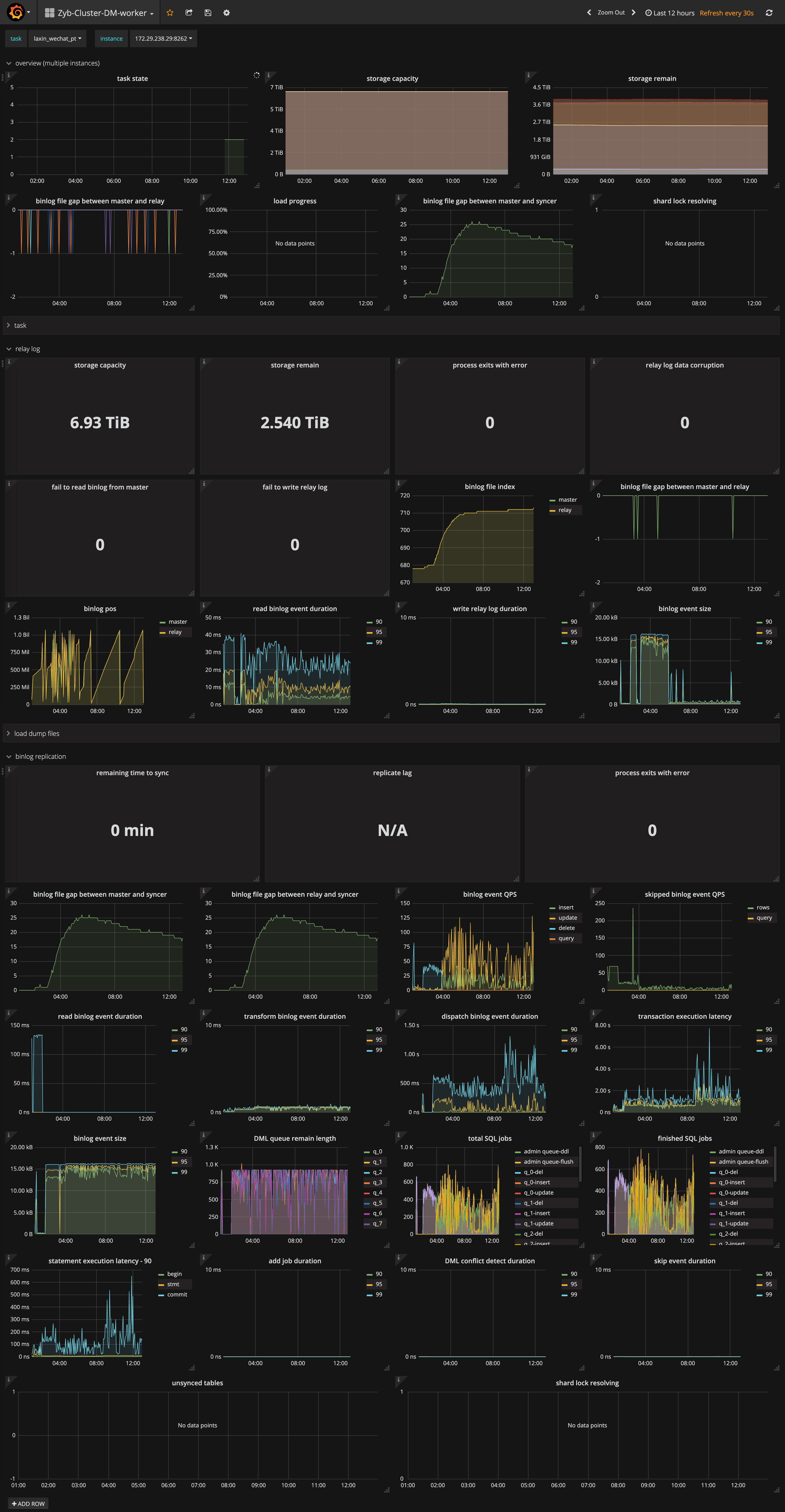
dm 监控状态
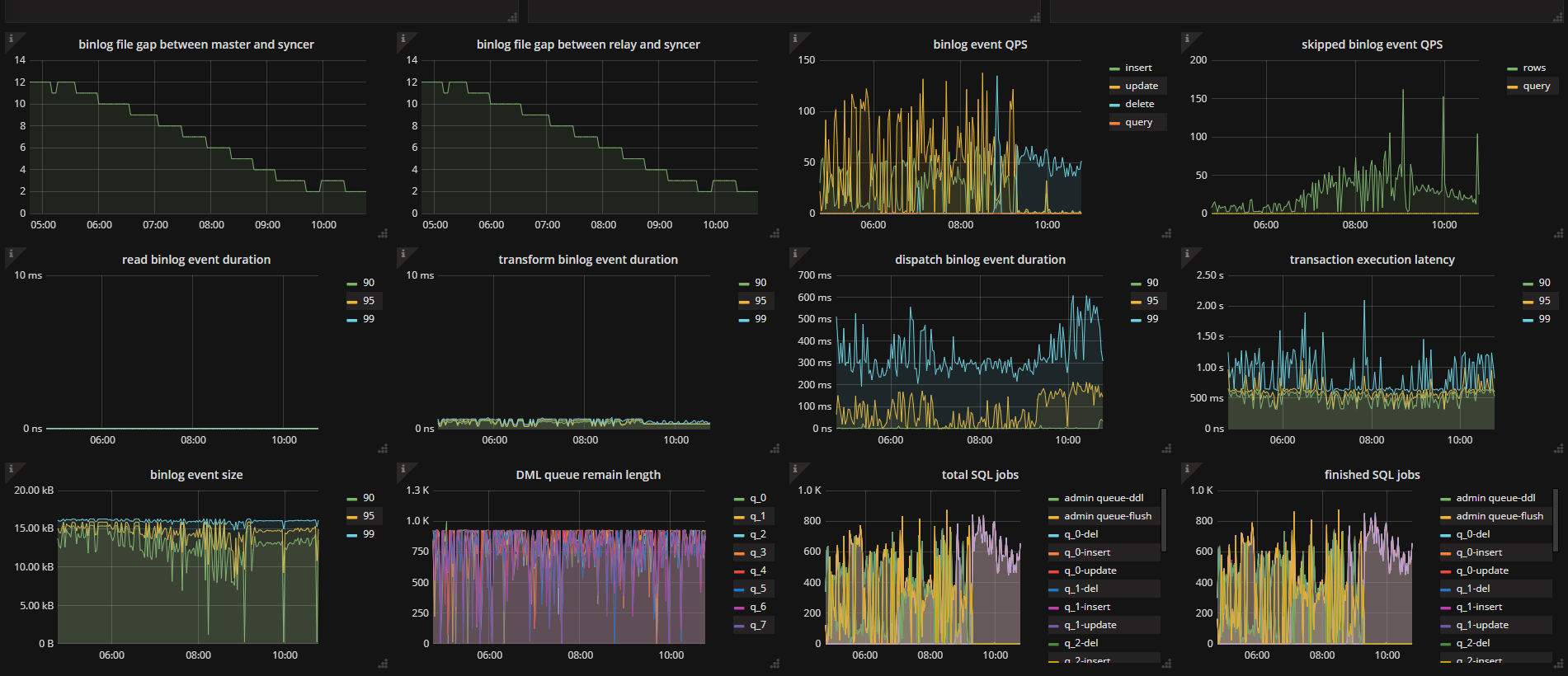
