为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.4
- 【问题描述】:经过一段时间的使用,发现大量insert和update时,集群比较不稳定。之前发现使用慢tidb dashboard 的慢sql查询时会出现cpu过高的问题,现在发现服务层也有很多连接断开,sqoop同步失败等问题。
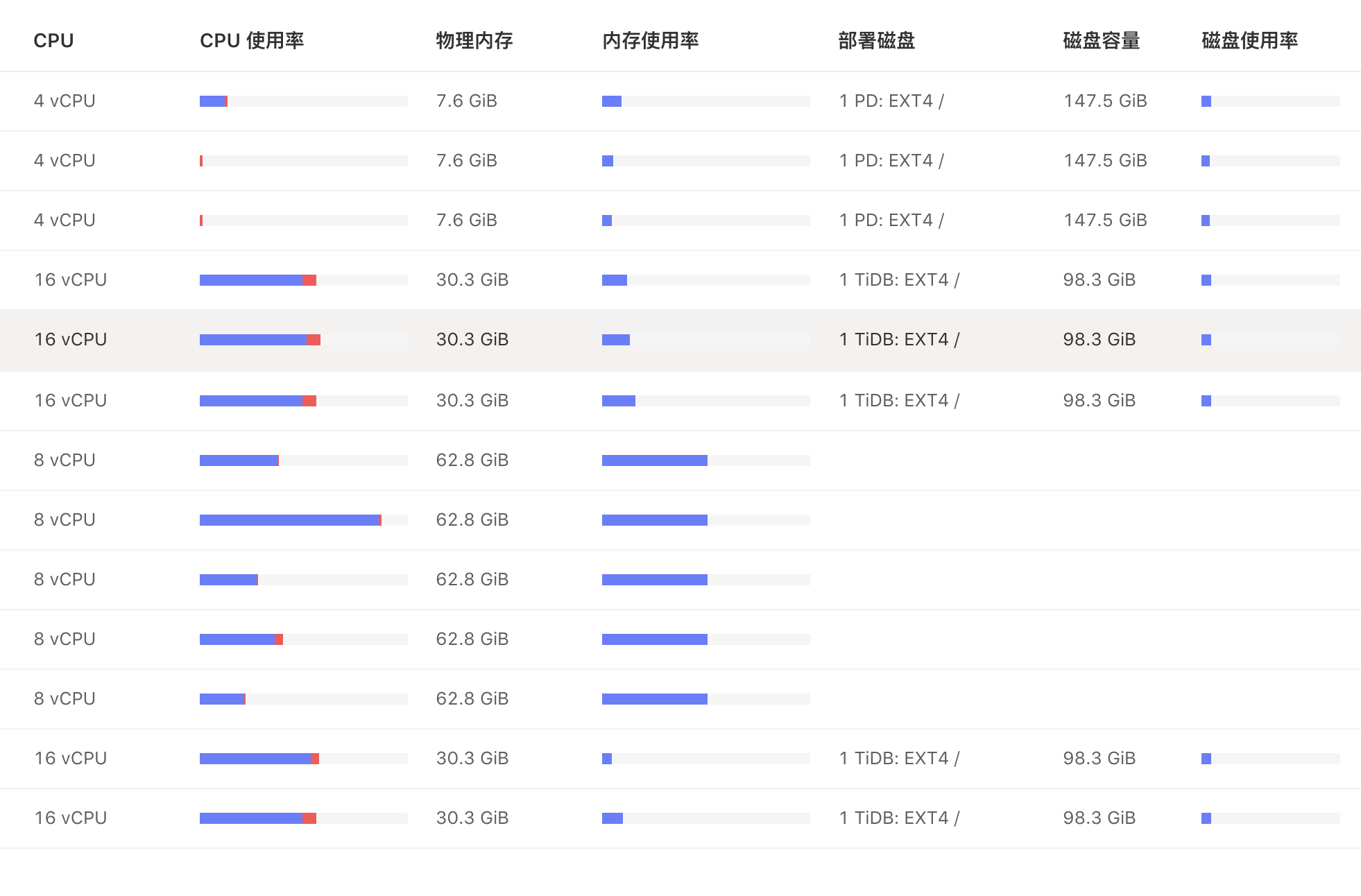
集群配置为:
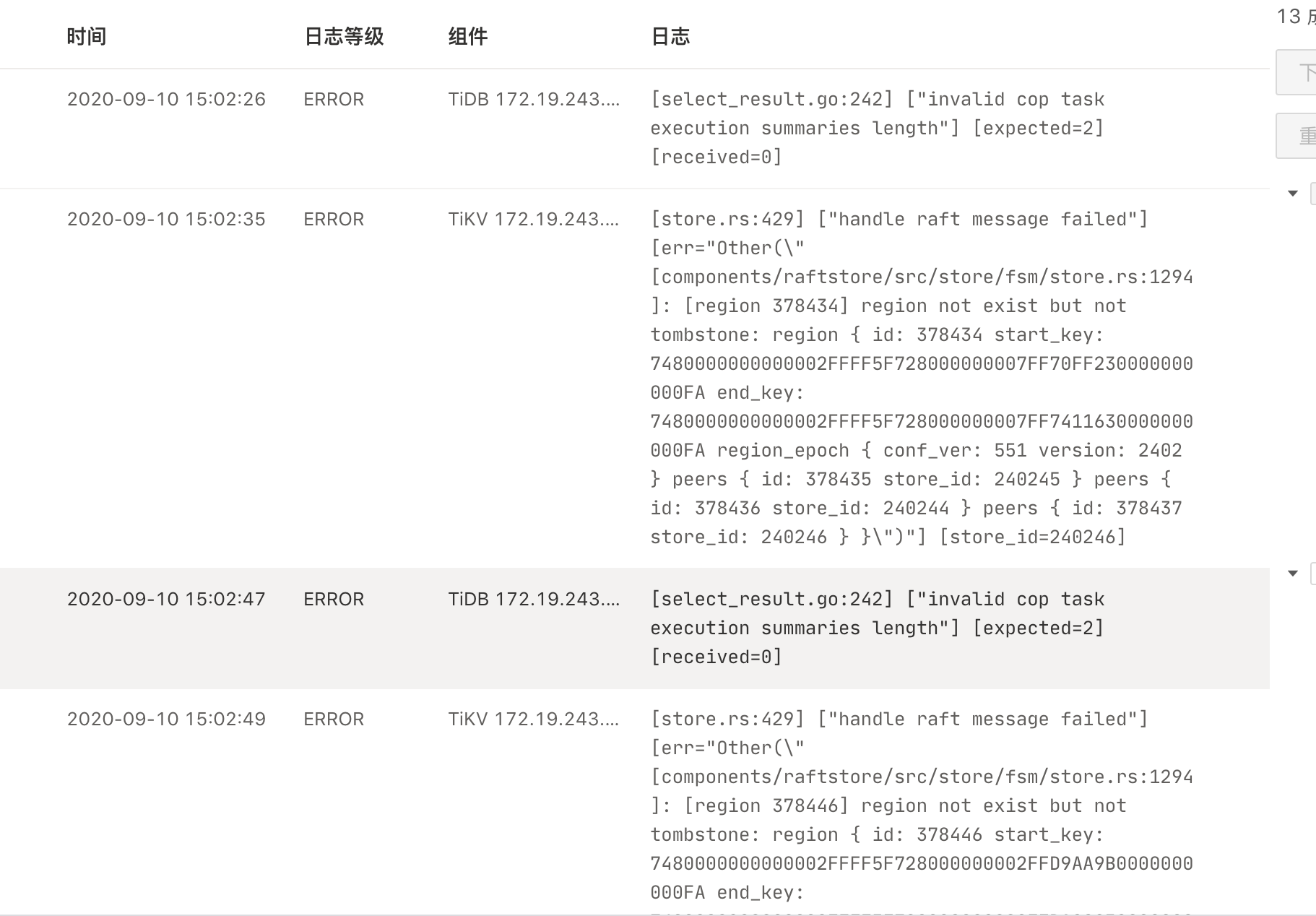
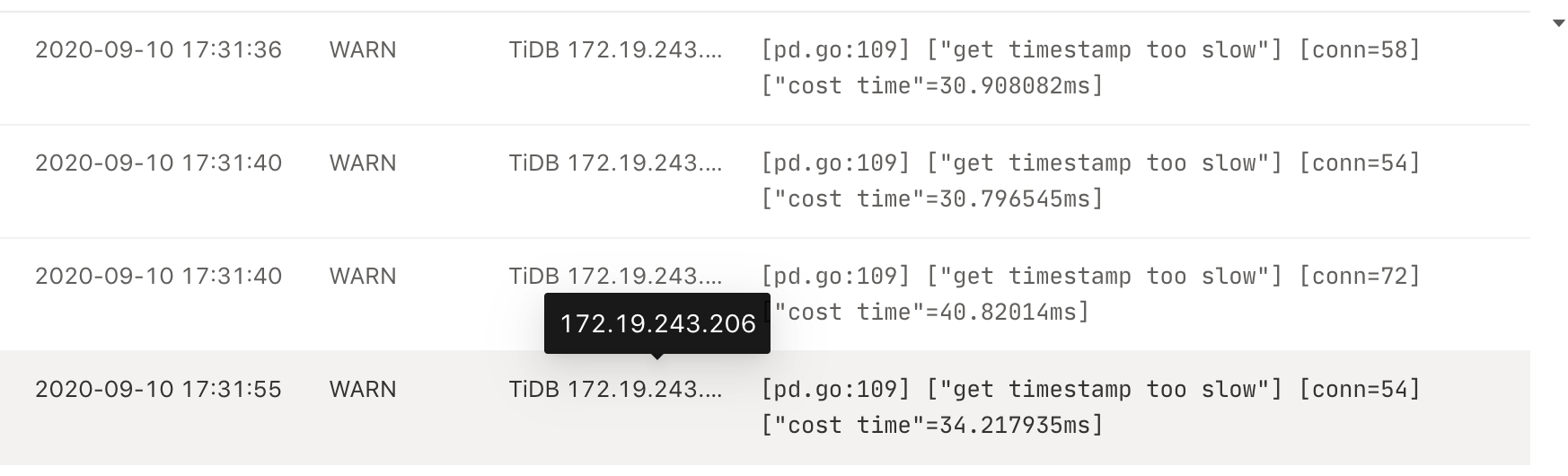
