Ares1201
2020 年9 月 4 日 03:12
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:2.1.5
【问题描述】:集群包含2个TiDB节点和1个TiPD节点,6个TIKV节点。下线2个TIKV节点时,数据迁移速度较慢,而且造成线上数据访问失败的问题。. ]: FAILED! => {“changed”: false, “cmd”: [“cat”, “/search/data/deploy/status/tikv.pid”], “delta”: “0:00:00.643338”, “end”: “2020-09-04 11:09:46.602947”, “msg”: “non-zero return code”, “rc”: 1, “start”: “2020-09-04 11:09:45.959609”, “stderr”: “cat: /search/data/deploy/status/tikv.pid: No such file or directory”, “stderr_lines”: [“cat: /search/data/deploy/status/tikv.pid: No such file or directory”], “stdout”: “”, “stdout_lines”: []}
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
sultan8252
2020 年9 月 4 日 03:29
2
您好 请您先检查下 TiDB 监控面板中 PD 监控中 cluster 监控类的
Abnormal stores:处于异常状态的节点数目,正常情况应当为 0
Region health:每个 Region 的状态,通常情况下,pending 的 peer 应该少于 100,miss 的 peer 不能一直大于 0http://$ {pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Up 如果已经删除了原节点数据文件,是会造成部分数据丢失的情况。
Ares1201
2020 年9 月 4 日 05:09
3
sultan8252:
Abnormal
pending current 是33.7k
Ares1201
2020 年9 月 4 日 05:22
5
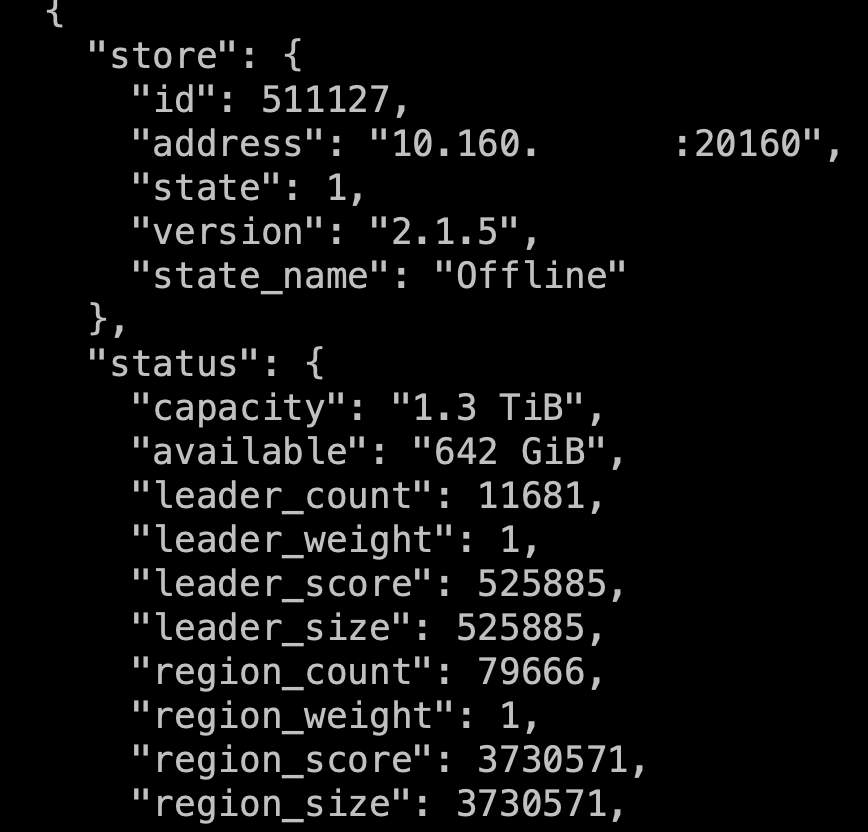
刚才使用命令查看store状态http://$ {pd_ip}:2379” -d store
发现511127还活着,使用你提供的UP命令,无法重新上线这个TIKV,命令返回null
Ares1201
2020 年9 月 4 日 05:37
6
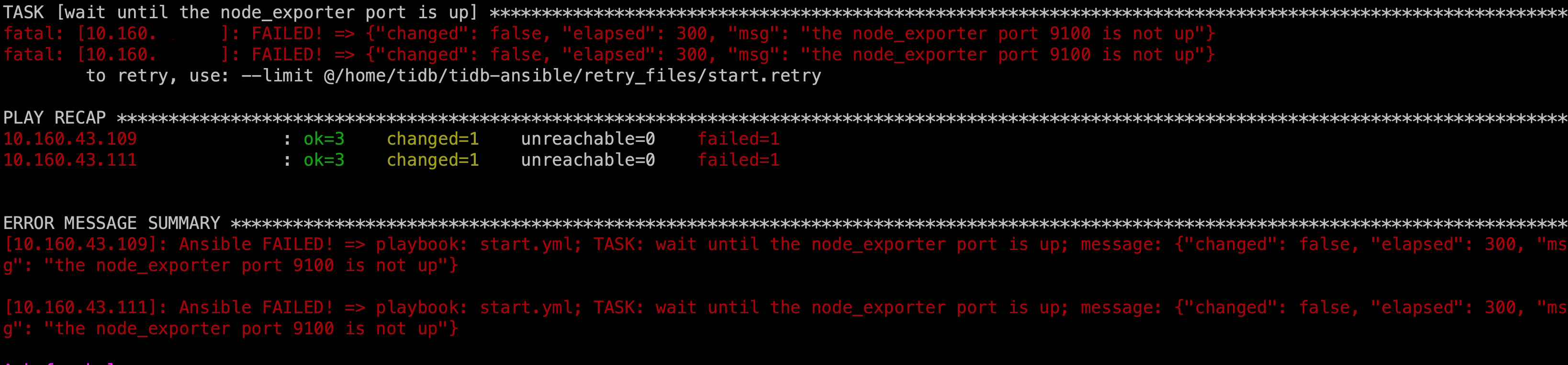
使用命令查看store状态,发现两台TIKV处于DOWN状态,使用 ansible-playbook start.yml -l ip1,ip2命令重启报错
Ares1201
2020 年9 月 4 日 06:00
7
sultan8252
2020 年9 月 4 日 06:27
8
从 您上传的图片看 PD 中记录的 Store 节点已经下线.