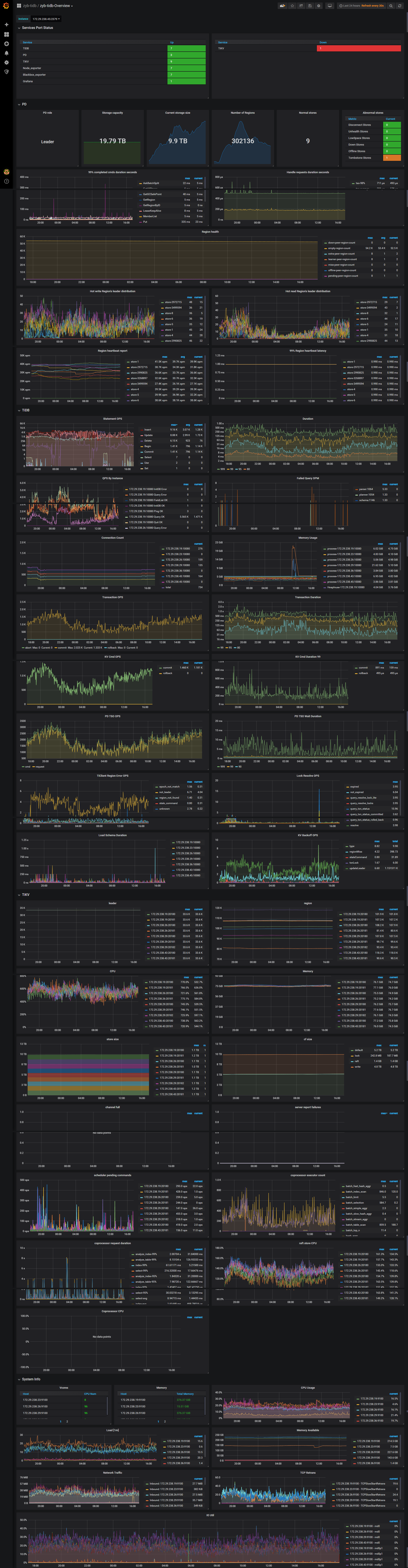
tidb 基本状态:

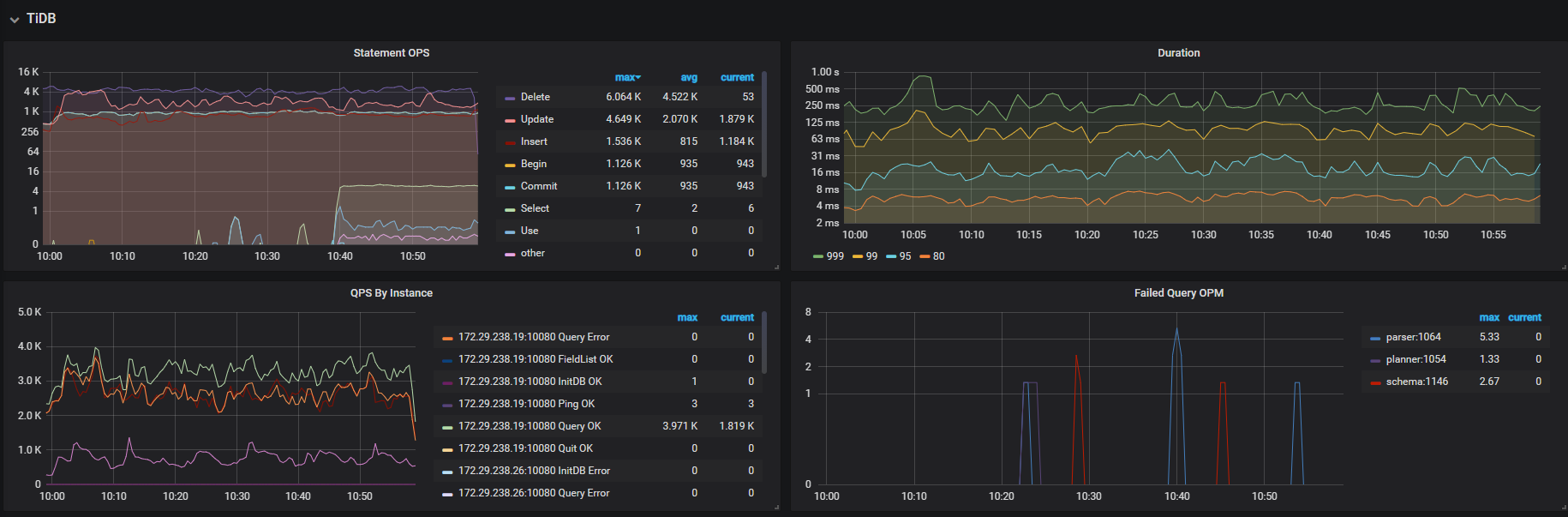
