用spark-sql直接跑没什么问题, 用pyspark跑不出来,这是tispark配置有什么地方不对吗
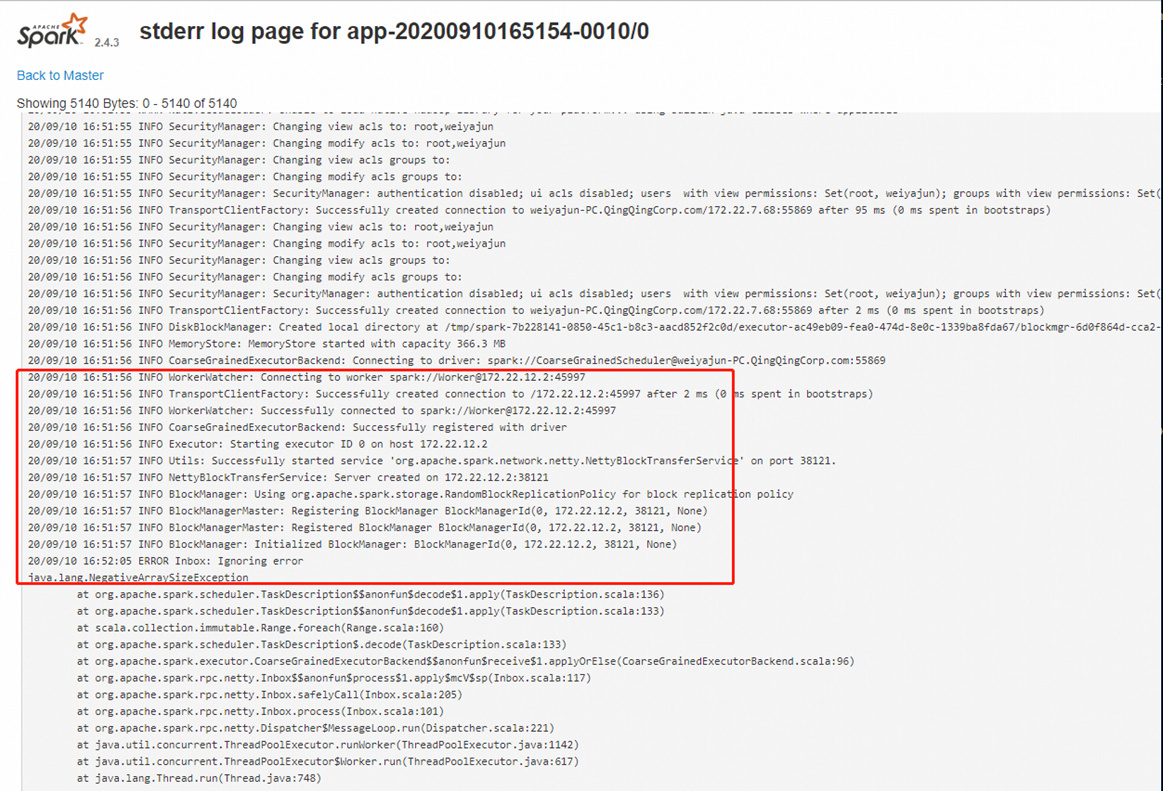
看这个报错java.lang.NegativeArraySizeException 看着是应用程序试图创建大小为负的数组,则抛出该异常。
1 个赞
为什么拿不到db信息呢?
[root@~ bin]# ./pyspark --jars /srv/nodes/ssd/1/tidb/spark/jars/tispark-assembly-SNAPSHOT.jar
Python 3.7.3 (default, Sep 10 2020, 17:56:18)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
20/09/11 15:14:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Setting default log level to “WARN”.
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ / ___ / /
\ / _ / _ `/ __/ '/
/ / ._/_,// //_\ version 2.4.3
//
Using Python version 3.7.3 (default, Sep 10 2020 17:56:18)
SparkSession available as ‘spark’.
spark.sql(“show databases”).show()
±-----------+
|databaseName|
±-----------+
| default|
±-----------+
您好,能否提供一下完整的报错信息以及 TiSpark 版本信息?可以通过 spark.sql("select ti_version()").show(false) 获得
另外,请确认一下是否使用了 pytispark 进行连接:
spark.sql(“select ti_version()”).show(false)
Traceback (most recent call last):
File “/srv/nodes/ssd/1/tidb/spark/python/pyspark/sql/utils.py”, line 63, in deco
return f(*a, **kw)
File “/srv/nodes/ssd/1/tidb/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py”, line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o39.sql.
: org.apache.spark.sql.AnalysisException: Undefined function: ‘ti_version’. This function is neither a registered temporary function nor a permanent function registered in the database ‘default’.; line 1 pos 7
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$15$$anonfun$applyOrElse$49.apply(Analyzer.scala:1281)
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$15$$anonfun$applyOrElse$49.apply(Analyzer.scala:1281)
at org.apache.spark.sql.catalyst.analysis.package$.withPosition(package.scala:53)
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$15.applyOrElse(Analyzer.scala:1280)
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$15.applyOrElse(Analyzer.scala:1272)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:256)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:256)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:255)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:261)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:261)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:326)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:324)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:261)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$transformExpressionsDown$1.apply(QueryPlan.scala:83)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$transformExpressionsDown$1.apply(QueryPlan.scala:83)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$1.apply(QueryPlan.scala:105)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$1.apply(QueryPlan.scala:105)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:104)
at org.apache.spark.sql.catalyst.plans.QueryPlan.org$apache$spark$sql$catalyst$plans$QueryPlan$$recursiveTransform$1(QueryPlan.scala:116)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$org$apache$spark$sql$catalyst$plans$QueryPlan$$recursiveTransform$1$2.apply(QueryPlan.scala:121)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.immutable.List.map(List.scala:296)
at org.apache.spark.sql.catalyst.plans.QueryPlan.org$apache$spark$sql$catalyst$plans$QueryPlan$$recursiveTransform$1(QueryPlan.scala:121)
at org.apache.spark.sql.catalyst.plans.QueryPlan$$anonfun$2.apply(QueryPlan.scala:126)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:126)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsDown(QueryPlan.scala:83)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressions(QueryPlan.scala:74)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressions$1.applyOrElse(AnalysisHelper.scala:129)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressions$1.applyOrElse(AnalysisHelper.scala:128)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1$$anonfun$2.apply(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1$$anonfun$2.apply(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1.apply(AnalysisHelper.scala:107)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1.apply(AnalysisHelper.scala:106)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsDown(AnalysisHelper.scala:106)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDown(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperators(AnalysisHelper.scala:73)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperators(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveExpressions(AnalysisHelper.scala:128)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveExpressions(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:1272)
at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:1269)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57)
at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66)
at scala.collection.mutable.WrappedArray.foldLeft(WrappedArray.scala:35)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:127)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:121)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:106)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “”, line 1, in
File “/srv/nodes/ssd/1/tidb/spark/python/pyspark/sql/session.py”, line 767, in sql
return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)
File “/srv/nodes/ssd/1/tidb/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py”, line 1257, in call
File “/srv/nodes/ssd/1/tidb/spark/python/pyspark/sql/utils.py”, line 69, in deco
raise AnalysisException(s.split(': ', 1)[1], stackTrace)
pyspark.sql.utils.AnalysisException: “Undefined function: ‘ti_version’. This function is neither a registered temporary function nor a permanent function registered in the database ‘default’.; line 1 pos 7”
可以了,谢谢
好的~