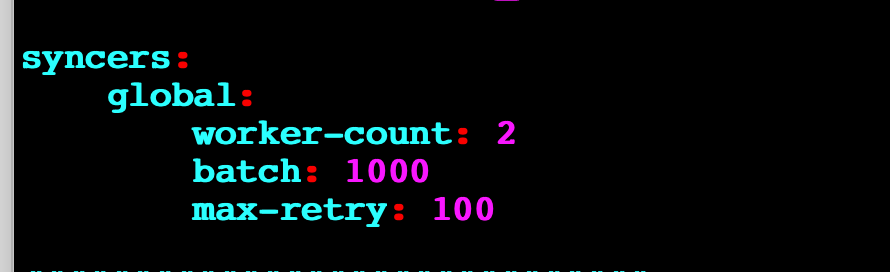
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.5, 从v4.0.2升级到v4.0.4再升级到v4.0.5
- 【问题描述】:
dm同步数据到tidb, 经常报Region is unavailable而无法同步, 报以下错误:
“errors”: [
{
“Type”: “ExecSQL”,
“msg”: “”,
“error”: {
“ErrCode”: 10006,
“ErrClass”: 1,
“ErrScope”: 0,
“ErrLevel”: 3,
“Message”: “execute statement failed: REPLACE INTOlepay5.t_operation_info_40(F_id,F_order_id,F_merchant_id,F_trade_type,F_operation_type,F_transaction_data,F_create_time,F_update_time,F_settle_amount) VALUES (?,?,?,?,?,?,?,?,?): Error 9005: Region is unavailable”,
“RawCause”: “Error 9005: Region is unavailable”
}
},
{
“Type”: “ExecSQL”,
“msg”: “”,
“error”: {
“ErrCode”: 10006,
“ErrClass”: 1,
“ErrScope”: 0,
“ErrLevel”: 3,
“Message”: “execute statement failed: begin: sql: connection is already closed”,
“RawCause”: “sql: connection is already closed”
}
},
tidb 错误日志:
[txn_mode=PESSIMISTIC] [err=“[tikv:9005]Region is unavailable
github.com/pingcap/errors.AddStack
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/errors.go:174
github.com/pingcap/errors.Trace
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/juju_adaptor.go:15
github.com/pingcap/tidb/store/tikv.(*RegionRequestSender).onRegionError
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/src/github.com/pingcap/tidb/store/tikv/region_request.go:465
github.com/pingcap/tidb/store/tikv.(*RegionRequestSender).SendReqCtx
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/src/github.com/pingcap/tidb/store/tikv/region_request.go:276
github.com/pingcap/tidb/store/tikv.(*clientHelper).SendReqCtx
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:879
github.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:256
github.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions.func3
\t/home/jenkins/agent/workspace/tidb_v4.0.5/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:217
runtime.goexit
\t/usr/local/go/src/runtime/asm_amd64.s:1357”]
tikv 日志: 发生错误期间,tikv没有error级别的日志, 连warn日志也没有
region health经常有少量的pending region:

倒是发现一个异常, store 0 的KV request duration很高,但实际找不到这个store 0, 不存在
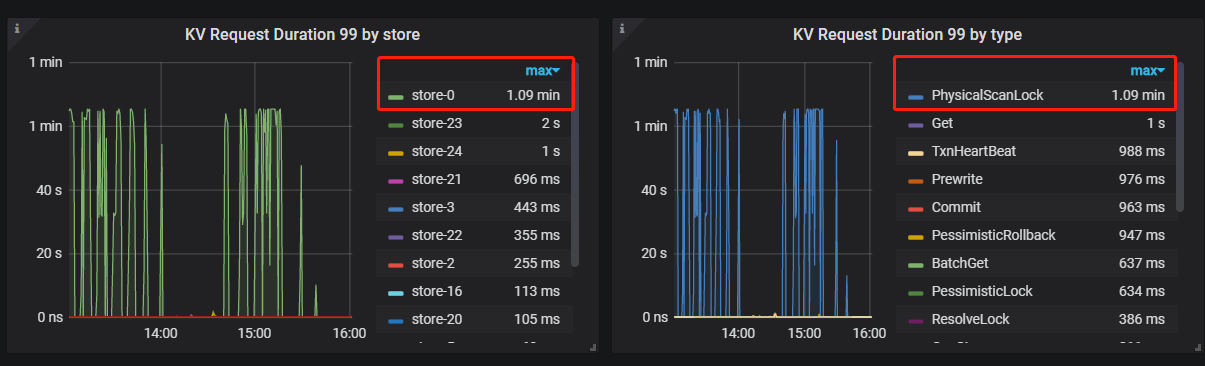
pd-ctl 找不到这个store 0