tidb 热点读 & 热点写的 监控

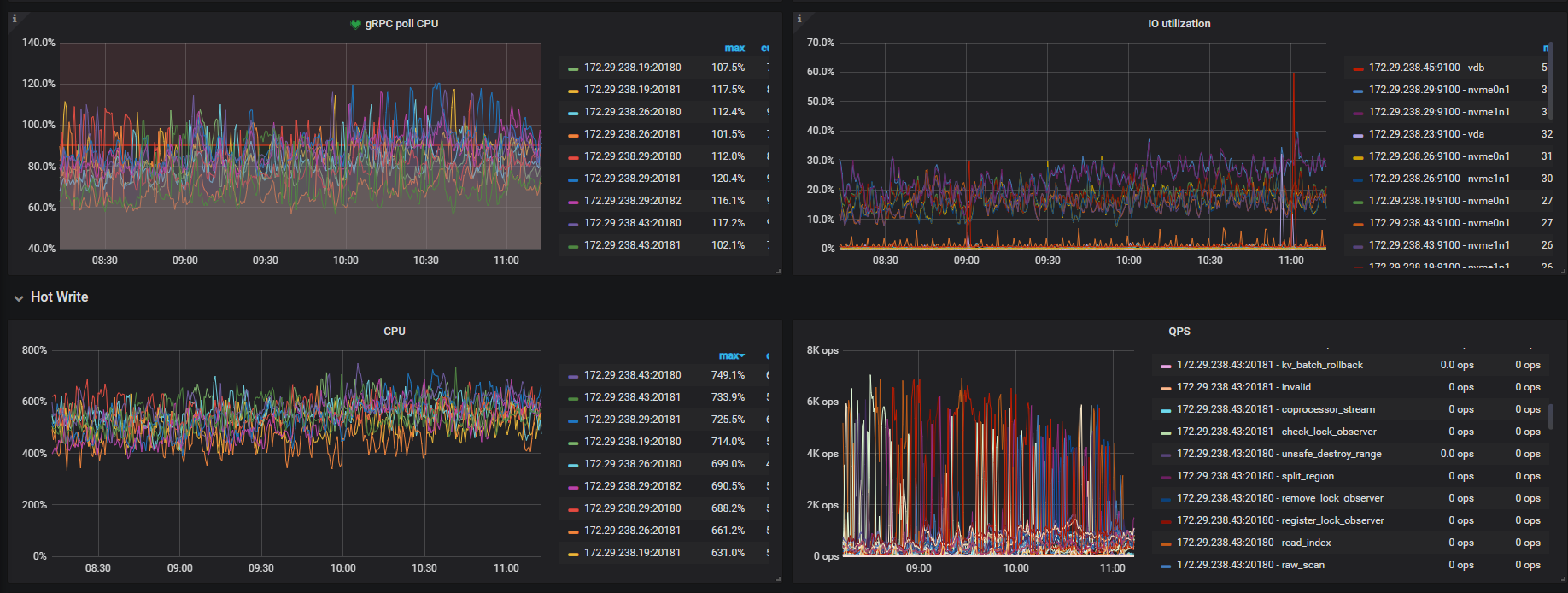

热点写监控表
以上信息是不是可以判定就是表的热点写造成的消费慢?
请问有什么最佳实践的解决办法么 ?
tidb 基本状态:
tidb 热点读 & 热点写的 监控
热点写监控表
以上信息是不是可以判定就是表的热点写造成的消费慢?
请问有什么最佳实践的解决办法么 ?