其中日志搜索可以看到有大量error信息:
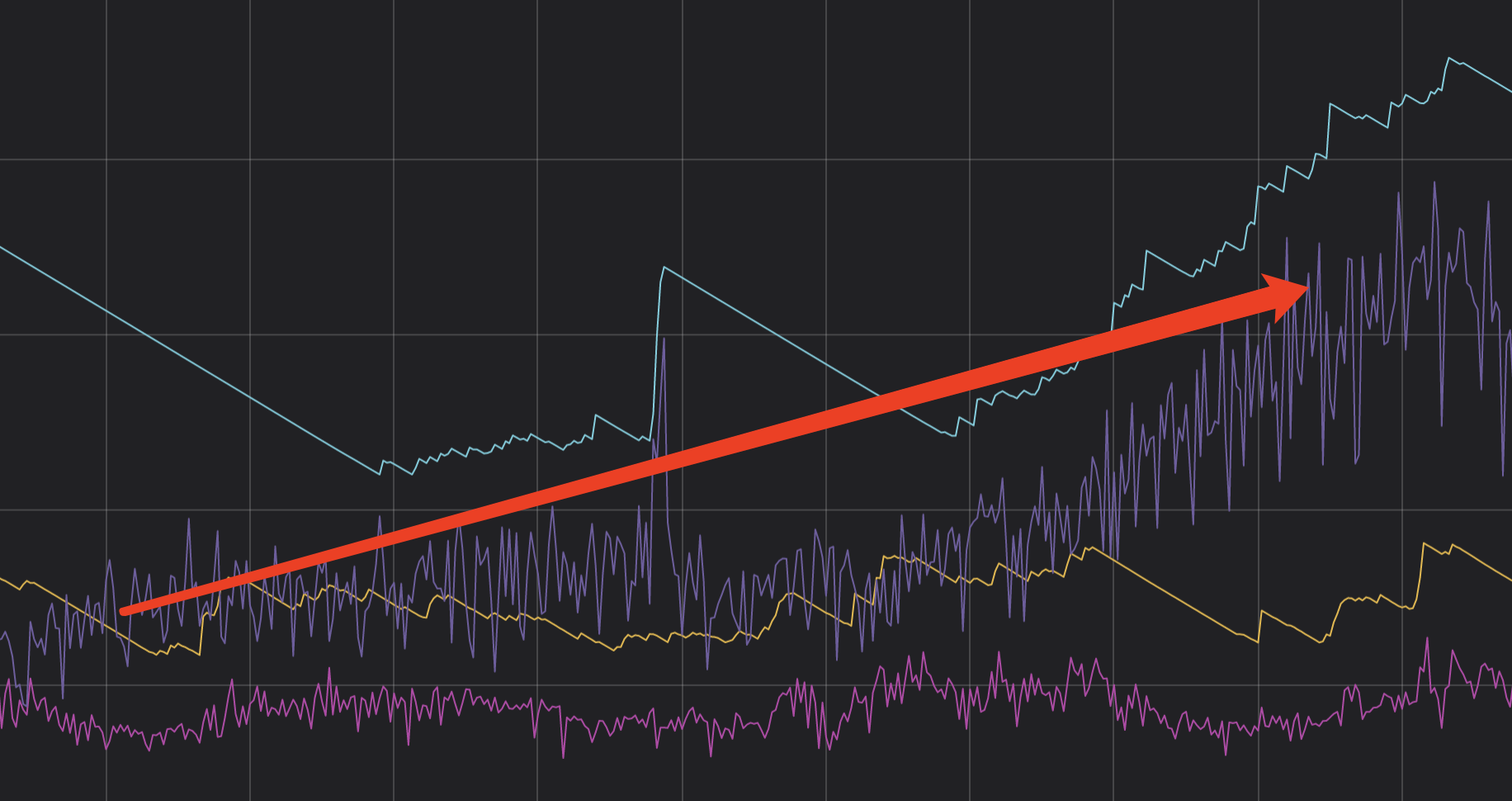
grafana显示tidb在down掉前,内存普遍波动比较大:
以这个tidb实例为例,这种情况下,tidb后续就会down掉,然后再被supervisor重新拉起,拉起后内存就恢复正常了。