Region health:每个 Region 的状态,通常情况下,pending 的 peer 应该少于 100,miss 的 peer 不能一直大于 0
关于 ansiable 启动失败的报错只的是 node_exporter 组件启动失败,此组件为服务监控组件 .有可能是在之前的缩容过程中此服务以被清理导致启动失败.
Ares1201
2020 年9 月 4 日 07:20
9
下线的两个TIKV节点平均8w的region数目,目前处于DOWN状态,而且region_size不断在减少,但是速度很慢。我猜测是正在做region迁移。能否有办法终止这种region迁移,重新上线这两个TIKV?
Ares1201
2020 年9 月 4 日 07:24
10
node_exporter-9100.service loaded activating auto-restart node_exporter-9100 service
sultan8252
2020 年9 月 4 日 07:38
11
您好 首先需要您检查 您下线的 tikv 服务器的 tikv 相关服务是否已清理,如果服务依然存在可以手动将 服务拉起http://$ {pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Up 将 store 状态 手动修改为 UP 观察下后续情况.
sultan8252
2020 年9 月 4 日 07:41
12
这是 tidb 监控组件 ,tikv 节点拉起后 可以手动将此服务进行 restart
Ares1201
2020 年9 月 5 日 02:30
13
“您下线的 tikv 服务器的 tikv 相关服务是否已清理” 这个如何检查?如果清理了,该怎么重启。
这道题我不会
2020 年9 月 5 日 11:57
15
目前这两个 tikv 实例还是处于 offline 状态还是 tombstone 状态?如果是 offline 状态上面的 region_size 还在不断减少吗?
Ares1201
2020 年9 月 7 日 04:12
16
目前这俩个实例状态是DOWN,一直不变,而且size没有变少。在服务机上,tikv | node_export | blackbox_exporter 组件全部都被清理了。
Ares1201
2020 年9 月 7 日 07:35
18
首先是正常缩容(6-2=4),两个TIKV同时进入offline状态,结果发现速度太慢,打算暂停缩容,使用命令ansible-playbook stop.yml停止两台TIKV运行,发现命令执行失败。期间状态始终处于offline状态。根据TIDB技术支持的提示,在服务机器使用systemctl start 启停tikv | node_export | blackbox_exporter 组件,发现并没有启动,组件始终处于 activating auto-restart 状态。期间节点状态变化为DOWN。
Ares1201
2020 年9 月 7 日 07:45
19
tikv-ctl --db /path/to/tikv/db unsafe-recover remove-fail-stores -s 4,5 --all-regions
yilong
2020 年9 月 7 日 07:50
20
tikv-ctl 可以从中控机下 scp 到每个节点
参考这个文档
https://asktug.com/t/topic/36199