看下 task 文件配置。辛苦上传下。
dm 版本提供下
使用以下方式,提供下 overview 面板完整截图。我们看下。
打开 grafana 监控,先按 d 再按 shift+e 可以打开所有监控项。
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
name: laxin_wechat_pt # global unique
task-mode: all # full/incremental/all
is-sharding: false # whether multi dm-worker do one sharding job
meta-schema: “dm_meta” # meta schema in downstreaming database to store meta informaton of dm
remove-meta: false # remove meta from downstreaming database, now we delete checkpoint and online ddl information
enable-heartbeat: false # whether to enable heartbeat for calculating lag between master and syncer
case-sensitive: true
target-database:
host: “172.29.xxx”
port: xxxxx
user: “dm_worker”
password: “xxxxxxxxxxxx=”
session:
sql_mode: “NO_ENGINE_SUBSTITUTION”
source-id: "laxin_wechat_pt"
black-white-list: "bw-rule-laxin_wechat_pt"
mydumper-config-name: "global" # ref `mydumpers` config
syncer-config-name: "global" # ref `syncers` config
loader:
pool-size: 4
dir: "/data/dm_worker1/dumped_data"
black-white-list:
bw-rule-laxin_wechat_pt:
do-dbs: []
ignore-dbs: [“mysql”,“sys”,“information_schema”,“performance_schema”,“proxy_heart_beat”,“tmp”]
mydumpers:
global:
mydumper-path: “/home/tidb/tidb-tools/bin/mydumper”
threads: 8
chunk-filesize: 64
skip-tz-utc: true
extra-args: “–regex .*”
syncers:
global:
worker-count: 16
batch: 100
Hello~ 从 TiDB 的监控延迟看,TiDB 并没有很慢。所以建议尝试开大并发,将 worker-count 调大到 32 ,再看一下同步速度。目前 TiDB 可以支撑更大的并发同步。
调整了,并没啥变化。昨晚又延迟了挺多binlog
binlog 中是对某一批表进行更新和插入,dm-worker.log 中显示这些更新时间都在1秒多 。[“cost time”=1.017521833s]
asktug 搜索下 region merge 合并下空 region
看下 dn worker 服务器,压力如何,关注 cpu memory disk io util
worker count 调整到 64
已经将worker count 调整到64, 效果还可以。但是在load 其他实例数据的时候,上述实例还是会偶尔延迟两三个binlog 。
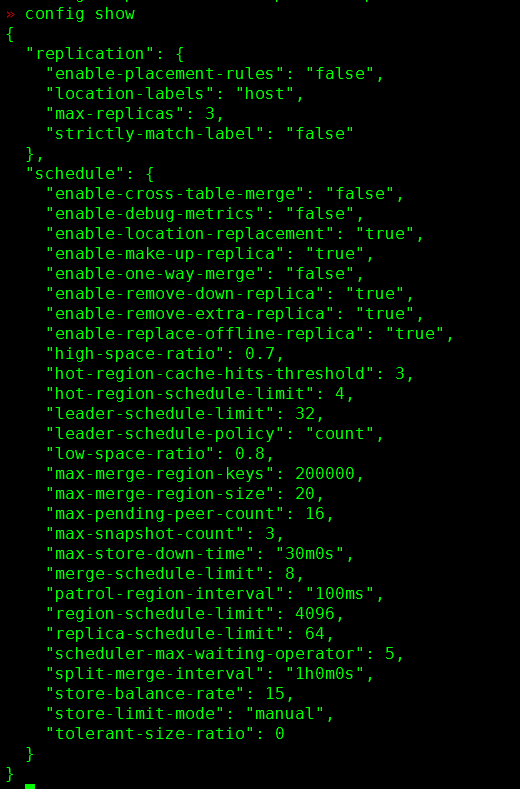
region merge 已经调整了 split-region-on-table & enable-cross-table-merge 并reload 了。tiup cluster reload zyb-tidb -R pd
但是但是region 并没有合并 并且 pdctl 查看到的好像并未生效
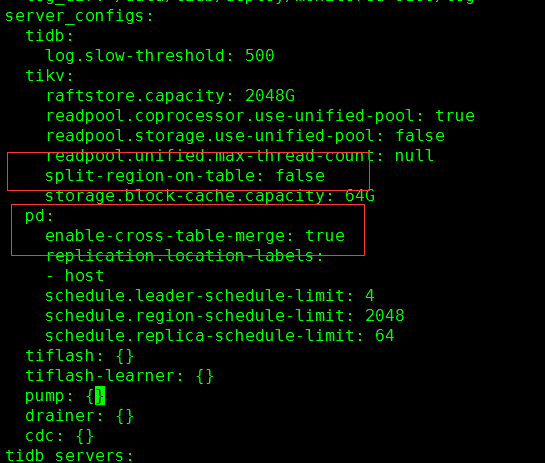
将参数回复到默认值吧,
region merge 调整如下参数即可
pd-ctl config set max-merge-region-size 20 # 默认
pd-ctl config set max-merge-region-keys 200000 # 默认
pd-ctl config set merge-schedule-limit 8 # 默认,主要参数!根据业务情况调整到 32 64 128 等
namespace-classifier = “default”
split-region-on-table,默认值为 true,
这需要看下 服务器是否是瓶颈了,资源情况如何。tidb 是否有写入瓶颈,压力如何,如果没有压力。可以在调整的大一点。
目前基本定位为写入热点问题,有一个实例持续的写入。
热点表结构为:
CREATE TABLE tblInnerStat_old (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘主键id’,
uid varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户id’,
user_phone varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户手机号’,
batch_name varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘批次’,
grade varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘年级’,
subject varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘学科’,
leads_type varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘例子类型’,
task_type varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘任务类型’,
leads_create_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘例子创建时间’,
user_get_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户接通电话时间’,
call_id varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘外呼id’,
user_wechat_name varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户微信昵称’,
zyb_wxid varchar(40) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘个人号wxid’,
user_wxid varchar(40) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户wxid’,
small_head varchar(512) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户头像’,
search_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘搜索时间’,
search_status varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘搜索状态’,
search_callback_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘搜索回调时间’,
search_callback_status varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘搜索回调状态’,
apply_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘申请好友时间’,
apply_status varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘申请好友状态’,
apply_callback_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘申请好友回调时间’,
apply_callback_status varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘申请好友回调状态’,
add_wechat_time varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户通过时间’,
add_wechat_status varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户通过状态’,
add_wechat_type varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户添加类型’,
is_ingroup varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户是否进群’,
ingroup_time varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘用户进群时间’,
create_time varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’ COMMENT ‘创建时间’,
PRIMARY KEY (id),
KEY UID_INDEX (uid),
KEY USER_PHONE_INDEX (user_phone),
KEY BATCH_NAME_INDEX (batch_name),
KEY LEADS_CREATE_TIME_INDEX (leads_create_time),
KEY CALL_ID_INDEX (call_id),
KEY search_status_index (search_status),
KEY add_wechat_status_index (add_wechat_status),
KEY add_wechat_type_index (add_wechat_type),
KEY is_ingroup_index (is_ingroup)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci AUTO_INCREMENT=270009 COMMENT=‘端内全流程数据统计表’
消费上游的binlog 为以主键id 为where 条件的update 语句。
请问如何设计表的主键能解决这种热点问题,请给一些最佳实践参考谢谢。
有的,官方网站有热点问题的处理办法
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理
另外我们有一个 《TiDB-in-Action》 也有热点处理问题的最佳实践
https://book.tidb.io/session4/chapter7/hotspot-resolved.html
如果这张表不适合重建,没有业务停机窗口。可以考虑先用 alter table split region 方式,将热点的 region 进行 split 拆分,然后通过 pd-ctl 将 region schedule 其他的节点。
Hi,看了文档的描述,有几点疑惑:
1.之前主键是int 类型且自增,如果我改成vachar 的类型。是不是数据就不会按照主键顺序存储在一个region 上?
2.但是看文档上描述,非int 类型的主键插入的话还是按照隐式主键顺序写入,可能还是会造成写入热点。
这样我设置成varchar 类型好像从上游mysql 自增插入的数据,到tidb这里还是会按照隐式rowid 形成写入热点。
这样理解正确么??
3.所以这个主键到底该怎么设置:使用int 类型,然后用SHARD_ROW_ID_BITS 进行处理分散写入热点 ??
您好 在 TiDB 中 如果需要使用 shard_row_id_bits 特性,缓解热点问题。
前提条件是 不能使用 int 类型的 主键。
t{tbid}_r{rowid}:row value 为行数据 的 KV 映射存储形象
1.使用 int\bigint 类型主键 主键ID将作为 ROWID ,故会产生热点
2.使用 varchar 类型主键,rowid 将由 tidb 隐式产生,依然是单调递增的,故会产生热点
3.使用了varchar 类型主键+shard_row_id_bits 将把 rowid 打散写入多个不同的 Region,但如果索引是单调递增的,索引存储时依然会有热点
问题 1.如果使用 varchar 类型主键,primary key 与 真实的行数据是分开存在不同的 column faimily中,所以数据的存储关系与 insert 顺序有关(未设置 shard_row_id_bits)
问题 2.如果不设置 shard_row_id_bits 会有热点
问题 3.使用 varchar 类型主键,设置 shard_row_id_bits + pre_split_regions 推荐设置 shard_row_id_bits = 4 pre_split_regions=2
create table t (a int, b int,index idx1(a)) shard_row_id_bits = 4 pre_split_regions=2;
ps.如果业务对主键无依赖,可以使用 4.0 中的新特性 AUTO_RANDOM
https://docs.pingcap.com/zh/tidb/stable/auto-random
ok,感谢回复。
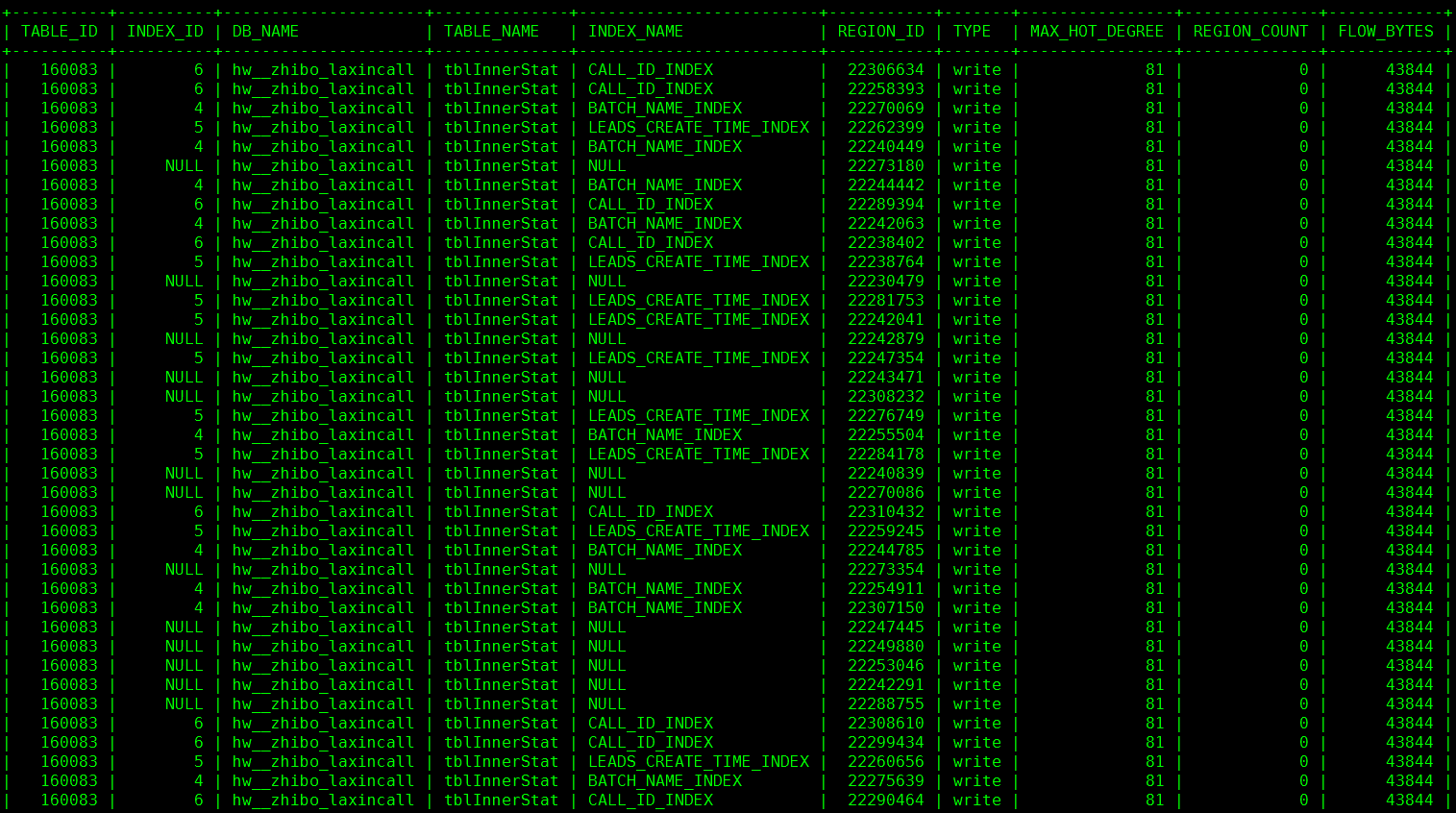
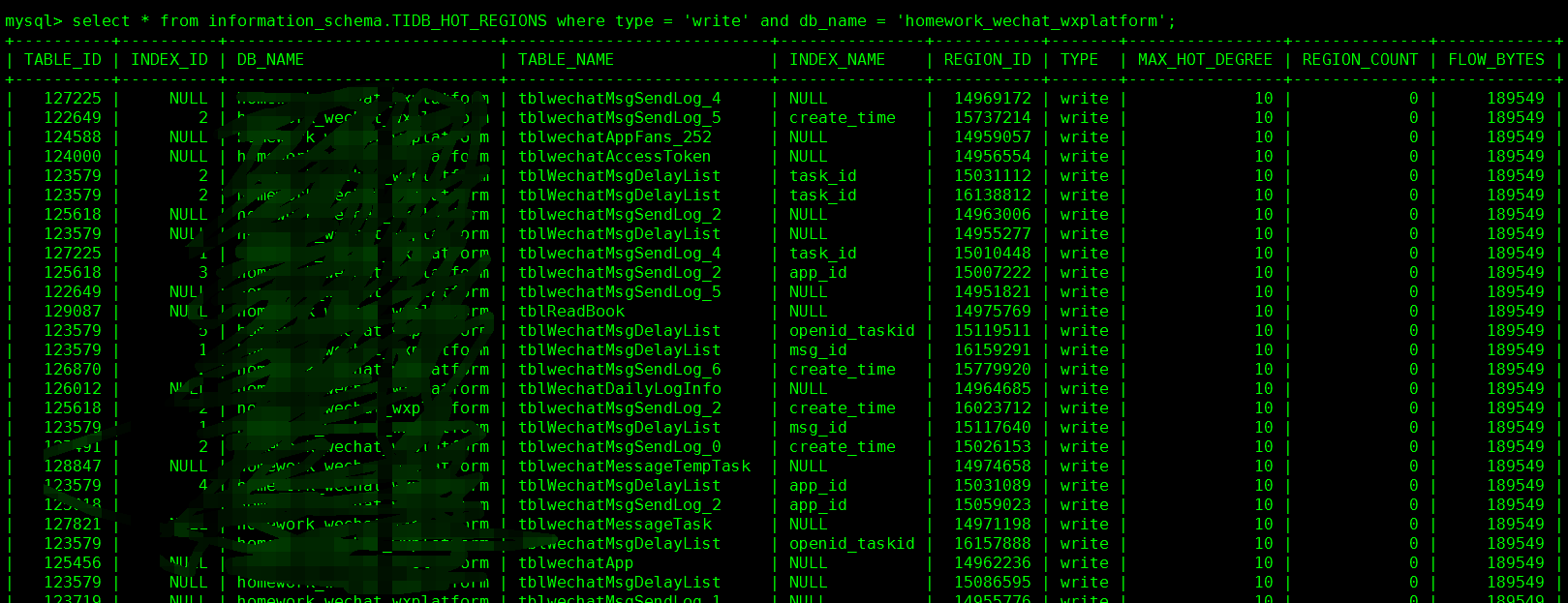
我已经将表结构修改了,使用的varchar 类型作为主键 + shard_row_id_bits = 6. 。运行了一下午,目前通过查询
select * from information_schema.TIDB_HOT_REGIONS where type = ‘write’ and table_name != ‘stats_histograms’ and db_name != ‘heartbeat’ ;
依然有挺多热点写
show table xxxx regions —> 已经分裂到364,目测region数还在继续增加。
再继续观察一天看看是否会有改善。
如果有进展,麻烦反馈一下。![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。